Non-linear Hypotheses
线性回归和逻辑回归在特征很多时,计算量会很大。
一个简单的三层神经网络模型:
[a_i^{(j)} = ext{"activation" of unit $i$ in layer $j$}$$$$Theta^{(j)} = ext{matrix of weights controlling function mapping from layer $j$ to layer $j+1$}
]

其中:$$a_1^{(2)} = g(Theta_{10}^{(1)}x_0 + Theta_{11}^{(1)}x_1 + Theta_{12}^{(1)}x_2 + Theta_{13}{(1)}x_3)$$$$a_2{(2)} = g(Theta_{20}^{(1)}x_0 + Theta_{21}^{(1)}x_1 + Theta_{22}^{(1)}x_2 + Theta_{23}{(1)}x_3)$$$$a_3{(2)} = g(Theta_{30}^{(1)}x_0 + Theta_{31}^{(1)}x_1 + Theta_{32}^{(1)}x_2 + Theta_{33}^{(1)}x_3)$$$$h_Theta(x) = a_1^{(3)} = g(Theta_{10}{(2)}a_0{(2)} + Theta_{11}{(2)}a_1{(2)} + Theta_{12}{(2)}a_2{(2)} + Theta_{13}{(2)}a_3{(2)})$$
vectorized implementation
将上面公式中函数(g)中的东西用(z)代替:
[a_1^{(2)} = g(z_1^{(2)})$$$$a_2^{(2)} = g(z_2^{(2)})$$$$a_3^{(2)} = g(z_3^{(2)})
]
令(x=a^{(1)}):
[z^{(j)} = Theta^{(j-1)}a^{(j-1)}
]
得到:
[egin{aligned}z^{(j)} = egin{bmatrix}z_1^{(j)} \ z_2^{(j)} \ cdots \z_n^{(j)}end{bmatrix}end{aligned}
]
这块的记号比较多,用例子梳理下:
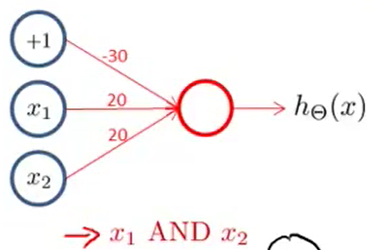
实现一个逻辑与的神经网络:
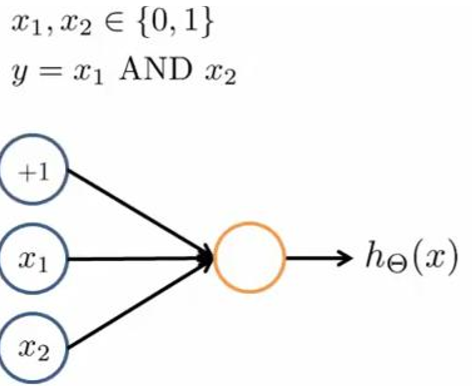
那么:
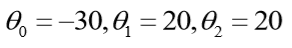
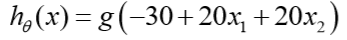
所以有:

再来一个多层的,实现XNOR功能(两输入都为0或都为1,输出才为1):

基本的神经元:
- 逻辑与
- 逻辑或
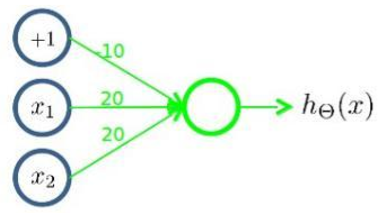
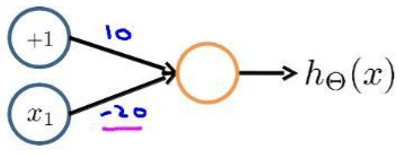
- 逻辑非
先构造一个表示后半部分的神经元: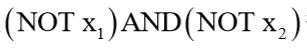
这样的:
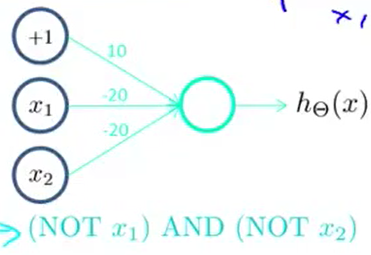
接着将前半部分组合起来:
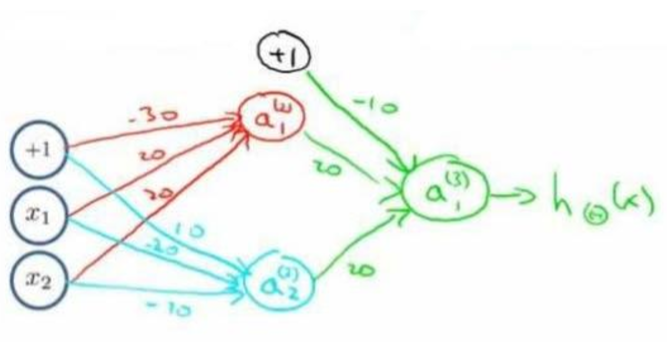
Multiclass Classification
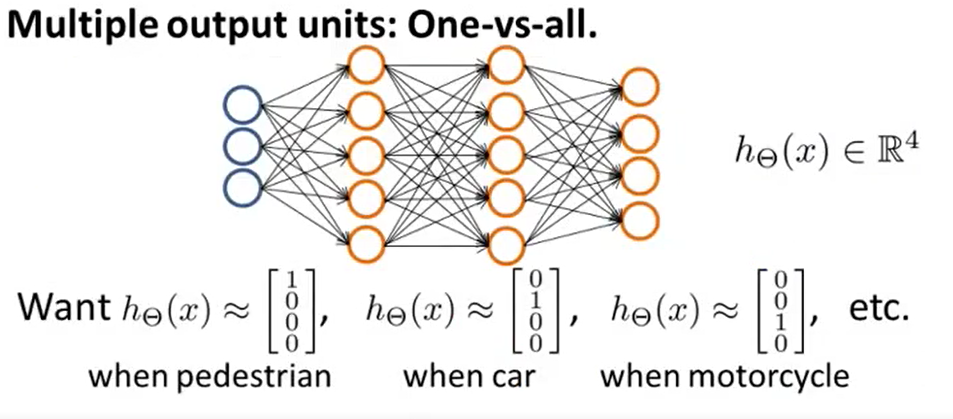
Motivation
Implementation
import torch
from torchvision.datasets import FashionMNIST
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import numpy as np
def load_data():
# My data is in ../data/FashionMNIST/raw & ../data/FashionMNIST/processed
train_data = FashionMNIST(root='../data', train=True, download=False, transform=transforms.ToTensor())
test_data = FashionMNIST(root='../data', train=False, download=False, transform=transforms.ToTensor())
train_iter = DataLoader(train_data, batch_size=256, shuffle=True, num_workers=0)
test_iter = DataLoader(test_data, batch_size=256, shuffle=False, num_workers=0)
return train_iter, test_iter
num_inputs, num_outputs, num_hiddens = 784, 10, 256
W1 = torch.tensor(np.random.normal(0, 0.01, (num_inputs, num_hiddens)), dtype=torch.float)
b1 = torch.zeros(num_hiddens, dtype=torch.float)
W2 = torch.tensor(np.random.normal(0, 0.01, (num_hiddens, num_outputs)), dtype=torch.float)
b2 = torch.zeros(num_outputs, dtype=torch.float)
# W1 = nn.Parameter(torch.randn(num_inputs, num_hiddens, requires_grad=True) * 0.01)
# b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
# W2 = nn.Parameter(torch.randn(num_hiddens, num_outputs, requires_grad=True) * 0.01)
# b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
for param in params:
param.requires_grad_(requires_grad=True)
def relu(X):
return torch.max(input=X, other=torch.zeros(X.shape))
def softmax(X):
X_exp = torch.exp(X)
partition = X_exp.sum(1, keepdim=True)
return X_exp / partition
def net(X):
X = X.reshape((-1, num_inputs))
H = relu(torch.matmul(X, W1) + b1)
output = torch.matmul(H, W2) + b2
return softmax(output)
def cross_entropy(y_predict, y):
return -torch.log(y_predict[range(len(y_predict)), y])
def sgd(params, lr, batch_size):
for param in params:
param.data -= lr * param.grad / batch_size
def evaluate_accuracy(net, data_iter):
acc_sum, n = 0.0, 0
for X, y in data_iter:
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum / n
def train(net, train_iter, test_iter, loss, num_epochs, batch_size=256, lr=0.1, params=None, optimizer=None):
for epoch in range(num_epochs):
train_loss_sum, train_acc_sum, n = 0.0, 0.0, 0
for X, y in train_iter:
y_predict = net(X)
l = cross_entropy(y_predict, y).sum()
l.backward()
sgd(params, lr, batch_size)
W1.grad.data.zero_()
b1.grad.data.zero_()
W2.grad.data.zero_()
b2.grad.data.zero_()
train_loss_sum += l.item()
train_acc_sum += (y_predict.argmax(dim=1) == y).sum().item()
n += y.shape[0]
test_acc = evaluate_accuracy(net, test_iter)
print('epoch %d, loss %.4f, train_acc %.4f, test_acc %.4f'
% (epoch + 1, train_loss_sum / n, train_acc_sum / n, test_acc))
if __name__ == "__main__":
# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_iter, test_iter = load_data()
train(net, train_iter, test_iter, cross_entropy, 10, lr=0.1, params=params)
import torch
import torch.nn as nn
import torch.nn.init as init
from torchvision.datasets import FashionMNIST
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
def load_data():
# My data is in ../data/FashionMNIST/raw & ../data/FashionMNIST/processed
train_data = FashionMNIST(root='../data', train=True, download=False, transform=transforms.ToTensor())
test_data = FashionMNIST(root='../data', train=False, download=False, transform=transforms.ToTensor())
train_iter = DataLoader(train_data, batch_size=256, shuffle=True, num_workers=0)
test_iter = DataLoader(test_data, batch_size=256, shuffle=False, num_workers=0)
return train_iter, test_iter
class Net(nn.Module):
def __init__(self, num_inputs, num_outputs, num_hiddens):
super(Net, self).__init__()
self.l1 = nn.Linear(num_inputs, num_hiddens)
self.relu1 = nn.ReLU()
self.l2 = nn.Linear(num_hiddens, num_outputs)
def forward(self, X):
X = X.view(X.shape[0], -1)
o1 = self.relu1(self.l1(X))
o2 = self.l2(o1)
return o2
def init_params(self):
for param in self.parameters():
init.normal_(param, mean=0, std=0.01)
def evaluate_accuracy(net, data_iter):
acc_sum, n = 0.0, 0
for X, y in data_iter:
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum / n
def train(net, train_iter, test_iter, loss, num_epochs, batch_size=256, lr=0.1, params=None, optimizer=None):
for epoch in range(num_epochs):
train_loss_sum, train_acc_sum, n = 0.0, 0.0, 0
for X, y in train_iter:
y_predict = net(X)
l = loss(y_predict, y).sum()
l.backward()
optimizer.step()
optimizer.zero_grad()
train_loss_sum += l.item()
train_acc_sum += (y_predict.argmax(dim=1) == y).sum().item()
n += y.shape[0]
test_acc = evaluate_accuracy(net, test_iter)
print('epoch %d, loss %.4f, train_acc %.4f, test_acc %.4f'
% (epoch + 1, train_loss_sum / n, train_acc_sum / n, test_acc))
num_inputs, num_outputs, num_hiddens = 784, 10, 256
net = Net(num_inputs, num_outputs, num_hiddens)
net.init_params()
loss = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.1)
if __name__ == "__main__":
train_iter, test_iter = load_data()
train(net, train_iter, test_iter, loss, 10, optimizer=optimizer)