-下载网页: urllib Request
-解析网页 BeautifulSoup
-模拟交互 处理JS动态网页: Selenium
- 分布式队列
- 布隆过滤器(BLoom Filter)
网络爬虫是一种自动提取网页的程序,它为搜索引擎
从万维网上下载网页,是搜索引擎的重要组成部分。
传统爬虫从一个活若干初始网页URL开始,获得初始网页上的URL,
在爬取网页过程中,不断从当前页面上抽取新的url放入队列,
直到满足系统的一定停止条件
爬虫的分类
批量型爬虫
批量型爬虫有明确的抓取范围和慕白,当爬虫达到这个设定目标后
即停止抓取过程。
增量型爬虫
增量型爬虫会持续不断的抓取,对于抓取的网页,要定期更新。
通用的商业搜索引擎爬虫基本属于此类
垂直型爬虫
垂直型爬虫关注特定主体内容或者属于特定行业的网页,其他主体或者
其他行业的内容不再考虑范围。
网络爬虫的基本工作流程:
1.首先选取一部分精心挑选的种子url;
2.将这些URL放入等待抓取的URL队列;
3.从待抓取队列中取出URL,解析DNS,并且得到主机的IP,并将URL
对应的网页下载下来。存储进已下载网页库。此外,将这些url放进已抓取的URL队列
4.分析已经抓取的URL队列中的URL,分析其中的其他URL。并且将URL放入待抓取URL队列。从而进入下一个循环。
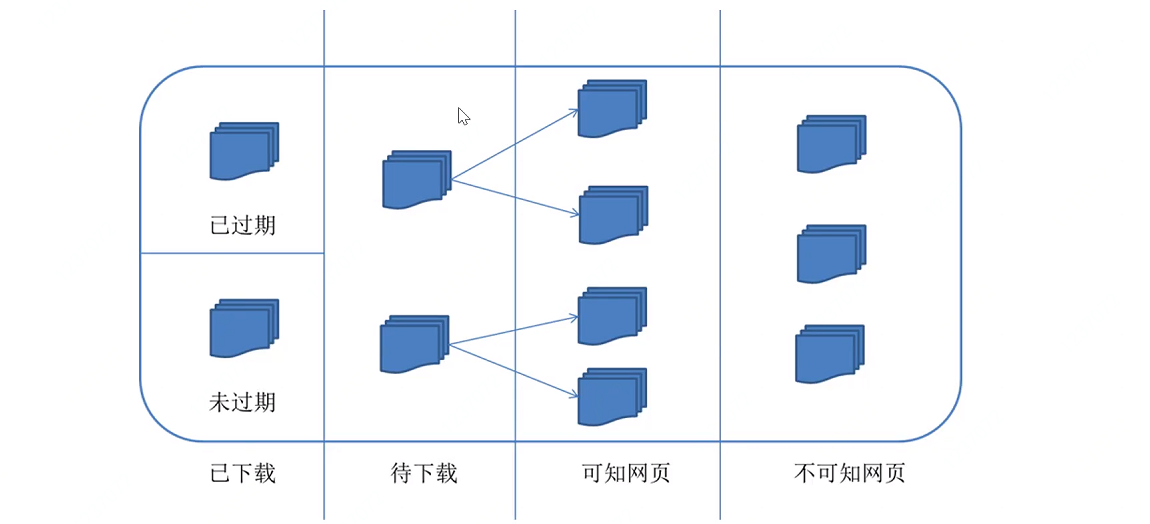
对应的,可以将互联网的所有页面分为五个部分:
1.已下载未过期网页
2.已下载已过期网页:
抓取到网页实际上是互联网内容的一个镜像与备份,互联网是动态变化的,一部分互联网上的内容以及发生了变化。
这是,这部分爬取的网页就已经过期了。
3.等待下载的网页: 待抓取URL序列的页面。
4.已知网页:还没有爬取下来,也没有在待爬取URL队列中,但是可以通过对已爬取页面或者待爬取URL对应页面进行分析获得URL,
认为是可可知网页。
5.不可知网页: 有一部分网页,爬虫是无法直接抓取下载的。
爬虫系统中,待抓取URL队列是很重要一部分。待抓取URL队列中的URL以怎样的排序队列也是一个很重要的问题
因为涉及到先抓取那个页面,后抓取哪个页面而决定这些URL排列顺序的方法,叫做抓取策略。下面重点介绍几种常见的抓取策略。
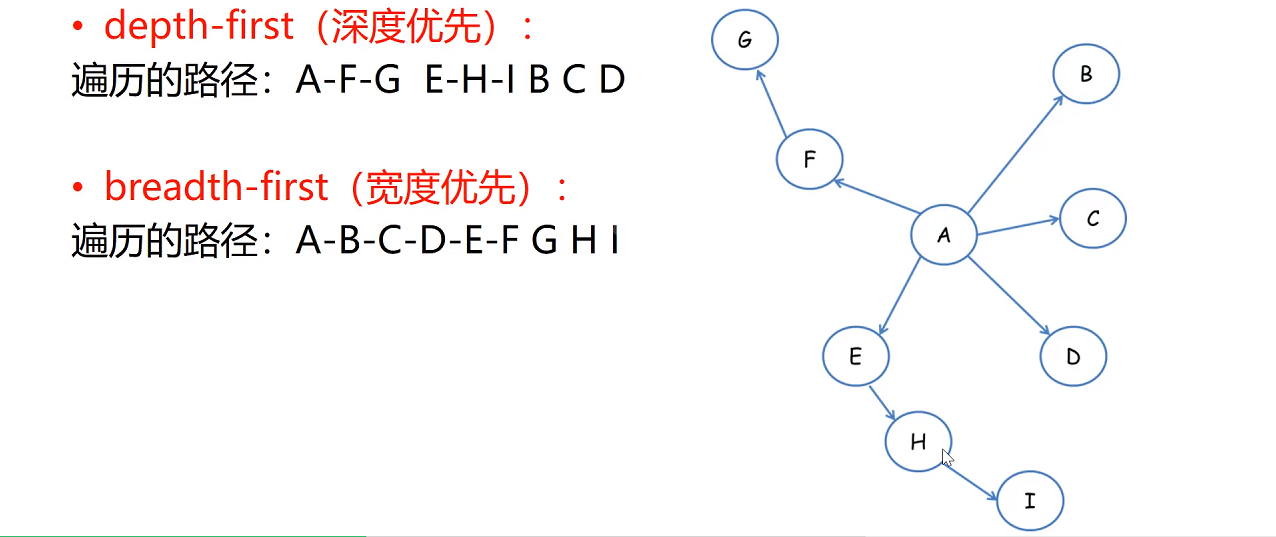
1.深度优先遍历策略
2.宽度(广度)优先遍历策略
3.反向链路数策略
4.Partial PageRank 策略
互联网是动态变化的,具有很强的动态性。网页更新策略主要是决定何时更新之前已经下载过的页面。常见的更新策略有以下三种:
1.历史参考策略
2.用户体验策略
3.聚类抽样策略
泊松分布
尽管搜索引擎针对于某查询条件返回数量巨大的结果,但是用户往往只是关注前几页结果。
因此,抓取系统可以优先更新那些显示在查询结果前几页的网页。而后再更新那些后面网页。
这种更新策略也是需要用到历史信息的。
用户体验策略保留网页多个历史版本,并且可以根据过去每次内容变化对搜索质量的影响,得到一个平均值。
用这个值作为决定何时抓取的依据
