1. 虚函数表
C++的多态是通过一张虚函数表(virtual Table)来实现的,简称为V-Table,(这个表是隐式的,不需要关心其生成与释放)在这个表中,主要是一个类的虚函数的地址表,这张表解决了继承,覆写的问题,保证其真实反应实际的函数,这样,在有虚函数的类的实例中这个表被分配在了这个实例的内存中,所以,当我们用父类的指针来操作一个子类的时候,这张虚函数表就显得尤为重要了,它就像一个地图一样,指明了实际所应该调用的函数
为了更加形象的对其进行理解,我们用一个实例来对其进行说明
#include <iostream> using namespace std; class Base { public: virtual void f(){cout <<"Base::f"<<endl;} virtual void g(){cout <<"Base::g"<<endl;} virtual void h(){cout <<"Base::h"<<endl;} int a; }; int main() { cout << "Base Size:" <<sizeof(Base)<< endl; return 0; }
最终无论有几个虚函数,最终的大小都是8
为了对这个现象进行解释,我们用下图进行解释
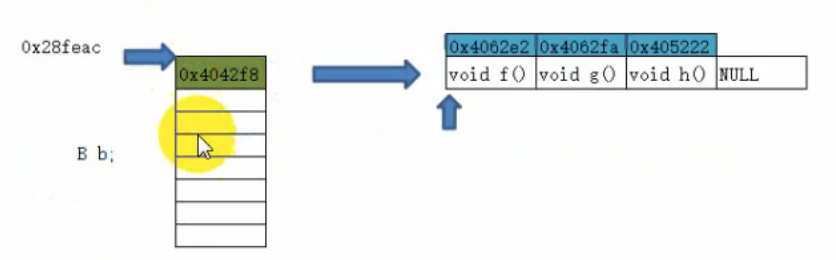
所以说相当于int占了四个字节,然后另外四个字节放了一个地址,这个地址指向一张表,表中的三个就代表三个地址
为了对这个表进行说明,我们写了如下的代码进行说明
#include <iostream> using namespace std; class Base { public: virtual void f(){cout <<"Base::f"<<endl;} virtual void g(){cout <<"Base::g"<<endl;} virtual void h(){cout <<"Base::h"<<endl;} int a; }; typedef void (*FUNC)(); int main() { cout << "Base Size:" <<sizeof(Base)<< endl; Base b; cout<<"对象的起始地址"<<&b<<endl; cout<<"虚函数表的地址"<<(int **)*(int *)&b<<endl; cout<<"虚函数表中第一个函数的地址"<<*((int **)*(int *)&b)<<endl; cout<<"虚函数表中第二个函数的地址"<<*((int **)*(int *)&b+1)<<endl; FUNC pf=(FUNC)(*((int **)*(int *)&b)); pf(); pf=(FUNC)(*((int **)*(int *)&b+1)); pf(); pf=(FUNC)(*((int **)*(int *)&b+2)); pf(); return 0; }
所得到的结果为

对于多态发生的原理,我们可以用以下两段代码来进行比较
#include <iostream> using namespace std; class Base { public: virtual void f(){cout <<"Base::f"<<endl;} virtual void g(){cout <<"Base::g"<<endl;} virtual void h(){cout <<"Base::h"<<endl;} }; class Derive:public Base { virtual void f1(){cout <<"Derive::f1"<<endl;} virtual void g1(){cout <<"Derive::g1"<<endl;} virtual void h1(){cout <<"Derive::h1"<<endl;} }; typedef void (*FUNC)(); int main() { cout << "Base Size:" <<sizeof(Base)<< endl; Derive b; cout<<"对象的起始地址"<<&b<<endl; cout<<"虚函数表的地址"<<(int **)*(int *)&b<<endl; cout<<"虚函数表中第一个函数的地址"<<*((int **)*(int *)&b)<<endl; cout<<"虚函数表中第二个函数的地址"<<*((int **)*(int *)&b+1)<<endl; FUNC pf=(FUNC)(*((int **)*(int *)&b)); pf(); pf=(FUNC)(*((int **)*(int *)&b+1)); pf(); pf=(FUNC)(*((int **)*(int *)&b+2)); pf(); pf=(FUNC)(*((int **)*(int *)&b+3)); pf(); pf=(FUNC)(*((int **)*(int *)&b+4)); pf(); pf=(FUNC)(*((int **)*(int *)&b+5)); pf(); return 0; }
得到的结果是

但是若将继承的函数改为覆写,即
class Base { public: virtual void f(){cout <<"Base::f"<<endl;} virtual void g(){cout <<"Base::g"<<endl;} virtual void h(){cout <<"Base::h"<<endl;} }; class Derive:public Base { virtual void f(){cout <<"Derive::f1"<<endl;} virtual void g1(){cout <<"Derive::g1"<<endl;} virtual void h1(){cout <<"Derive::h1"<<endl;} };
得到的结果为

我们从表中可以看到下面几点
(1)覆写的f()函数被放到了虚表中原来父类虚函数的位置
(2)没有被覆盖的函数依旧
只要是虚函数,那么就先来遍历那张函数表,如果不是虚函数,则本来是什么就是什么
静态代码发生了什么
当编译器看到这段代码时,并不知道b的真实身份,编译器能做的就是用一段代码代替这段语句
Base *b=new Derive(); b->f();
调用过程实际上是遍历虚函数表的过程,在编译的时候,b不知道自己的真实身份(因为运行的时候其不知道谁赋给她),但是它调用的时候有一个b->f(),类似于一个指向类成员的指针,其记录了一个偏移

在这里,f偏移了0个单位,g()偏移了1个单位,h()偏移了2个单位,g1()偏移了3个单位
刚开始并不知道指向哪里,只是说会给他一张表,里面放了地址,需要时直接去表里找
(1)明确b类型
(2)然后通过指针虚函数表的指针vptr和偏移量,匹配虚函数的入口
(3)根据入口地址调用虚函数
对多态的评价
(1)实现了动态绑定
(2)些许的牺牲了一些空间和效率,也是值得的
为什么构造函数不能为虚函数
编译不过
注意,当基类的构造函数内部有虚函数时,会出现什么情况呢?结果是在构造函数中,虚函数机制不起作用了,调用虚函数如同调用一般的成员函数一样,当基类的析构函数内部有虚函数时,又如何工作呢?与构造函数相同,只有局部版本的被调用。但是,行为相同,原因是不一样的,构造函数只能调用局部版本,是因为调用时还没有派生类版本的信息,析构函数则是因为派生类版本的信息已经不可靠了。我们知道,析构函数的调用顺序与构造函数相反,是从派生类的析构函数到基类的析构函数,当某个类的析构函数被调用时,其派生类的析构函数已经被调用了,相应的数据也已被丢失,如果再调用虚函数的派生类的版本,就相当于对一些不可靠的数据进行操作,这是非常危险的,因此,在析构函数中,虚函数机制也是不起作用的
#include <iostream> using namespace std; class A { public: A() { p=this; p->func(); } virtual void func() { cout<<"xxxxxxxxxxx"<<endl; } private: A *p; }; class B:public A { public: void func() { cout<<"oooooooooooo"<<endl; } }; int main() { B b; return 0; }
在这里最终的结果为xxxxxxxxxxxx,因为在生成的过程中,首先是A的构造函数进行创建,这就造成了其调用时生成的是xxxxxxxxxx
为了说明析构函数析构的顺序,我们举以下的例子
#include <iostream> using namespace std; class A { public: A() { p=this; p->func(); } virtual void func() { cout<<"xxxxxxxxxxx"<<endl; } ~A() { p=this; p->func(); } private: A *p; }; class B:public A { public: void func() { cout<<"oooooooooooo"<<endl; } }; int main() { B b; return 0; }
最终也是生成xxxxxxxxxx的,因为在析构的过程中,会将首先调用B的析构函数,然后再调用A的析构函数,再会进行p->func的调用