一、论文:
1.EAST——EAST: An Efficient and Accurate Scene Text Detector
2.Fots——FOTS: Fast Oriented Text Spotting with a Unified Network
3.RefineNet——RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation
4..PixelLink——PixelLink: Detecting Scene Text via Instance Segmentation
二、内容:
1.EAST:
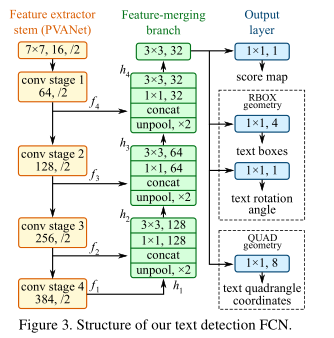
1)端到端的检测方式
2)多层特征融合方式
2.Fots:

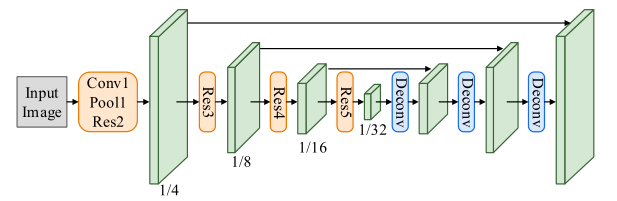
与EAST主要区别:
1)检测+识别端到端,识别提高检测
2)将特征融合方式改成了去卷积
3)将图像放大到2560,裁剪块512->640,宽不变高度随机0.8-1.2scale
4)用synth800k做预训练
3.RefineNet:
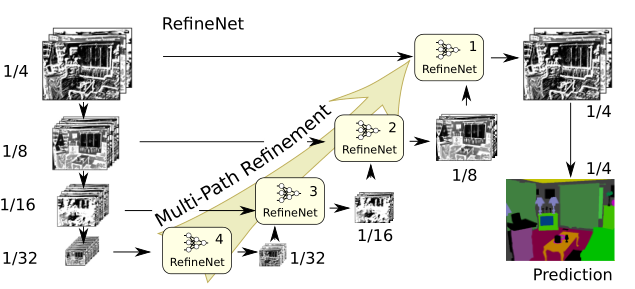
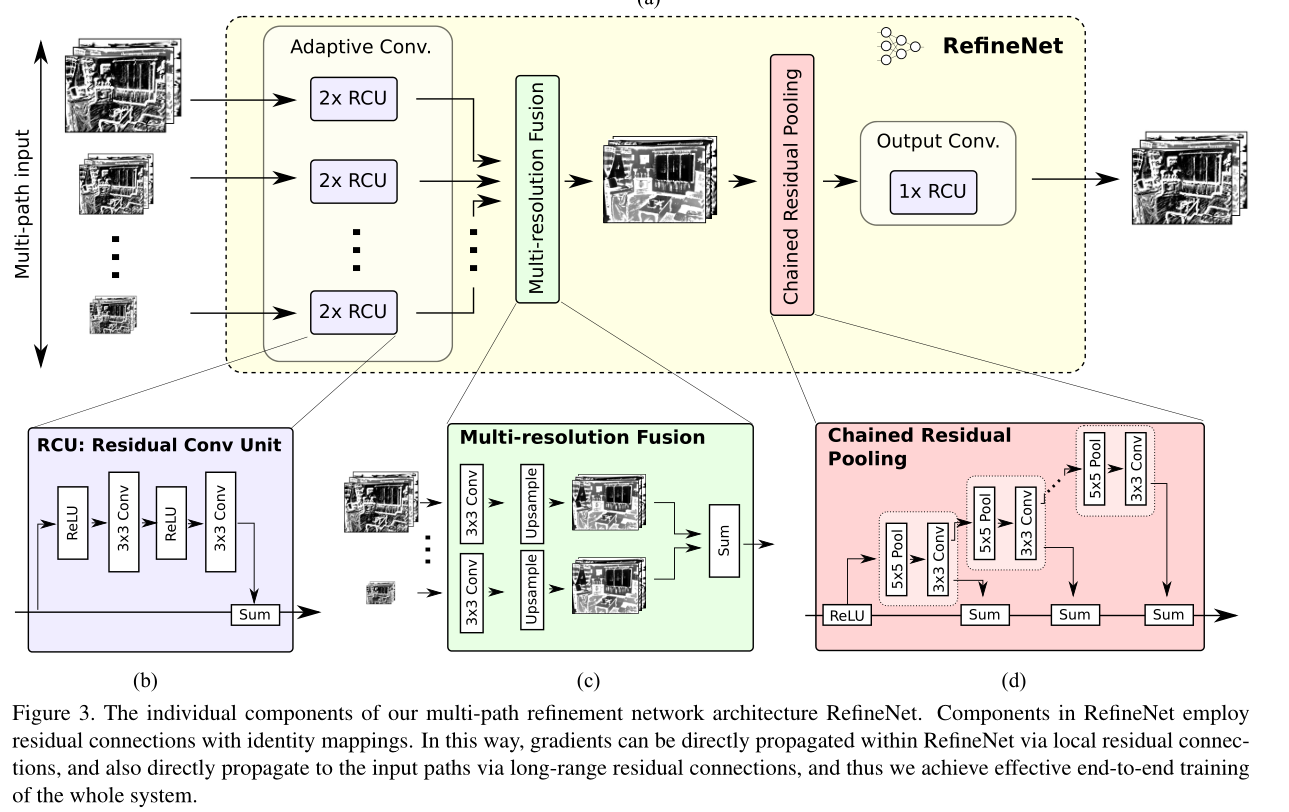
1)改了特征融合的方式
4.PixelLink:
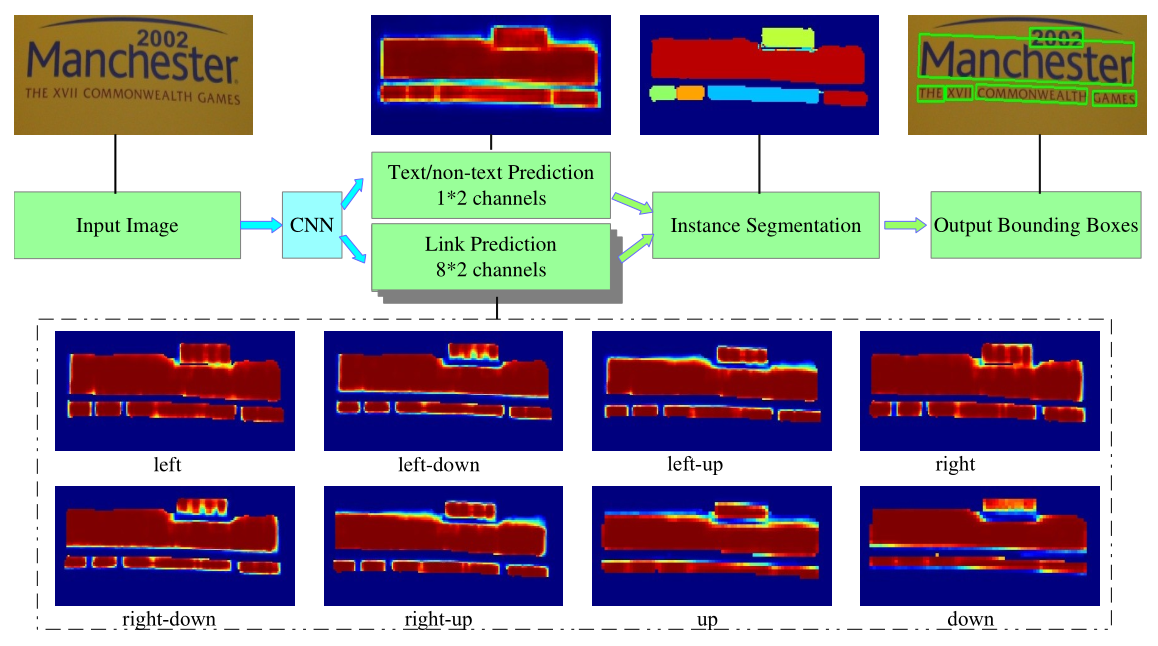
1)基础网络用了VGG,收敛快
2)score map用了两个channel
3)预测周边是否是字,最后用opencv算法求最小外接矩形
4)后期规则过滤
三、总结
1)EAST这种端到端,先卷积再特征融合的直接回归方式预计会成为以后检测的主流。
2)改进的点,无非在前置网络和特征融合方式上,其他就是数据集的处理。
3)貌似这种方式已经突破不了发不了文章了。