后缀自动机
这几天都在听lzh大神讲后缀自动机,感觉太神了,这东东能动态维护后缀数组,也就是说它能知道以某个位置为末尾的所有后缀,现在让我这蒟蒻来总结一下。
首先这是一个有限状态自动机,每个结点都能接收一些状态,注意是一些状态,在这里是后缀自动机,所以每个结点都能接收一些字符串(不一定为后缀),在后缀自动机中,边是代表字母。从源点出发,沿着实边能走到某个结点,这个结点就能接收该路径所代表的字符串。如果当前某个点为接收态,那么它能接收的字符串就是当前后缀。例如:

1接收的是""(空)
2: "a"
3: "ab"、"b"
4: "abc"、"ac"、"bc"
以上只是举例,并不保证能构造这样的字符串。
我们规定每个结点都有一个par指针,如果某个节点是接收态,那么它的par也是接收态。这就保证沿着par往上跳就能把所有后缀找出来(接收所有的后缀)
下面讲一下如何建后缀自动机。
对于每一个还要记住到达该点的最长路径长度len,全局变量
指针root(原点,也代表空),last(当前字符串的最长后缀的接收点)。下面举abadd为例子。(实边为点连出去的边,虚边为par)(用u-ch-v表示u连出一条ch边到v)
首先,只有root,last=root,root为接收态,(len(root)=0)

接着插入a,root-a-1.
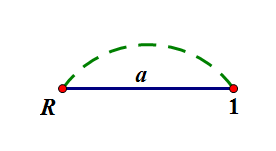
1为接收态,(len(1)=1),last=1(其实last肯定是一个接收态,然后沿par往上跳都是当前的接收态,其他的都不是)。
接着插入b,1-b-2,1往上跳到root,root-b-2

2的par为root,因为root是接收态,而1不是接收态,(len(2)=2),由图可以看出某个点i能接收的后缀长度为((len(par), len(i)]),这个之后会有用。
接着插入a,2-a-3,2往上跳到root,发现root-a-1,而且(len(root)+1=len(1)),也就是说1只接收一个字符串(a),那么只要把3的par指向1,把1变成接收态即可,(这就相当于在root接收的后缀后面加多了一个a,变成当前后缀),然后就不再往上跳(就算有par也不跳). (len(3)=3)
接着插入d,3-d-4, 3往上跳到1,1-d-4,1往上跳到root,root-d-4

4的par为root,(len(4)=4)
接着插入d, 4-d-5, 4往上跳到root,发现root-d-4,且(len(root)+1 eq len(4)),也就是说4不止接收一个字符串,如果把5的par指向4,则会使4中一些不是当前后缀当成当前后缀(其实在这个例子中,4中除了d为当前后缀,其它都不是当前后缀),于是新建一个节点6,把4拆成4和6,使得6能接收([len(4->par)+1, len(4->par)+1])的后缀,而原来的4只能接收((len(4->par)+1, len(4)]),(注意:这里只是刚好这个例子中root=4->par,这是有可能不等的)这里的6有点像上面那种情况(因为6只接收原来4中一个字符d的部分),所以4连出的边6也要连出。
因为root的par有可能连了一条d边到4(肯定会有一条d边,只是不知道是不是4,因为root比他的par能接收的字符串要长,且具有相同后缀,如果root加了d,他的par也有加上d,所以肯定有一条d边)。那么就要root->par-d-6,让6接收原来4中一个字符d的部分。然后一直往上跳,直到不是连向4。而那个点连向的正好就是4的par。下面会详细解释。

上图红色边为删掉的边
至于为什么直到不是连向4时,那个点连向的正好是4的par呢?见下图

设上述的那个点为p,向q连出d边,那么(len(p)+1=len(q)),因为q是4的par,如果(len(p)+1
eq len(q)),那么添加4时,4的par就不会连向q。
如果像这个例子,root已经没有par了,那么就把6的par指向root即可。
因为4失去了原本6那部分,因为要保证从4出发跳par还能找出abad的后缀,所以4的par=6,然后5的par=6(相当于第二种情况,6只接收一个字符串)
经过这样的处理,5和6就是最终的接收态,last=5,这就避免了重复。
代码时间
void insert(int num)
{
node *endd=mem++; //新加的点
node *cur=last; //之前的最长接收态
endd->len=last->len+1;
for (; cur && !cur->son[num]; cur=cur->par) cur->son[num]=endd; //第一种情况
if (!cur) endd->par=root;
else
if (cur->len+1==cur->son[num]->len) endd->par=cur->son[num]; //第二种情况
else
{
node *ed=mem++; //拆点
node *tmp=cur->son[num];
*ed=*cur->son[num]; //因为连出边和par都一样,直接复制信息就好了
ed->len=cur->len+1;
endd->par=tmp->par=ed;
//因为ed本来是tmp的一部分,tmp现已失去了接收ed那部分,所以要把tmp的par=ed。而endd的par=ed是因为这相当于第二种情况。
for (; cur && cur->son[num]==tmp; cur=cur->par)
cur->son[num]=ed;
//把原本连向tmp的属于ed的那一部分转移到ed
}
last=endd;//更新最长接收态
}
终于,到了时空复杂度的分析
对于空间复杂度,插入一个字母,最多只会新加两个点,所以点的空间复杂度为(O(2n))
至于边的空间复杂度,对于每一个点(p),连向p的点中,只有一个点的(len)等于(len(p)-1),这里就有(2n)条边。对于某一条边((u, v)),(len(u)+1<len(v)),那么从root沿最长路到(u),(v)沿最长路到一个接收态,那么这整条路径就是一个后缀,而且这路径上只有一条(len(u)+1<len(v))的边,(就是上述那条)。当然一条这样的边有可能对应多个后缀。后缀最多只有(n)个,那么最多只有(n)条这样的边。所以边的空间复杂度为((3n))
至于时间复杂度,可以像AC自动机那样分析,时间复杂度为(O(n))