Shell变量
什么是 shell 变量
shell变量就是 用一个固定的字符串去表示不固定的内容
变量的类型
自定义变量
定义变量
变量名=变量值 (显式赋值)
变量名必须以字母或下划线开头,区分大小写
ip1=192.168.2.115
显式赋值
[root@hadoop04 shell]# cat ping.sh
#!/usr/bin/bash
# 显式赋值
ip=172.16.1.12
ping -c1 $ip &> /dev/null
if [ $? -eq 0 ];then
echo -e "e[32m$ip is upe[0m"
else
echo -e "e[31m$ip is downe[0m"
fi
隐式赋值
[root@hadoop04 shell]# cat ping01.sh
#!/usr/bin/bash
# 从键盘读入,赋值给变量ip(隐式赋值)
#read ip
# -p选项,提示输入
read -p "Please input a ip: " ip
ping -c1 $ip &> /dev/null
if [ $? -eq 0 ];then
echo -e "e[32m$ip is upe[0m"
else
echo -e "e[31m$ip is downe[0m"
fi
引用变量
1.$变量名
2.${变量名}
查看变量
1.echo $变量名
2.set 显示所有变量,包括自定义变量和环境变量
取消变量
unset 变量名
注意:unset后面跟的是变量名,不带$
作用范围
作用范围:仅在当前 shell 中有效
环境变量
定义环境变量
#方法1
export back_dir1=/home/backup1
#方法2,将自定义变量转换成环境变量
back_dir2=/home/backup2
export back_dir2
引用环境变量
1.$变量名
2.${变量名}
查看环境变量
echo $变量名
env 例如 env |grep back_dir2
取消环境变量
unset 变量名
注意:unset后面跟的是变量名,不带$
变量作用范围
变量作用范围: 在当前 shell 和子 shell 有效
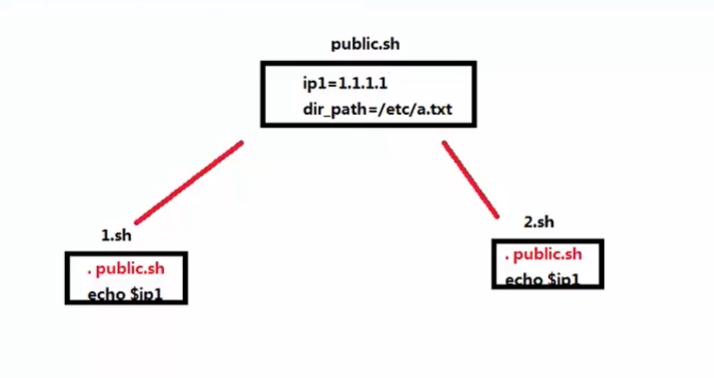
在实际项目中,不建议特地去定义环境变量,推荐方式:在公共脚本中定义公共变量,要使用公共变量时,只需要在当前脚本执行公共脚本( . public.sh)
=====================================================
C 语言 局部变量 vs 全局变量
SHELL 自定义变量 vs 环境变量
=====================================================
位置变量
$1 $2 $3 $4 $5 $6 $7 $8 $9 ${10}
[root@hadoop04 shell]# cat ping02.sh
#!/usr/bin/bash
ping -c1 $1 &> /dev/null
if [ $? -eq 0 ];then
echo -e "e[32m$1 is upe[0m"
else
echo -e "e[31m$1 is downe[0m"
fi
# 虽然传了两个变量,但是此脚本中只引用了$1
[root@hadoop04 shell]# bash ping02.sh 172.16.1.12 172.22.34.1
172.16.1.12 is down
预定义变量
$0 脚本名
$* 所有的参数
$@ 所有的参数
$# 参数的个数
$$ 当前进程的 PID
$! 上一个后台进程的 PID
$? 上一个命令的返回值 0 表示成功
示例
例1
[root@hadoop04 shell]# cat test.sh
#!#/usr/bin/bash
echo "第 2 个位置参数是$2"
echo "第 1 个位置参数是$1"
echo "第 4 个位置参数是$4"
echo "所有参数是: $*"
echo "所有参数是: $@"
echo "参数的个数是: $#"
echo "当前进程的 PID 是: $$"
echo '$1='$1
echo '$2='$2
echo '$3='$3
echo '$*='$*
echo '$@='$@
echo '$#='$#
echo '$$='$$
[root@hadoop04 shell]# bash test.sh A B C D E F
第 2 个位置参数是B
第 1 个位置参数是A
第 4 个位置参数是D
所有参数是: A B C D E F
所有参数是: A B C D E F
参数的个数是: 6
当前进程的 PID 是: 11742
$1=A
$2=B
$3=C
$*=A B C D E F
$@=A B C D E F
$#=6
例2
[root@hadoop04 shell]# vim ping03.sh
#!/usr/bin/bash
#如果用户没有加参数
if [ $# -eq 0 ];then
echo "usage: `basename $0` file"
exit
fi
#如果传入的参数不是文件
if [ ! -f $1 ];then
echo "$1 is not file"
exit
fi
for ip in `cat $1`
do
ping -c1 $ip &> /dev/null
if [ $? -eq 0 ];then
echo -e "e[32m$ip is upe[0m"
else
echo -e "e[31m$ip is downe[0m"
fi
done
[root@hadoop04 shell]# cat ip.txt
172.22.34.10
172.22.34.20
172.22.34.30
[root@hadoop04 shell]# bash ping03.sh ip.txt
172.22.34.10 is down
172.22.34.20 is up
172.22.34.30 is up
变量的赋值方式
显式赋值
变量名=变量值
示例
ip1=192.168.1.251
school="BeiJing 1000phone"
today1=`date +%F`
today2=$(date +%F)
read 从键盘读入变量值
read 变量名
# -p选项,提示信息
read -p "提示信息: " 变量名
# -t选项,等待输入时间,单位为秒s
read -t 5 -p "提示信息: " 变量名
#-n选项,限制字符
read -n 2 变量名
示例
[root@hadoop04 shell]# vim input.sh
#!/usr/bin/bash
read -p "输入姓名,年龄,性别[e.g. zhangsan 29 m]: " name age sex
echo "您输入的姓名: ${name},年龄: ${age},性别: ${sex}"
[root@hadoop04 shell]# bash input.sh
输入姓名,年龄,性别[e.g. zhangsan 29 m]: sek 29 w
您输入的姓名: sek,年龄: 29,性别: w
注意事项
定义或引用变量时注意事项
1." " 弱引用
2.' ' 强引用
3.` ` 命令替换 等价于 $() 反引号中的 shell 命令会被先执行
变量的运算
整数运算
方法1: expr
expr 1 + 2
expr $num1 + $num2 加+ 减- 乘* 除/ 取余%
☆方法2: $(())
echo $(($num1+$num2)) 加+ 减- 乘* 除/ 取余%
echo $((num1+num2))
echo $((5-3*2))
echo $(((5-3)*2))
echo $((2**3))
sum=$((1+2)); echo $sum
方法3: $[]
echo $[5+2] + - * / %
echo $[5**2]
☆☆方法4: let
let sum=2+3; echo $sum
let i++; echo $i
示例
例1
[root@hadoop04 shell]# vim mem_usage.sh
#!/usr/bin/bash
mem_used=`free -m | grep Mem | awk '{print $3}'`
mem_total=`free -m | grep Mem | awk '{print $2}'`
mem_percent=$((100*mem_used/mem_total))
echo "当前的内存使用率是${mem_percent}%"
[root@hadoop04 shell]# bash mem_usage.sh
当前的内存使用率是3%
例2
[root@hadoop04 shell]# vim ping04.sh
#!/usr/bin/bash
ip=172.22.34.18
i=1
while [ $i -le 5 ]
do
ping -c1 $ip &> /dev/null
if [ $? -eq 0 ];then
echo -e "e[32m$ip is upe[0m"
else
echo -e "e[31m$ip is downe[0m"
fi
let i++
done
[root@hadoop04 shell]# bash ping04.sh
172.22.34.18 is up
172.22.34.18 is up
172.22.34.18 is up
172.22.34.18 is up
172.22.34.18 is up
小数运算
如果没有安装计算器,需要先安装
[root@hadoop04 ~]# yum -y install bc
计算样式
1.bc
echo "2*4" |bc
echo "2^4" |bc
echo "scale=2;6/4" |bc
2.awk
awk 'BEGIN{print 1/2}'
3.python
echo "print 5.0/2" |python
改进上面的例1
[root@hadoop04 shell]# vim mem_usage.sh
#!/usr/bin/bash
mem_used=`free -m | grep Mem | awk '{print $3}'`
mem_total=`free -m | grep Mem | awk '{print $2}'`
mem_percent=`echo "scale=2;100*$mem_used/$mem_total" | bc`
echo "当前的内存使用率是${mem_percent}%"
[root@hadoop04 shell]# bash mem_usage.sh
当前的内存使用率是3.95%
变量"内容"的删除和替换
"内容"的删除
标准查看
${变量名}
示例
[root@hadoop04 ~]# url=www.sina.com.cn
[root@hadoop04 ~]# echo ${url}
www.sina.com.cn
获取变量值的长度
${#变量名}
示例
[root@hadoop04 ~]# url=www.sina.com.cn
[root@hadoop04 ~]# echo ${#url}
15
从前往后,最短匹配
${string#substring}
string可以是字符串,也可以是字符串变量名
substring即子串
${string#substring}表示从string开头处删除子串(与substring匹配的最短子串)
非贪婪匹配
示例
[root@hadoop04 ~]# url=www.sina.com.cn
# 与“*si”匹配的最短子串是“www.si”
[root@hadoop04 ~]# echo ${url#*si}
na.com.cn
# 与“*.”匹配的最短子串是“www.”
[root@hadoop04 ~]# echo ${url#*.}
sina.com.cn
从前往后,最长匹配
${string##substring}
${string##substring}表示从string开头处删除子串(与substring匹配的最长子串)
贪婪匹配
[root@hadoop04 ~]# url=www.sina.com.cn
# 与“*.”匹配的最长子串是“www.sina.com.”
[root@hadoop04 ~]# echo ${url##*.}
cn
从后往前,最短匹配
${string%substring}
string可以是字符串,也可以是字符串变量名
substring即子串
${string%substring}表示从string结尾处删除子串(与substring匹配的最短子串)
非贪婪匹配
[root@hadoop04 ~]# url=www.sina.com.cn
# 与“.*”匹配的最短子串是“.cn”
[root@hadoop04 ~]# echo ${url%.*}
www.sina.com
从后往前,最长匹配
${string%substring}
string可以是字符串,也可以是字符串变量名
substring即子串
${string%substring}表示从string结尾处删除子串(与substring匹配的最长子串)
贪婪匹配
[root@hadoop04 ~]# url=www.sina.com.cn
# 与“.*”匹配的最短子串是“.sina.com.cn”
[root@hadoop04 ~]# echo ${url%%.*}
www
索引及切片
1.string字符串的索引从0开始,最后一个索引是(长度-1)
2.{string:position} 表示从名称为string的字符串的第position个位置开始抽取子串,从0开始标号
3.{string:position:length}表示从名称为string字符串的第position个位置开始抽取长度为length的子串
示例
# 抽取从索引0开始,长度为5的子串
[root@hadoop04 ~]# echo ${url:0:5}
www.s
# 抽取从索引5开始,长度为5的子串
[root@hadoop04 ~]# echo ${url:5:5}
ina.c
# 抽取从索引5开始,到字符串结束的子串
[root@hadoop04 ~]# echo ${url:5}
ina.com.cn
"内容"的替换
${string/substring/replacement},仅替换第一次与substring相匹配的子串
非贪婪匹配
[root@hadoop04 ~]# url=www.sina.com.cn
[root@hadoop04 ~]# echo ${url/sina/baidu}
www.baidu.com.cn
[root@hadoop04 ~]# echo ${url/n/N}
www.siNa.com.cn
${string//substring/replacement},替换所有与substring相匹配的子串
贪婪匹配
[root@hadoop04 ~]# url=www.sina.com.cn
[root@hadoop04 ~]# echo ${url//n/N}
www.siNa.com.cN
在开头处替换与substring相匹配的子串,格式为:${string/#substring/replacement}
非贪婪
[root@hadoop04 ~]# url=www.sina.com.cn
[root@hadoop04 ~]# echo ${url/#www/ftp}
ftp.sina.com.cn
[root@hadoop04 ~]# echo ${url/#w/W}
Www.sina.com.cn
在结尾除替换与substring相匹配的子串,格式为:${string/%substring/replacement}
非贪婪
[root@hadoop04 ~]# url=www.sina.com.cn
[root@hadoop04 ~]# echo ${url/%cn/org}
www.sina.com.org
变量的替代
${变量名-新的变量值}
变量没有被赋值:会使用“新的变量值“ 替代
变量有被赋值(包括空值):不会被替代
[root@hadoop04 ~]# echo ${var1}
[root@hadoop04 ~]# echo ${var1-aaaaa}
aaaaa
[root@hadoop04 ~]# var2=111
[root@hadoop04 ~]# echo ${var2-bbbbb}
111
[root@hadoop04 ~]# var3=
[root@hadoop04 ~]# echo ${var3-ccccc}
${变量名:-新的变量值}
变量没有被赋值(包括空值):都会使用“新的变量值“ 替代
变量有被赋值:不会被替代
[root@hadoop04 ~]# echo ${var4}
[root@hadoop04 ~]# echo ${var4:-aaaaa}
aaaaa
[root@hadoop04 ~]# va5=111
[root@hadoop04 ~]# echo ${var5:-bbbbb}
111
[root@hadoop04 ~]# var6=
[root@hadoop04 ~]# echo ${var6:-ccccc}
ccccc
${变量名+新的变量值}
变量没有被赋值:不会被替代
变量有被赋值(包括空值):会使用“新的变量值“ 替代
${变量名:+新的变量值}
变量没有被赋值(包括空值):不会被替代
变量有被赋值:会使用“新的变量值“ 替代
${变量名=新的变量值}
变量没有被赋值:都会使用“新的变量值“ 替代,并且声明该变量变量名=新的变量值
变量有被赋值(包括空值):不会被替代
${变量名:=新的变量值}
变量没有被赋值(包括空值):都会使用“新的变量值“ 替代,并且声明该变量变量名=新的变量值
变量有被赋值(包括空值):不会被替代
${变量名?新的变量值}
待补充
${变量名:?新的变量值}
待补充
参考链接:https://blog.csdn.net/seulzz/article/details/101350452
https://blog.51cto.com/lulucao2006/1734696
https://blog.csdn.net/xy913741894/article/details/74355576
i++ 和 ++i
i++
先赋值,再运算
++i
先运算,再赋值
对变量的值的影响:没有影响
[root@tianyun ~]# i=1
[root@tianyun ~]# let i++
[root@tianyun ~]# echo $i
2
[root@tianyun ~]# j=1
[root@tianyun ~]# let ++j
[root@tianyun ~]# echo $j
2
对表达式的值的影响:表达式的值受影响
[root@tianyun ~]# unset i
[root@tianyun ~]# unset j
[root@tianyun ~]# i=1
[root@tianyun ~]# j=1
[root@tianyun ~]# let x=i++ 先赋值,再运算
[root@tianyun ~]# let y=++j 先运算,再赋值
[root@tianyun ~]# echo $i
2
[root@tianyun ~]# echo $j
2
[root@tianyun ~]# echo $x
1
[root@tianyun ~]# echo $y
2