早前写的原子测试demo,一直挂在心头准备来篇介绍文章。
今天在编译服务器中找了半天还是没找到,最后总算在个人PC中找到了,再不做总结的话可能哪天真会不小心误删了。
代码已上传到这里,有需要的可以拿去测试(本人的demo大多基于Android4.4进行编译和调试,在其他版本上可能出现编译问题)。
1. 背景
多个线程访问同一个资源时,出现并发访问(读和写)问题,如果对资源的管理不合理,可能出现跟预期不同的结果。
例如,多个线程同时对某个全局变量进行自增操作,这个自增操作至少涉及三条指令:
- 从内存单元读入寄存器
- 在寄存器中对变量操作(加/减1)
- 把新值写回到内存单元
如果一个线程执行上面三个步骤过程中,其他线程进入,则会打断前一个的执行动作,导致结果不为预期值。
因此,需要将这几个动作作为原子操作,来加以保护。
2. Android平台下的几种锁使用(以自增为例)
2.1. cutils中实现的锁android_atomic_inc()
其实是对android_atomic_add()的一层封装,参考这里。


2.2. bionic中实现的锁__atomic_inc()
其实是对__sync_fetch_and_add()的一层封装,参考这里。

2.3. bionic中实现的互斥锁pthread_mutex_lock()
其实现参考这个文件。

这个与前两个使用场景有些差异,前面两个主要用于对某个内存变量进行原子操作,这个除具有这个功能外,还可以保护临界资源,
使先拿到锁的线程先运行,只有当释放锁后其他线程才能访问。
3. 性能对比
这几种锁的性能如何呢?参考demo,接下来分几种场景我对其进行对比。
源码如下:


1 #define LOG_TAG "AtomicTester" 2 #include <utils/Log.h> 3 4 #include <sys/atomics.h> 5 6 #include <utils/Atomic.h> 7 8 #define USE_ATOMIC_TYPE 1 //1-cutils; 2-bionic; 3-others(mutex) 9 #define THREAD_COUNT 10 10 #define ITERATION_COUNT 500000 11 12 #define TEST_BIONIC 13 #ifdef TEST_BIONIC 14 extern int __atomic_cmpxchg(int old, int _new, volatile int *ptr); 15 extern int __atomic_swap(int _new, volatile int *ptr); 16 extern int __atomic_dec(volatile int *ptr); 17 extern int __atomic_inc(volatile int *ptr); 18 #endif 19 20 static pthread_mutex_t waitLock = PTHREAD_MUTEX_INITIALIZER; 21 static pthread_cond_t waitCond = PTHREAD_COND_INITIALIZER; 22 23 24 #define TEST_MUTEX // not define it will cause wrong result when multi-threads ops the same var. 25 26 #ifdef TEST_MUTEX 27 static pthread_mutex_t incLock = PTHREAD_MUTEX_INITIALIZER; 28 static pthread_mutex_t decLock = PTHREAD_MUTEX_INITIALIZER; 29 static pthread_mutex_t addLock = PTHREAD_MUTEX_INITIALIZER; 30 #endif 31 32 static volatile int threadsStarted = 0; 33 34 /* results */ 35 static int incTest = 0; 36 static int decTest = 0; 37 static int addTest = 0; 38 static int andTest = 0; 39 static int orTest = 0; 40 static int casTest = 0; 41 static int failingCasTest = 0; 42 43 /* 44 * Get a relative time value. 45 */ 46 static int64_t getRelativeTimeNsec() 47 { 48 #define HAVE_POSIX_CLOCKS 49 #ifdef HAVE_POSIX_CLOCKS 50 struct timespec now; 51 clock_gettime(CLOCK_MONOTONIC, &now); 52 return (int64_t) now.tv_sec*1000000000LL + now.tv_nsec; 53 #else 54 struct timeval now; 55 gettimeofday(&now, NULL); 56 return (int64_t) now.tv_sec*1000000000LL + now.tv_usec * 1000LL; 57 #endif 58 } 59 60 61 /* 62 * Non-atomic implementations, for comparison. 63 * 64 * If these get inlined the compiler may figure out what we're up to and 65 * completely elide the operations. 66 */ 67 #define USE_NOINLINE 0 68 #if USE_NOINLINE == 1 69 static void incr() __attribute__((noinline)); 70 static void decr() __attribute__((noinline)); 71 static void add(int addVal) __attribute__((noinline)); 72 static int compareAndSwap(int oldVal, int newVal, int* addr) __attribute__((noinline)); 73 #else 74 static void incr() __attribute__((always_inline)); 75 static void decr() __attribute__((always_inline)); 76 static void add(int addVal) __attribute__((always_inline)); 77 static int compareAndSwap(int oldVal, int newVal, int* addr) __attribute__((always_inline)); 78 #endif 79 80 static void incr() 81 { 82 #ifdef TEST_MUTEX 83 pthread_mutex_lock(&incLock); 84 #endif 85 incTest++; 86 #ifdef TEST_MUTEX 87 pthread_mutex_unlock(&incLock); 88 #endif 89 } 90 static void decr() 91 { 92 #ifdef TEST_MUTEX 93 pthread_mutex_lock(&decLock); 94 #endif 95 decTest--; 96 #ifdef TEST_MUTEX 97 pthread_mutex_unlock(&decLock); 98 #endif 99 } 100 static void add(int32_t addVal) 101 { 102 #ifdef TEST_MUTEX 103 pthread_mutex_lock(&addLock); 104 #endif 105 addTest += addVal; 106 #ifdef TEST_MUTEX 107 pthread_mutex_unlock(&addLock); 108 #endif 109 } 110 static int compareAndSwap(int32_t oldVal, int32_t newVal, int32_t* addr) 111 { 112 #ifdef TEST_MUTEX 113 pthread_mutex_lock(&addLock); 114 #endif 115 if (*addr == oldVal) { 116 *addr = newVal; 117 #ifdef TEST_MUTEX 118 pthread_mutex_unlock(&addLock); 119 #endif 120 return 0; 121 } 122 #ifdef TEST_MUTEX 123 pthread_mutex_unlock(&addLock); 124 #endif 125 return 1; 126 } 127 128 /* 129 * Exercise several of the atomic ops. 130 */ 131 static void doAtomicTest(int num) 132 { 133 int addVal = (num & 0x01) + 1; 134 135 int i; 136 for (i = 0; i < ITERATION_COUNT; i++) { 137 if (USE_ATOMIC_TYPE == 1) { //cutils, duration=865ms on ARM_CPU_PART_CORTEX_A53 138 android_atomic_inc(&incTest); // wrapper for android_atomic_add(1, addr) 139 android_atomic_dec(&decTest); 140 android_atomic_add(addVal, &addTest); 141 142 int val; 143 do { 144 val = casTest; 145 } while (android_atomic_release_cas(val, val+3, &casTest) != 0); 146 //} while (android_atomic_cmpxchg(val, val+3, &casTest) != 0); 147 do { 148 val = casTest; 149 } while (android_atomic_acquire_cas(val, val-1, &casTest) != 0); // same with release_cas 150 } else if (USE_ATOMIC_TYPE == 2) { //bionic, duration=650ms 151 __atomic_inc(&incTest); // wrapper for __sync_fetch_and_add(addr, 1), which is gcc built-in API 152 __atomic_dec(&decTest); 153 __sync_fetch_and_add(&addTest, addVal); 154 155 int val; 156 do { 157 val = casTest; 158 } while (android_atomic_release_cas(val, val+3, &casTest) != 0); 159 do { 160 val = casTest; 161 } while (android_atomic_acquire_cas(val, val-1, &casTest) != 0); 162 } else { //mutex, noinline_duration=3500ms, inline_duration=28000ms 163 //usleep(1); // if no sleep, result may be right; when have sleep, result must be wrong! 164 incr(); 165 decr(); 166 add(addVal); 167 168 int val; 169 do { 170 val = casTest; 171 } while (compareAndSwap(val, val+3, &casTest) != 0); 172 do { 173 val = casTest; 174 } while (compareAndSwap(val, val-1, &casTest) != 0); 175 } 176 } 177 } 178 179 /* 180 * Entry point for multi-thread test. 181 */ 182 static void* atomicTest(void* arg) 183 { 184 pthread_mutex_lock(&waitLock); 185 threadsStarted++; 186 ALOGD("thread[%d] wait to run...", (int)arg); 187 pthread_cond_wait(&waitCond, &waitLock); 188 pthread_mutex_unlock(&waitLock); 189 doAtomicTest((int) arg); 190 191 return NULL; 192 } 193 194 static void doBionicTest() 195 { 196 #ifdef TEST_BIONIC 197 /* 198 * Quick function test on the bionic ops. 199 */ 200 int prev; 201 int initVal = 7; 202 prev = __atomic_inc(&initVal); 203 __atomic_inc(&initVal); 204 __atomic_inc(&initVal); 205 ALOGD("bionic __atomic_inc: %d -> %d ", prev, initVal); 206 prev = __atomic_dec(&initVal); 207 __atomic_dec(&initVal); 208 __atomic_dec(&initVal); 209 ALOGD("bionic __atomic_dec: %d -> %d ", prev, initVal); 210 prev = __atomic_swap(27, &initVal); 211 ALOGD("bionic __atomic_swap: %d -> %d ", prev, initVal); 212 int swap_ret = __atomic_cmpxchg(27, 72, &initVal); 213 ALOGD("bionic __atomic_cmpxchg: %d (%d) ", initVal, swap_ret); 214 #endif 215 } 216 217 int main(void) 218 { 219 ALOGW("-------------AtomicTester begin--------------"); 220 221 pthread_t threads[THREAD_COUNT]; 222 void *(*startRoutine)(void*) = atomicTest; 223 int64_t startWhen, endWhen; 224 225 #if defined(__ARM_ARCH__) 226 ALOGD("__ARM_ARCH__ is %d", __ARM_ARCH__); 227 #endif 228 #if defined(ANDROID_SMP) 229 ALOGD("ANDROID_SMP is %d", ANDROID_SMP); 230 #endif 231 ALOGD("Creating threads..."); 232 233 int i; 234 for (i = 0; i < THREAD_COUNT; i++) { 235 void* arg = (void*) i; 236 if (pthread_create(&threads[i], NULL, startRoutine, arg) != 0) { 237 ALOGD("thread create failed"); 238 } 239 } 240 241 /* wait for all the threads to reach the starting line */ 242 while (1) { 243 pthread_mutex_lock(&waitLock); 244 if (threadsStarted == THREAD_COUNT) { 245 ALOGD("Starting test!"); 246 startWhen = getRelativeTimeNsec(); 247 pthread_cond_broadcast(&waitCond); 248 pthread_mutex_unlock(&waitLock); 249 break; 250 } 251 pthread_mutex_unlock(&waitLock); 252 usleep(100000); 253 } 254 255 for (i = 0; i < THREAD_COUNT; i++) { 256 void* retval; 257 if (pthread_join(threads[i], &retval) != 0) { 258 ALOGE("thread join (%d) failed ", i); 259 } 260 } 261 262 endWhen = getRelativeTimeNsec(); 263 if (USE_ATOMIC_TYPE == 3) { 264 ALOGD("test pthread_mutex_t with %s", USE_NOINLINE==1 ? "noinline":"always_inline"); 265 } 266 ALOGD("TYPE=%d, All threads stopped, duration time is %.6fms ", 267 USE_ATOMIC_TYPE, (endWhen - startWhen) / 1000000.0); 268 269 /* 270 * Show results; expecting: 271 * 272 * incTest = 5000000 273 * decTest = -5000000 274 * addTest = 7500000 275 * casTest = 10000000 276 */ 277 ALOGD("incTest = %d ", incTest); 278 ALOGD("decTest = %d ", decTest); 279 ALOGD("addTest = %d ", addTest); 280 ALOGD("casTest = %d ", casTest); 281 282 doBionicTest(); 283 284 ALOGW("-------------AtomicTester end--------------"); 285 286 return 0; 287 }
测试手段:10个线程,同时操作同一个全局变量,操作次数为50k次,测算耗时。
测试时,通过宏#define USE_ATOMIC_TYPE 1 来控制测试方法的选择。
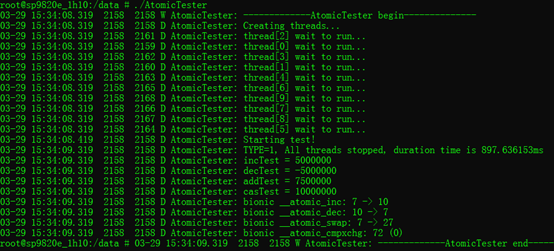
3.1. 使用cutils实现的原子操作函数:
3.2. 使用bionic中实现的原子操作函数(其实是gcc build-in api):

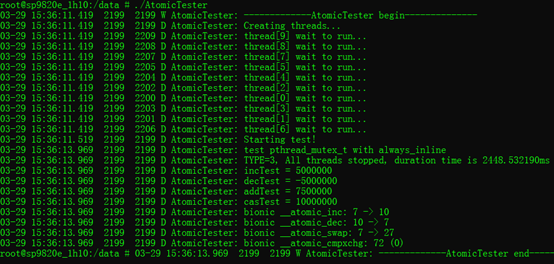
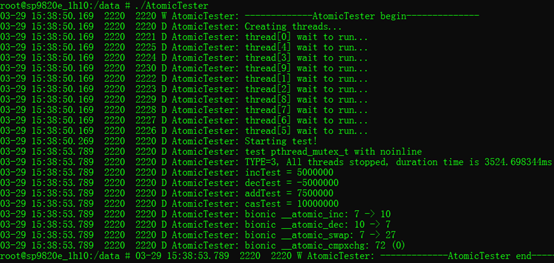
3.3. 使用常用的pthread_mutex_t来保护全局变量:
测试inline:(无函数调用开销,速度快)
测试no-inline:(有函数调用开销,速度稍慢)
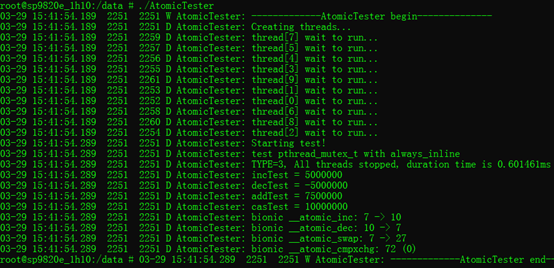
3.4. 不使用任何锁来保护:(结果可能出错)
3.5. 不使用任何锁来保护+sleep:(结果一定出错)
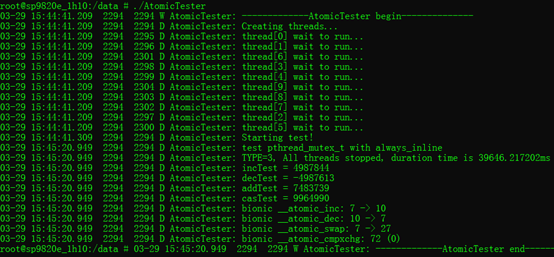
3.6. pthread_mutex_lock+sleep:
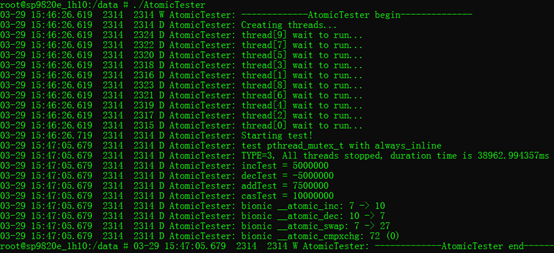
经以上对比,可以得到,速度方面:__atomic_inc() > android_atomic_inc() > pthread_mutex_lock()
其他补充:
- 编译器gcc的build-in实现__sync_fetch_and_add()性能最好。
- 测试机器硬件平台为Cortex-A53。
- inline函数因为少了函数调用开销,速度较快,但会导致代码膨胀,因为其是在“预-编-汇-链”步骤中的预处理阶段进行了代码展开。
- 对变量自增操作,如果不加锁或不用原子操作,结果仍有可能正确,毕竟自增操作的几条指令被别的线程打断的概率非常低(另外一个极端的猜测是——在一个cpu时间片周期内,就做完了50k的自增,这样不被打断时结果就不出错了)。 但是,不加锁并且sleep,被打断的概率非常大,参考3.5的测试结果,导致结果出错(其实解释起来也有点牵强,在sleep将要执行前,自增操作的几条指令已经全部完成)。
- 加sleep()会导致耗时大大增加,因为其休眠时长不精确,再扩大50k倍后,导致耗时非常大。但是,usleep(1)不精确,即使扩大5倍后,单个线程执行耗时为:5us*50k=250ms,最后10个线程累加为:250ms*10=2.5s,但是3.5/3.6的测试显示总耗时大约为:39s,因此猜测得出下条的结论:
- sleep是线程被调用时,让出系统资源,放弃当前cpu时间片并阻塞指定时间,让其他线程可以占用cpu。因此,耗时增加如此之多,大概就是大部分时间耗在了线程上下文切换上,每自增一次,线程抢占一次。但是,这个分析可能有误,因为top看cpu占用时,远低于100%,如果不sleep的话,基本上就是100%。后面需要辅助用其他手段来求证。。。
- 关于cpu切换时间片的一点说明,时间片设得太短会导致过多的进程切换,降低了CPU效率;而设得太长又可能引起对短的交互请求的响应变差。将时间片设为100毫秒通常是一个比较合理的折衷。