目标
- 抓取猫眼正在热映的电影页面的数据,使用的第三方模块 request、cheerio。
说明
- 有时候我们需要做一些项目或者demo,我们需要一些数据,我们就可以利用爬虫,爬取一些我们想要的数据。个人感觉挺有趣。需要安装 node。
request
- request是一个第三方的模块,封装了 http 模块,使我们发送 get、post等 请求更简洁。有几个重要的参数:
- url:请求的地址
- method:请求的方式
- function:回调函数,该函数也有三个参数:1、err 错误对象,2、response 响应对象,3、body 响应数据
- 安装
npm install request --save
//引入模块
const request = require('request')
//小试牛刀:向百度首页发送了一个get请求
const url = 'https://www.baidu.com/'
request(url, function (err, response, body) {
console.log(body)
})
cheerio
- 会用 jQuery,那么使用 cheerio就不会难了,cheerio 包括了 jQuery 核心的子集。cheerio 从jQuery库中去除了所有 DOM不一致性和浏览器尴尬的部分,几乎能够解析任何的 HTML 和 XML document,通过load方法传递 HTML document或者标签字符串的形式来加载返回 相应的对象,该对象可以对 HTML document或者标签进行操作。
- 安装
npm install request --save
const request = require('request')
const cheerio = require('cheerio')
//传递 HTML document
const url = 'https://www.baidu.com/'
request(url, function (err, response, body) {
//此时body即为 HTML documen
const $ = cheerio.load(body)
})
//传递标签字符串
const $ = cheerio.load('<div class="text">...</div>')
抓取数据
const request = require('request')
const cheerio = require('cheerio')
function getMovies(url) {
return new Promise((resolve, reject) => {
request(url, function (err, response, body) {
//获取HTML document对象 即body参数
const $ = cheerio.load(body)
})
})
}
- 猫眼热映电影页面图片
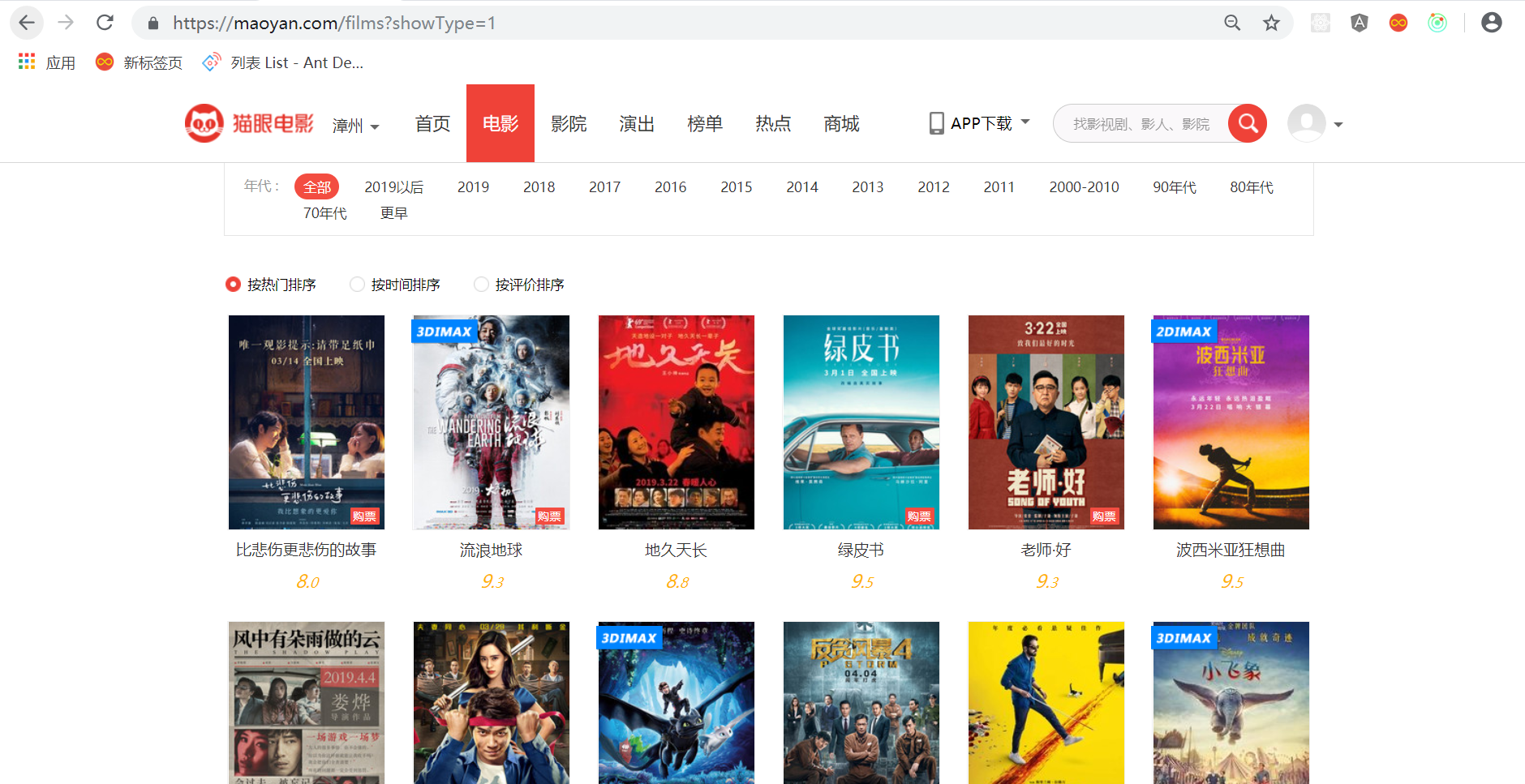
- HTML结构分析
- 通过分析 HTML的结构,可知道这些值可以通过下面的代码获取到
var item = $('.movie-list dd')
item.map(function (i, val) {
var movieObj = {}
//电影链接
movieObj.movieLink = $(val).find('.movie-poster').children('a').attr('href')
//电影图片
movieObj.moviePoster = $(val).find('.movie-item').children('img').last().attr('data-src')
//电影 名字
movieObj.movieTitle = $(val).find('.movie-item-title').children('a').text()
//电影评分
movieObj.movieDetail = $(val).find('.channel-detail-orange').text()
})

完整代码
const request = require('request')
const cheerio = require('cheerio')
function getMovies(url) {
var movieArr = []
return new Promise((resolve, reject) => {
request(url, function (err, response, body) {
var item = $('.movie-list dd')
item.map(function (i, val) {
var movieObj = {}
//电影链接
movieObj.movieLink = $(val).find('.movie-poster').children('a').attr('href')
//电影图片
movieObj.moviePoster = $(val).find('.movie-item').children('img').last().attr('data-src')
//电影 名字
movieObj.movieTitle = $(val).find('.movie-item-title').children('a').text()
//电影评分
movieObj.movieDetail = $(val).find('.channel-detail-orange').text()
//把抓取到的内容 放到数组里面去
movieArr.push(movieObj)
})
//说明 数据获取完毕
if (movieArr.length >0){
resolve(movieArr)
}
})
})
}
//获取正在热映电影数据
getMovies('https://maoyan.com/films?showType=1')
.then((data) => {
console.log(data)
})
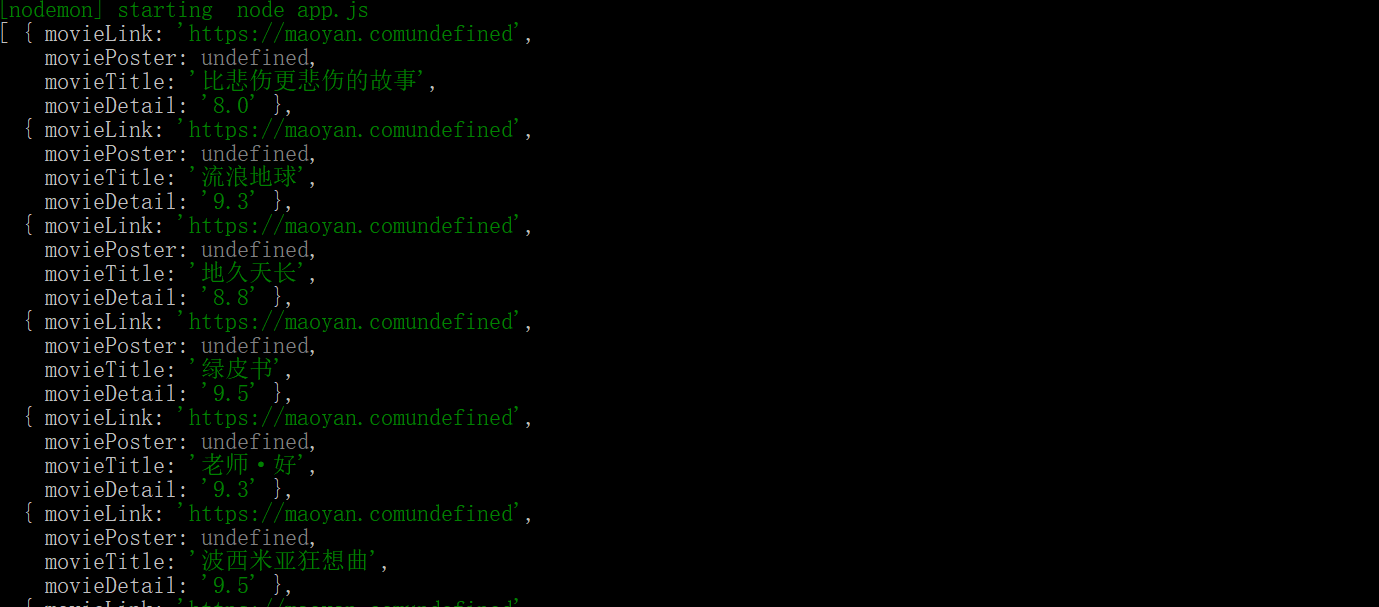
抓取结果(部分)