OO第一单元总结——表达式求导
第一单元的三次作业都围绕着表达式求导,通过迭代开发的方式完成了支持幂函数和三角函数(仅包括sin和cos)及其嵌套的表达式求导程序。下面是我对这一单元学习的一个总结。
第一次作业
基本思路
本次作业难度较低,只要求了简单幂函数的求导,我使用了四个类来完成,分别为主类、解析器类、项类和多项式类。
-
数据存储
分别通过项类和多项式类完成。每个项对象存储一个幂函数项,包括其指数和系数;多项式类中用一个TreeSet对象存储若干个项,构成多项式。 -
输入
主类中获取输入,交给单独的解析器类进行解析;分别通过正则表达式获取系数、指数和常数,将其组成项和多项式。 -
求导
在主类中调用多项式类的求导方法,分别对TreeSet中的每一项调用各自的求导方法,获取求导结果后创建新的TreeSet,并更新类内的域。 -
输出
在主类中调用多项式类的输出方法,分别获得TreeSet中每一项的输出字符串,将其连接并输出。 -
化简
本次作业化简较为简单,主要包括合并同类项和正项提前输出。- 合并同类项
使用TreeSet的特性,当添加新项失败时,将其合并。 - 正项提前输出
在多项式类的输出方法中创建一个“首项为正”boolean标记,当标记为假时若遇到正项则将其加至字符串首,然后将标记转为真。
- 合并同类项
基于度量的代码结构分析
第一次作业UML图如下:
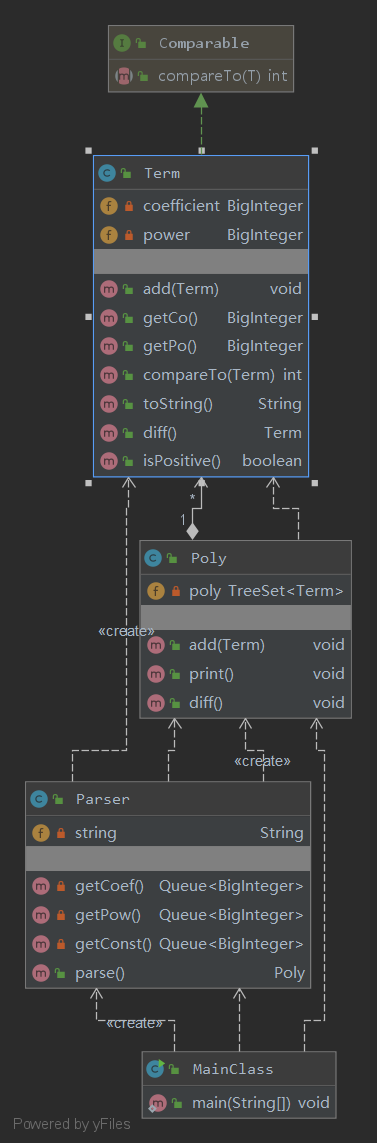
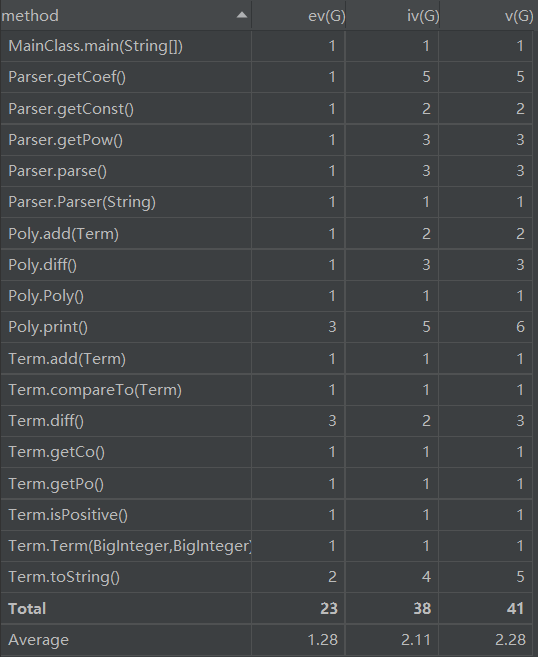
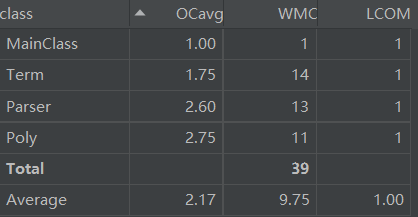
Bug及性能分析
本次作业在公测和互测中均未发现bug,化简也很到位,在强测中获得了满分。
互测构造策略
在本次作业的互测中,我尝试手动构造了一些样例,但都没有hack到。最后整个room中都没有bug发现,应该是确实没有什么bug。
第二次作业
基本思路
本次作业中新增了因子之间的乘法运算和sin、cos两个三角函数。可以注意到本次作业有很明显的表达式-项-因子三层结构,因此我使用了五个类,采用了先分割输入再依次解析的方法,却没有考虑到可扩展性,直接导致了第三次作业的重构。
-
数据存储
最基本的单元为因子,存储其系数(仅限于常数项)、指数;由于没有采用继承和多态,在因子对象中还需要一个类型域,以标识是幂函数,常数还是三角函数。
项类中存储一个因子的TreeSet,表达式中存储一个项的HashSet,构成三级结构。 -
输入
还是由主类获取输入,然后交给解析器类解析。解析的过程如下:- 预处理:将空白项清除,将
**替换,将连续的正负号处理为单独的正负号 - 分割:根据
+-将表达式分割为项;根据*将项分割为因子 - 解析:将每个得到的因子字符串解析为因子对象,根据已经得到的表达式-项-因子结构将其重建。
- 预处理:将空白项清除,将
-
求导和输出
和第一次作业一样,通过主类调用多项式对象的相应方法,多项式对象再依次调用项对象的相应方法,每个项再依次调用因子的相应方法。 -
化简
本次作业除了第一次作业中的合并同类项和正项提前输出之外,新增了由(sin^2x+cos^2x=1)带来的化简可能。我采用的方法是通过多次遍历各项,找出可能的化简情况同时化简。如果在完整的一次遍历之后都没有找到可化简的地方,就结束化简过程。
基于度量的代码结构分析
第二次作业UML图如下:
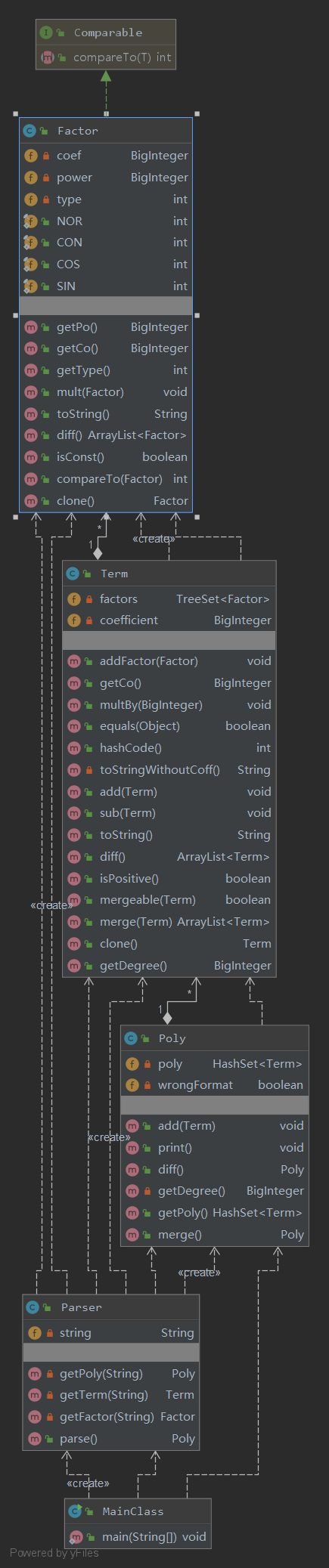
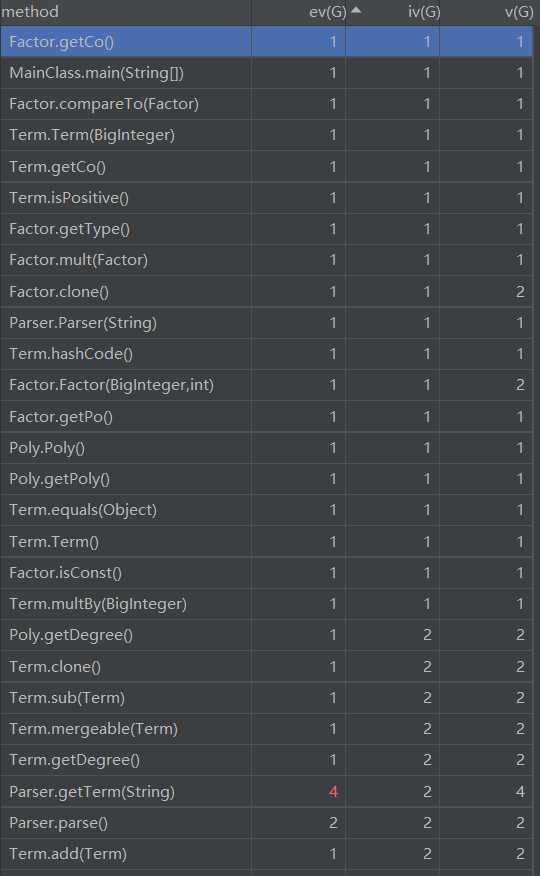
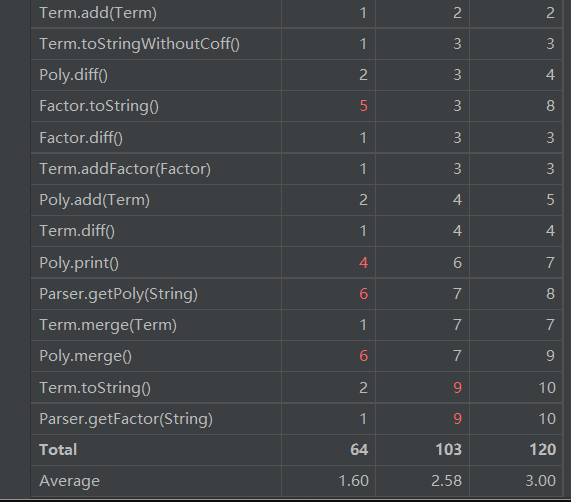
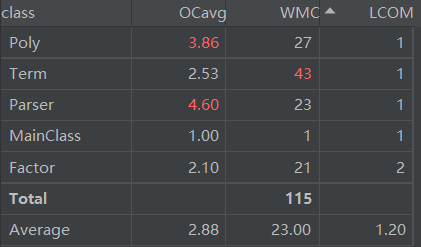
Bug及性能分析
本次作业在公测中未发现bug,在互测中发现了一个bug,是由于对-+-的正负号化简错误。本次作业化简较为成功,在强测中获得了94分,一些地方如(1-cos^2x)没有考虑到化简。
互测构造策略
本次互测中只查出一个bug,是由于其在对输入幂函数指数10000的限制,误将整个过程中的指数均限制在10000以下。这也是我在开始犯得一个错误,归根结底是没有仔细阅读指导书。根据自己在完成作业时的错误去寻找他人的错误也是一个不错的方法。
第三次作业
基本思路
第三次作业难度大大提升,增加了表达式的嵌套,这也使得我之前的架构基本失效,只能进行重构。本次作业我使用了12个类。
-
数据存储
本次作业中有10个类是数据类,分别为项抽象类,幂函数、常数、sin函数、cos函数基本类,混合项抽象类,二项加法、乘法类(用于处理输入),多项加法、乘法类(用于求导、化简和输出)。 -
输入
本次作业我采取了上学期数据结构课程中学到的栈解析中缀表达式的算法,首先将幂函数、常数、sin函数、cos函数找到并存在队列中,将原表达式按照类型换为单个字母(如2x+sin((x**2+x))化为np+s),再将字母当作单个操作数进行解析,最终得到表达式树。 -
二元项化多元项
通过递归的方式,将二元的加法、乘法项化为多元的相应项。 -
求导
我在本次作业中曾尝试在将二元项化为多元项之前进行求导,但测试发现其时间需求过高,于是采用了先化为多元项再求导的方法,时间复杂度得到显著下降。求导方法按照多态的思想,根据不同的类型而不同。 -
化简
本次作业可化简的部分实在太多,综合考虑我只进行了合并同类项和提公因式两方面,三角函数的相关化简就放弃了。在我的架构下,可合并的部分是加法项和乘法项。其中乘法项只需考虑合并同类(因为不允许表达式带指数),加法项需要考虑合并同类项和提公因式,其实在原理上是一致的。
化简的思路还是通过若干次遍历,找到可合并的两项,如果在一次完整的遍历中没有合并点,就结束化简。对于乘法项,找到合并点后可以结束遍历直接化简,而加法项则需要找到化简程度最大的两项进行化简。 -
输出
各方面考虑下,我为每个类设计了一个获取系数的方法和一个获取除系数外部分字符串的方法,在项抽象类中编写toString()方法将二者合并为输出。
基于度量的代码结构分析
第三次作业UML图如下:

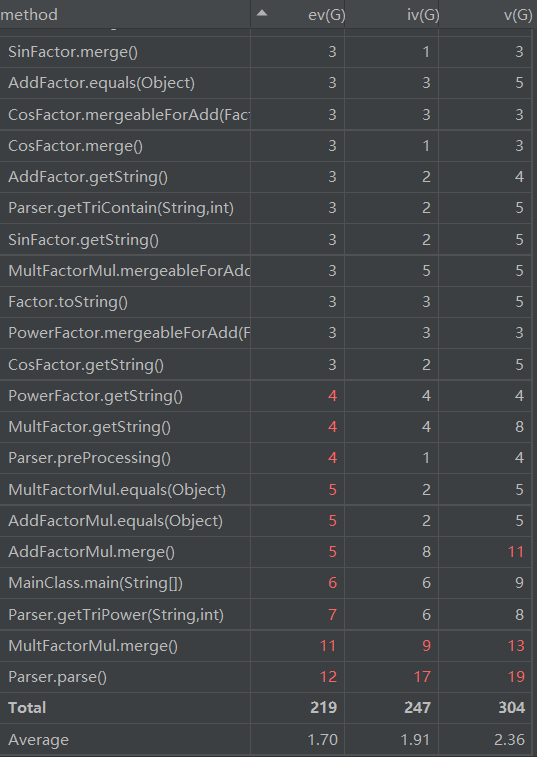

Bug及性能分析
本次作业在公测中出现了两个问题,得分70分,在互测中也出现了其中的一个问题。一个非常低级的错误是我由于思维惯性,在对输出进行化简时还依照前两次作业,将x**2化简为x*x,直接导致x*x单独出现在三角函数中时的格式错误。公测一共WA了6个点,有5个都是因为这个格式错误。另一个Bug是对于栈解析表达式算法的错误,在回忆时出现了偏差。性能方面,我的化简还是很成功的,在强测通过的点中性能分均为满分。
互测构造策略
本次互测中共hack到11个点,主要还是依照自己在完成作业过程中发生的问题进行构造样例;此外,还构造了一些大量嵌套的样例,然而并没有hack到TLE,反倒hack到了一些格式错误。
应用对象创建模式重构
其实第三次作业很适合使用工厂模式,只是当时对工厂模式优越性的理解还不够,就没有采用,而是将从输入的字符串到表达式树的过程全部放在一个解析器类中,造成了极大的复杂度。可以将解析器类进行拆分,令其只进行找出每一个最小单元的任务,剩下的将字符串转为项的工作可以交给工厂完成。这样应该可以大大降低耦合程度。
心得与体会
-
感谢寒假pre作业
寒假的两弹pre作业作为热身,效果还是很不错的。第一是令我开始使用面向对象的思维方式,第二是能熟悉Java语言的基本使用。 -
先想清楚再写代码
在第二次作业中,我看完指导书就打开了第一次作业的代码开始改,结果很显而易见,遇到了大量的bug,添加了无数个补丁才把这个程序稳住。第三次作业如果像这样去做那必然是原地爆炸,所以我还是选择了先想清楚,要使用什么结构,怎样解析输入,使用什么化简算法,等这些大框架定下来之后,写起代码来也会流畅很多,只需要额外处理一些细节问题。只是这两次作业在分数上似乎并不支持这个结论,我选择把它归为偶然。 -
考虑后续任务
也就是保持可扩展性。OO每个单元的作业都是以迭代的方式进行的,如果不在之前的作业中考虑可扩展性,那每次作业都面临着重构,工作量反而会大大提升。
第一单元的学习就这样过去了,不得不说压力还是比较大的,但收获也是很多。希望在接下来的作业中能取得更好的结果。
- 推荐文章
- 系统的结构化分析与设计方法
- 系统需求建模:事件和事物
- software Architecture(3)
- 什么样的男人才算是成熟的男人?
- 如何在人多的稍陌生聚会场合表现得自信、自如、外向?
- 组织行为学4
- 组织行为学3
- software Architecture(2)
- Linux基本命令运行
- 关于spark入门报错 java.io.FileNotFoundException: File file:/home/dummy/spark_log/file1.txt does not exist
- 解决maven项目Invalid bound statement (not found)的方法
- IDEA配置好maven后新建maven项目一直build失败的解决方法
- Unix中的特殊文件及文件属性
- Unix中的特殊文件及文件属性
- unix 基础知识
- unix 基础知识
- leetcode-Container With Most Water
- leetcode
- Effective C++学习笔记 chapter 3
- Effective C++学习笔记 chapter 2
- leetcode Majority Element
- Missing Number 三种解法
- Effective C++学习笔记 chapter 1
- C++ 笔记
- 三色排序
- 归并排序-就地排序
- 506,display有哪些值?说明他们的作用
- 505,display,float,position之间的关系(有疑问)
- 504,什么是FOUC?怎么避免
- 503,display:none;与visibility:hidden;的区别