1.1 redis实现排行功能
参考博客:https://www.cnblogs.com/zzliu/p/11787830.html
# -*- coding: utf-8 -*-
# 01.获取redis实例
import redis
main_rds = redis.StrictRedis(host='localhost',port=6379,db=0,password='')
# 02.添加一组测试数据
# 向key为test的zset里面添加一组,如果已经存在就覆盖
main_rds.zadd("test",{"a":1,"b":2,"c":3,"d":5.1,"e":6,"f":7})
# 03.从大到小取出前四大元素排行
r2 = main_rds.zrevrange("test",0,3) # ['f', 'e', 'd', 'c']
print(r2)
# 04.从小到大取出排名在 2到6之间的元素
r3 = main_rds.zrangebyscore("test",2,6) # ['b', 'c', 'd', 'e']
print(r3)
# 05.返回score在给定区间的数量
r4 = main_rds.zcount("test",2,6)
print(r4)
# 06.获取整个zset的元素数量
r5 = main_rds.zcard("test") # 6
print(r5)
# 07.删除key为f的数据
main_rds.zrem("test","f")
# 08.删除最1个名元素
main_rds.zremrangebyrank("test", 0, 1)
# 09.删除score在5~6之间元素
main_rds.zremrangebyscore("test", 5, 6)
1.2 redis实现排行原理
1、前言
1) 实现一个排版榜,我们通常想到的就是mysql的order by 简单粗暴就撸出来了。但是这样真的优雅吗?
2)数据库是系统的瓶颈,这是众所周知的。如果给你一张百万的表,让你排序做排行榜,花费的时间是十分可怕的。
1)我们分析一下排行榜,一个用户一个排名,意味着要去重
2)Redis的ZSet这种结构是可以保住元素唯一以及有序
3、redis有序集合要满足下面两点要求:
1)支持按name来修改score
2)支持以score来排序
所以,zset同时使用字典和跳跃表两个数据结构来保存有序集元素
1.3 字典原理
注:字典类型是Python中最常用的数据类型之一,它是一个键值对的集合,字典通过键来索引,关联到相对的值,理论上它的查询复杂度是 O(1)
1、哈希表 (hash tables)
1. 哈希表(也叫散列表),根据关键值对(Key-value)而直接进行访问的数据结构。
2. 它通过把key和value映射到表中一个位置来访问记录,这种查询速度非常快,更新也快。
3. 而这个映射函数叫做哈希函数,存放值的数组叫做哈希表。
4. 通过把每个对象的关键字k作为自变量,通过一个哈希函数h(k),将k映射到下标h(k)处,并将此对象存储在这个位置。
2、具体操作过程
1. 数据添加:把key通过哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,
将value存储在以该数字为下标的数组空间里。
2. 数据查询:再次使用哈希函数将key转换为对应的数组下标,并定位到数组的位置获取value。
3、{“name”:”zhangsan”,”age”:26} 字典如何存储的呢?
1. 比如字典{“name”:”zhangsan”,”age”:26},那么他们的字典key为name、age,假如哈希函数h(“name”) = 1、h(“age”)=3,
2. 那么对应字典的key就会存储在列表对应下标的位置,[None, “zhangsan”, None, 26 ]
4、解决hash冲突

1.4 有序表的搜索
参考博客:https://www.cnblogs.com/thrillerz/p/4505550.html
1、有序表的搜索
1)考虑一个有序表

2)我们把一些节点提取出来,作为索引
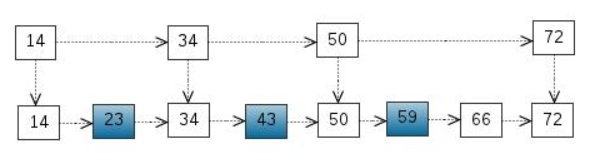
3)我们还可以再从一级索引提取一些元素出来,作为二级索引

1.5 跳表
1、其中 -1 表示 INT_MIN, 链表的最小值,1 表示 INT_MAX,链表的最大值
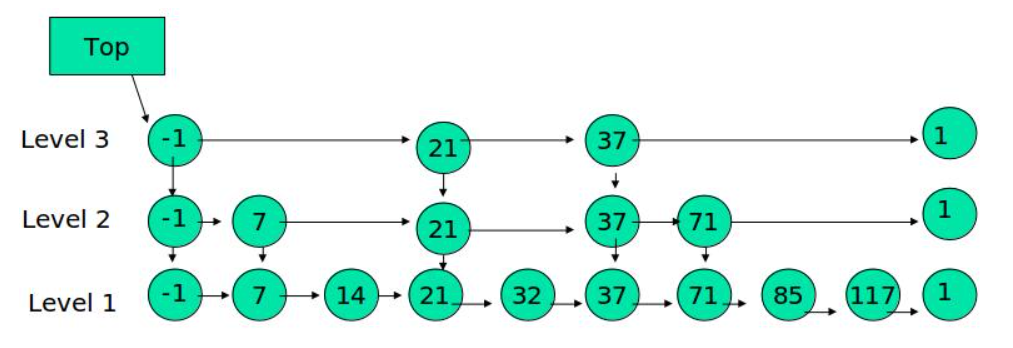
2、跳表具有如下性质:
(1) 由很多层结构组成
(2) 每一层都是一个有序的链表
(3) 最底层(Level 1)的链表包含所有元素
(4) 如果一个元素出现在 Level i 的链表中,则它在 Level i 之下的链表也都会出现。
(5) 每个节点包含两个指针,一个指向同一链表中的下一个元素,一个指向下面一层的元素。
3、跳表搜索
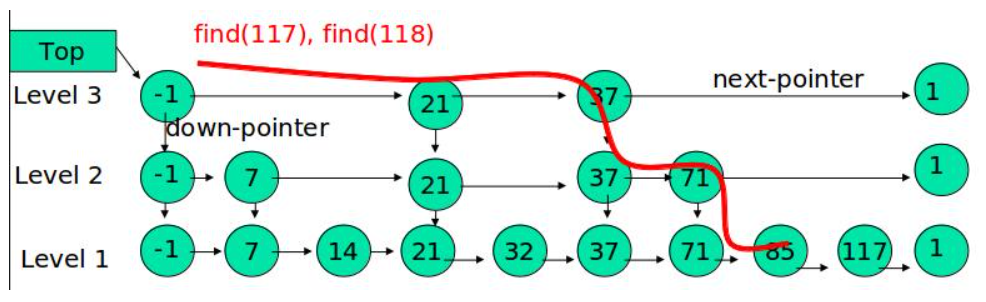
例子:查找元素 117
(1) 比较 21, 比 21 大,往后面找
(2) 比较 37, 比 37大,比链表最大值小,从 37 的下面一层开始找
(3) 比较 71, 比 71 大,比链表最大值小,从 71 的下面一层开始找
(4) 比较 85, 比 85 大,从后面找
(5) 比较 117, 等于 117, 找到了节点。