引言
历史
- 法律问题
- 紧缩政策的兴起
当前档案软件
未来发展
压缩技术
- Run-Length Encoding 游程编码
- Burrow-Length Transform 布鲁斯-惠勒变换
- Entropy Encoding 熵编码法
- Shannon-Fano Coding
- Huffman Coding
- Arithmetic Coding
压缩算法
- Sliding Window Algorithm 滑动窗口算法
- LZ77
- LZR
- DEFLATE
- DEFLATE64
- LZSS
- LZH
- LZB
- ROLZ
- LZP
- LZRW11
- LZJB
- LZS
- LZX
- LZO
- LZMA
- LZMA2
- Dictionary Algorithm 字典算法
- LZ78
- LZW
- ZLC
- LZT
- LZMW
- LZAP
- LZWL
- LZJ
- Non-dictionary Algorithm非字典算法
- PPM
- bzip2
- PAQ
参考资料
无损耗数据压缩算法历史
引言
压缩算法主要有两大类: 有损和无损。有损数据压缩算法通常通过删除需要大量保真数据的小细节来减少文件的大小。在有损数据压缩中。由于删除了基本数据,不可能恢复原始文件。有损数据压缩通常用于存储图像和音频数据,虽然可以通过数据删除实现非常高的压缩比,但本文并未涉及。无损数据压缩是文件的大小减少,这样一个解压函数完全可以恢复原始文件,没有数据丢失。无损数据压缩在计算机中无处不在,从节省个人电脑空间到通过网络发送数据,通过安全shell进行通信,或者查看PNG或GIF图像。
无损数据压缩算法工作原理是,任何非随机文件都包含重复信息,这些信息可以通过使用统计建模技术来浓缩,从而确定字符或短语出现的概率。然后可以使用这些统计模型根据发生概率为特定字符或短语生成代码,并未最常见的数据分配最短的代码。这些技术包括熵编码法、游程编码和使用字典进行压缩。使用这些技术和其他技术,一个8位字符或这种字符的字符串可以用几位表示,从而删除大量冗余数据。
历史
20世纪70年代,互联网变得越来越流行,Lempel-Ziv 算法被发明出来,自从那里以后,数据压缩才在计算机领域发挥了重要作用。但它在计算机之外的历史要悠久的多。莫尔斯电码发明于1838年,是数据压缩最早的例子,因为英语中最常见的字母如'e'和't'被赋予较短的莫尔斯电码。后来,随着大型计算机在1949年开始占据主导地位,Claude Shannon, Robert Fano发明了 Shanno-Fano编码。他们的算法基于符合出现的概率,为给定数据块中符号分配代码。符号出现的概率与代码长度成反比,因此用较短的方式表示数据。[1]
两年后,David Huffman在麻省理工学院学习信息论,并和Robert Fano 一起上课, Fano 让学生选择是写学期论文还是参加期末考试。Huffman 选择了学期论文,该论文是关于寻找最有效的二进制编码方法。在工作了几个月却一无所获之后,huffman准备丢掉它所有的工作,开始为期末开始而学习,而不是写论文。就在那个时候,它突然灵光一现,发现了一种与Shannon-Fano编码非常相似但更有效的计数。Shannon-Fano编码和Huffman编码的关键区别在于,前者的概率树是自下而上构建的,产生的结果不是最优的,而后者是自上而下构建的。[2]
Shannon-Fano和Huffman编码的早期实现都是使用硬件和硬件编码完成的。直到20世纪70年代,随着互联网和在线存储的出现。软件压缩才得以实现,Huffamn编码是基于输入数据动态生成的[1].后来, 在1997年,Abraham Lempel, Jacob Ziv 发表了他们开创性的LZ77算法,这是第一个使用字典数据的算法。更具体地说,LZ77经常使用一种称为滑动窗口的动态字典。[3]1978年,同样是两个人发布了他们的LZ78算法,该算法也使用了字典,与LZ77不同的是,该算法解析输入数据并生成了静态字典,而不是动态生成。[4]
法律问题
LZ77和LZ78算法都迅速流行起来,产生了许多变种,如图所示。
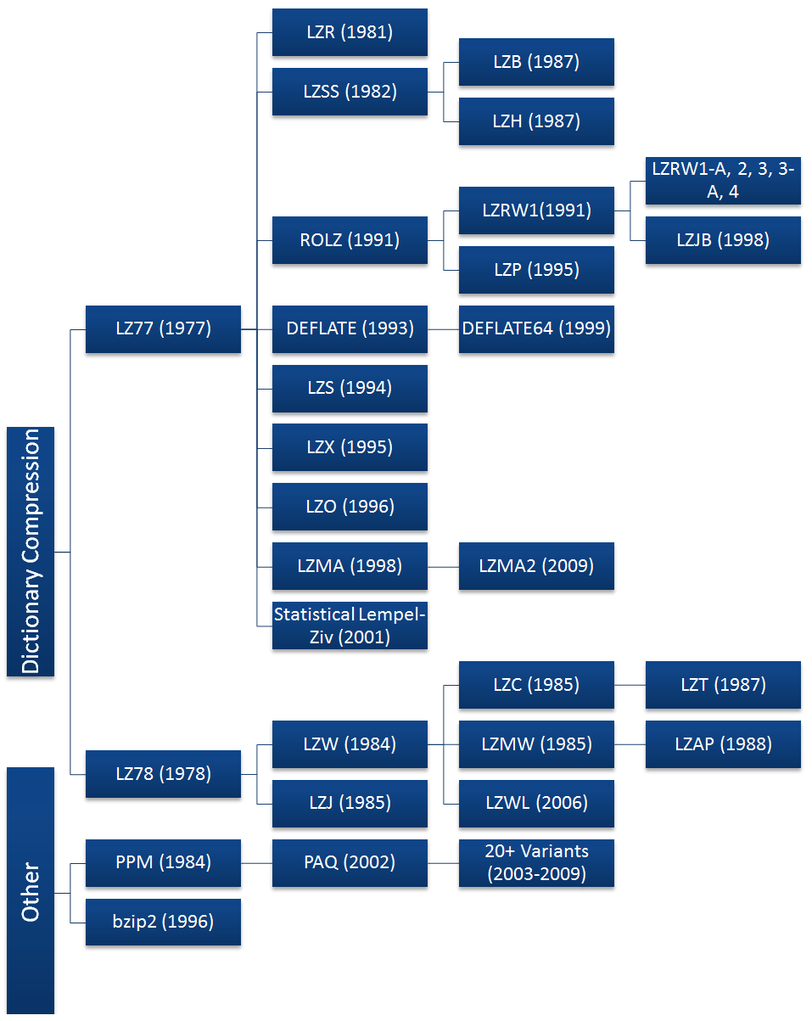 自这些算法被发明以来, 大多数算法已经消亡了,现在只有少数算法被广泛使用,包括DEFLATE, LZMA, LZX.大多数常用算法都是从LZ77算法派生出来的。这不是因为技术上的优越性,而是因为LZ78算法在1984年Sperry申请了衍生物LZW算法的专利,并开始起诉软件供应商、服务器管理员,甚至终端用于在没有许可证的情况下使用GIF格式,之后,就成了专利受限算法[5][6]
自这些算法被发明以来, 大多数算法已经消亡了,现在只有少数算法被广泛使用,包括DEFLATE, LZMA, LZX.大多数常用算法都是从LZ77算法派生出来的。这不是因为技术上的优越性,而是因为LZ78算法在1984年Sperry申请了衍生物LZW算法的专利,并开始起诉软件供应商、服务器管理员,甚至终端用于在没有许可证的情况下使用GIF格式,之后,就成了专利受限算法[5][6]
当时,UNIX压缩使用程序对LZW算法进行了非常小的修改,称为LZC,后来由于专利问题而停止使用。其他UNIX开发人员也开始偏离使用LZW算法,转而使用开源算法。这导致UNIX社区采用了基于deflate的gzip和基于Burrows-Wheeler transform 的 bzip2格式。从长远来看,这对UNIX社区是一个好处。因为gzip和bzip2几乎总是比LZW格式实现更高的压缩比。随着LZW算法的专利在2003年到期。围绕LZW的专利问题已经平息[5].尽管如此,LZW算法已经被很大程序上取代,并且只有在GIF压缩中普遍使用。此后也出现了一些LZW衍生品,但他们也没有得到广泛应用,LZ77算法仍然占据主导地位。
另一场关于LZS算法的法律战于1993年爆发,是由Stac电子公司开发的,用于磁盘压缩软件,比如Stacker.微软使用LZS算法来开发磁盘压缩软件,这款软件是MS-DOS 6.0下发布的。据说可以使磁盘的容量翻一番。当Stac电子发现其知识产权被使用时。他对微软提起了诉讼。微软后来被判有罪,并被判向Stac电子支持1.2亿美元的损害补偿,减去1360万美元的反诉裁定,微软的侵权并非估计[7], 尽管stac电子公司诉微软公司一案有很大的判决,但它并没有像LZW专利纠纷那样阻碍Lempel-Ziv算法的发展。唯一的结果似乎是LZS没有被分配到任何新的算法。