一、
1.创建数据库 create database MyDB on primary ( Name=MyDB, FileName="D:MyDB.MDF" ), --创建主数据文件叫MyDB,放在D盘中. ( Name=MyDB1, FileName="E:MyDB1.NDF" ), --创建次数据文件叫MyDB1,放在E盘中. log on ( Name="MyDB_Log", FileName="E:MyDB.Log" ) --创建MyDB的日志文件,放在E盘中. 2.打开数据库 use MyDB use master 3.修改数据 alter database MyDB --修改MyDB数据库 add file --添加file文件 ( Name="MyDB2", --创建次数据文件叫MyDB1. FileName="C:MyDB2.ndf" --将MyDB次数据文件放在C盘中. ) 4.删除数据库 drop database mydb 5.查看数据库的信息 sp_helpdb mydb 8.重命名数据库 sp_renamedb 'NewMyDB','MyDB' 6.创建表 create table Login ( UserName varchar(20) primary key, --建主键. Password varchar(20) not null, --不能为空值. Name varchar(20) unique, --建惟一键. Sex bit default 1, --建默认约束(缺省约束). Birthday datetime check(birthday>'1900-1-1') --建检查约束. ) 7.修改表 alter table Login Add Money float --添加 alter table login drop column Money --删除 alter table Login alter column Money Real --修改 8.删除表 drop table Login
关键字:
primary key :主键
identity:自增长
references表名(列名):外键关系
primary key(Code,ChengWei)联合主键
点击新建查询,在窗口内输入语句并点击执行

4.使用数据库并创建一个表,表中添加列名
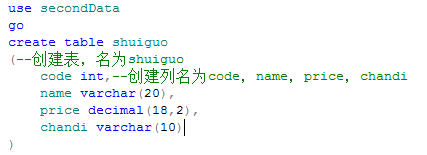
5.在表中添加数据,并查询此表。(按照列名来添加,用逗号隔开)
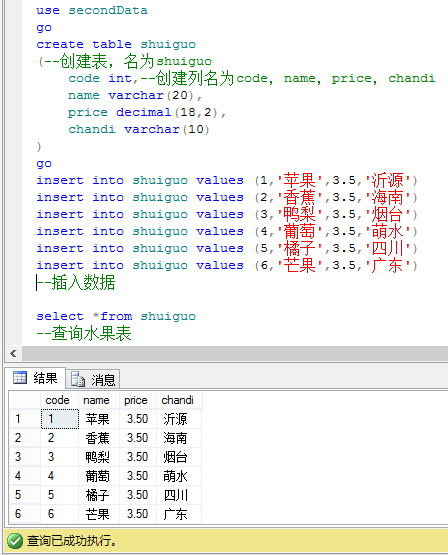
二、约束
主键约束 防止在新增数据时出错,有约束性,起唯一标志的作用,在新增条目的时候防止不慎添加重复内容(不允许有null值) 1、 右键—设计—设置主键 2、在创建表格时设置 code int primary key, 3、可以设置自增长的功能 code int primary key identity(1,1) 4、在自增长的环境下删掉其中一行,其他行不受影响 5、可以加快查询的速度,减慢新增和修改的速度 外键约束 设计—关系—添加—表和列规范—需要有联系的两个列 主键需要先设置,然后在主键的基础上建立外键,才能通过主键控制其他的外键
唯一约束(主键列、索引列的候选索引) 设计---右键---索引/键---需要修改的列----是唯一的----忽略重复键 代码方式: cid varchar (20) unique check约束 check约束——表达式——写上需要约束的范围(一个值不能同时给定两个范围)
三、三大范式
第一范式:(1NF):列的原子性,每一列不能再往下拆分
第二范式:(2NF):针对于联合主键,其中某些列只和一个主键列有关系违反了第二范式。
第三范式:(3NF):该表中,不能出现与主键间接关联的列,只能有直接关系的列
关键字:
primary key :主键
identity:自增长
references表名(列名):外键关系
范式应用举例
第一范式(1NF):要求关系模式R的所有属性都是不可分的基本数据项,指数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。
例如:比如某些数据库系统中需要用到“地址”这个属性,本来直接将“地址”属性设计成一个数据库表的字段就行。但是如果系统经常会访问“地址”属性中的“城市”部分,那么就非要将“地址”这个属性重新拆分为省份、城市、详细地址等多个部分进行存储,这样在对地址中某一部分操作的时候将非常方便。这样设计才算满足了数据库的第一范式,如下表所示。
用户信息表
| 编号 | 姓名 | 性别 | 年龄 | 联系电话 | 省份 | 城市 | 详细地址 |
| 1 | 张红欣 | 男 | 26 | 0378-23459876 | 河南 | 开封 | 朝阳区新华路23号 |
| 2 | 李四平 | 女 | 32 | 0751-65432584 | 广州 | 广东 | 白云区天明路148号 |
| 3 | 刘志国 | 男 | 21 | 0371-87659852 | 河南 | 郑州 | 二七区大学路198号 |
| 4 | 郭小明 | 女 | 27 | 0371-62556789 | 河南 | 郑州 | 新郑市薛店北街218号 |
上表所示的用户信息遵循了第一范式的要求,这样在对用户使用城市进行分类的时候就非常方便,也提高了数据库的性能。
第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)首先要求数据库表中首先必须有主键。为实现区分通常需要为表加上一个列,以存储各个实例的唯一标识。其次要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性,如果存在,那么这个属性和主关键字的这一部分应该分离出来形成一个新的实体,新实体与原实体之间是一对多的关系。采用投影分解法将一个1NF的关系分解为多个2NF的关系,可以在一定程度上减轻原1NF关系中存在的插入异常、删除异常、数据冗余度大、修改复杂等问题。
比如要设计一个订单信息表,因为订单中可能会有多种商品,所以要将订单编号和商品编号作为数据库表的联合主键,如下表所示。
订单信息表
| 订单编号 | 商品编号 | 商品名称 | 数量 | 单位 | 商品价格 |
| 001 | 1 | 挖掘机 | 1 | 台 | 1200000¥ |
| 002 | 2 | 冲击钻 | 8 | 个 | 230¥ |
| 003 | 3 | 铲车 | 2 | 辆 | 980000¥ |
这样就产生一个问题:这个表中是以订单编号和商品编号作为联合主键。这样在该表中商品名称、单位、商品价格等信息不与该表的主键相关,而仅仅是与商品编号相关。所以在这里违反了第二范式的设计原则。
而如果把这个订单信息表进行拆分,把商品信息分离到另一个表中,就非常完美了。如下面这两个所示。
订单信息表
| 订单编号 | 商品编号 | 数量 |
| 001 | 1 | 1 |
| 002 | 2 | 8 |
| 003 | 3 | 2 |
商品信息表
| 商品编号 | 商品名称 | 单位 | 商品价格 |
| 1 | 挖掘机 | 台 | 1200000¥ |
| 2 | 冲击钻 | 个 | 230¥ |
| 3 | 铲车 | 辆 | 980000¥ |
这样设计,在很大程度上减小了数据库的冗余。如果要获取订单的商品信息,使用商品编号到商品信息表中查询即可。
第三范式3NF是第二范式(2NF)的一个子集,即满足第三范式必须满足第二范式。第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关,即任何非主属性不得传递依赖于主属性。简而言之,就是要求一个关系中不包含已在其它关系已包含的非主关键字信息。(不满足时常采用投影分解法解决)
比如在设计一个订单数据表的时候,可以将客户编号作为一个外键和订单表建立相应的关系。而不可以在订单表中添加关于客户其它信息(比如姓名、所属公司等)的字段。如下面这两个表所示的设计就是一个满足第三范式的数据库表。
订单信息表
| 订单编号 | 订单项目 | 负责人 | 业务员 | 订单数量 | 客户编号 |
| 001 | 挖掘机 | 刘明 | 李东明 | 1台 | 1 |
| 002 | 冲击钻 | 李刚 | 霍新峰 | 8个 | 2 |
| 003 | 铲车 | 郭新一 | 艾美丽 | 2辆 | 1 |
客户信息表
| 客户编号 | 客户名称 | 所属公司 | 联系方式 |
| 1 | 李聪 | 五一建设 | 13253661015 |
| 2 | 刘新明 | 个体经营 | 13285746958 |
这样在查询订单信息的时候,就可以使用客户编号来引用客户信息表中的记录,也不必在订单信息表中多次输入客户信息的内容,减小了数据冗余。