BUAA_OO_2020_Unit1_总结
2020年春季学期第四周,OO第一单元落下帷幕,几多欢喜几多愁,现做如下总结(按每次作业的递进顺序)
一、第一次作业(基础的幂函数求导)
- 基于度量的程序结构分析
第一次作业是较为简单的幂函数的求导,由于没有错误格式的数据出现,我们处理源字符串的方式也变得尤为简单。存储表达式的数据结构也可简化为已有的数据结构。本人初采用的Hashmap来简化输入数据的化简检索步骤,后由于考虑优化时的系数排序情况,又将数据结构换成了Treemap,在此过程中多体会到了常用数据结构,如ArrayList,HashMap,TreeMap之间的不同优缺点。
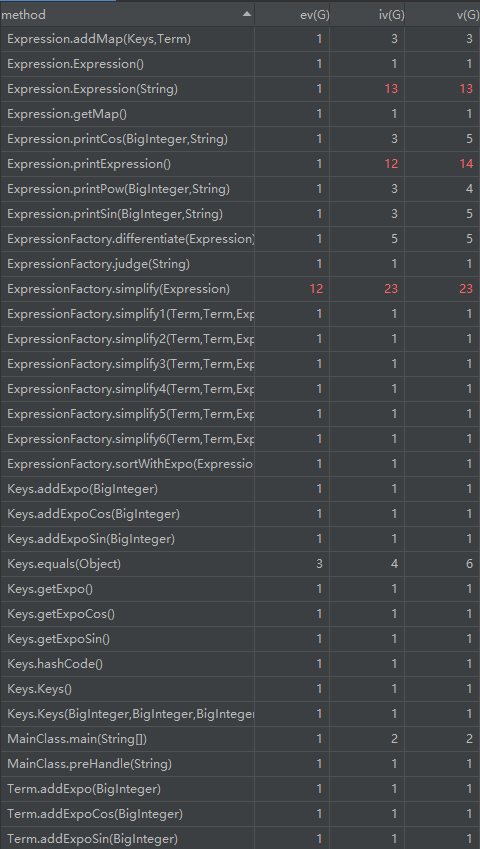
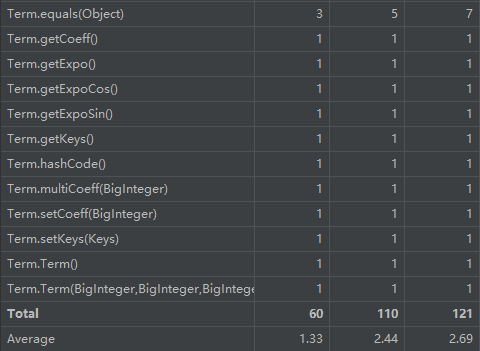
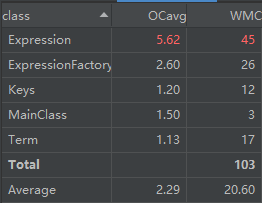
而对于面向对象思想的训练,本人初步仅使用了项,以及表达式的类来创建表达式对象,而对于表达式的求导部分则单独放在了一个工厂类之中用来表示对表达式的加工。代码分析如下
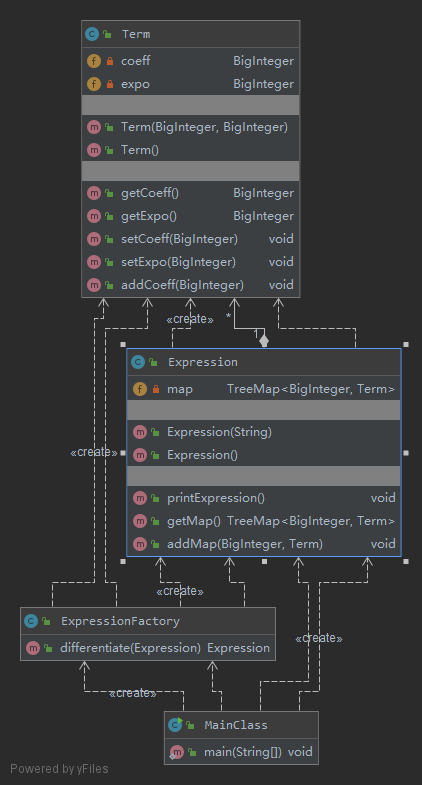

对于方法中的分析,表达式的构建以及输出的圈复杂度较高,具体原因可能在于输出的简化判断过程,而这个复杂度随着作业的迭代会逐渐提升,如何降低其复杂度,符合“高内聚,低耦合”的程序特性,也是本人下一步需要提高思考的地方。
- 评测
在第一单元中强测中未发现bug,在互测之中由于构造些特殊条件,如“0”,负数次幂,导致成功hack到了同room的同学,这些特殊条件也是我测试自己代码时留下的测试用例。
二、第二次作业(引入三角函数及因子的乘积)
第二次作业也是最让我心碎的一次心路历程,功能性实现本身较为简单。而本人用了极大精力优化输出的同时,却在关键位置留下致命bug,导致强测结果直接爆炸,无力回天。真可谓:为山九仞,功亏一篑。这也提醒本人在优化时更要做好全方位的测试。
- 基于度量的程序结构分析
第二次作业引入了三角函数sin与cos,并且支持因子之间的乘积,而且引入了简单的不包含空白字符的错误输入。这样的条件下需要我们简单的改进我们的策略,对于空白字符我们仍然可以在表达式中进行处理,而错误输入由于表达式本身不存在多于的递归输入(相比于第三次作业),所以我大胆采用了全部表达式的正则构造,在字符串输入初期即判断其是否合理的情况。简化了判断的流程。
而在表达式的构造方面,虽然多引入了形式,但最终的每一项仍然可以表达成a*x^b*sin(x)^c*cos(x)^d的形式,其中abcd为四个系数,只要将四个系数作为属性放入Term类中,并以bcd为属性放入Keys中作为HashMap整体的Key索引,HashMap就仍然可以作为我们表达式构建的数据结构。再重新改造一下我们的输出以及求导方法,第二次作业的迭代工作就完成了,具体的代码分析如下:
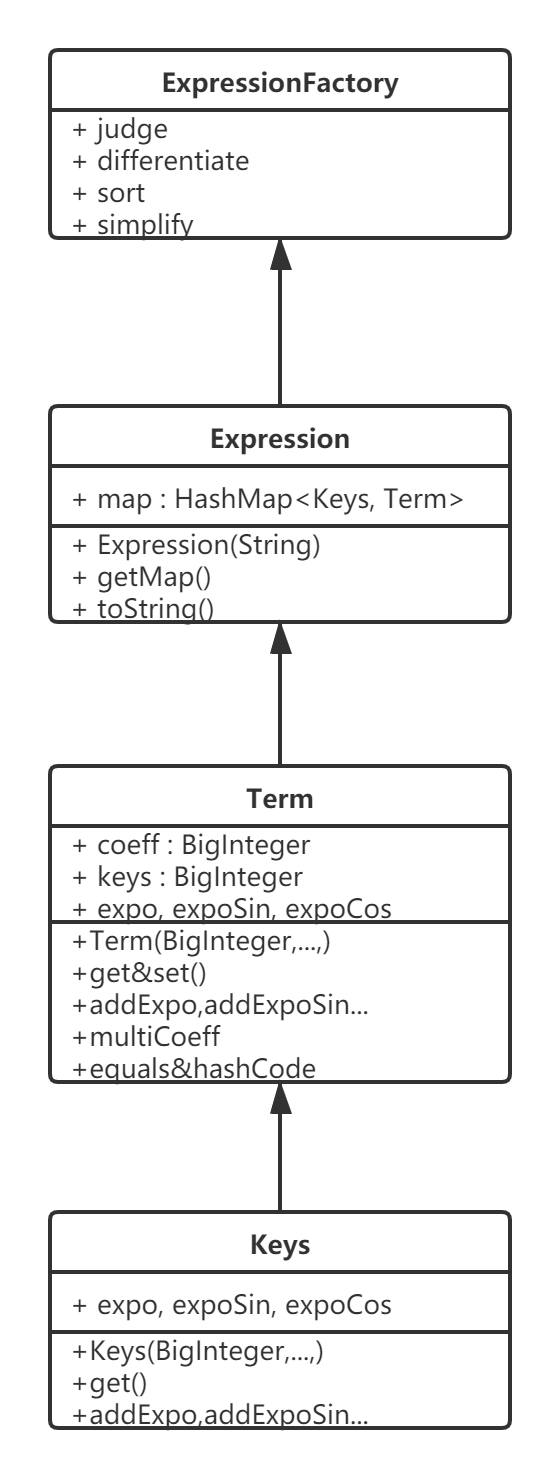
UML图
相较于第一次作业,第二次作业的圈复杂度也体现在了化简之中(除第一次作业的化简策略)。我采用的化简策略是扫描任意两项,观察其是否符合:
-
- x的指数相等
- sin,cos指数分别相差2/sin差2/cos差2
本人的大量计算以及分析得出这种化简策略的优化绝大多数情况都为正向,强测通过的样例获得的性能分也较为理想,但本人在遍历项的过程中,产生的优化,并未对已优化的项处理,导致下一次遍历仍会触及,这样致命的bug在提交之后才猛然发现,却已为时已晚。不禁对自己强测可怜的分数扼腕叹息。
- 评测
本人毫无意外的被分进了C屋,也发现了很多同屋人的bug,战况十分惨烈,但同屋的人并未hack出我的问题,(自己还是有几分小侥幸),构造出的测试样例包含简单的多符号处理,以及基本的常数情况等等,本身不是很具有代表性再次不赘述。
三、第三次作业(引入嵌套)
造成第三次作业难度激增的一个“罪魁祸首”就是嵌套规则,但我们仍有消除恐惧的办法。在构建表达式树的过程中本人深深体会到了大一下数据结构的重要性。
在与同学深切的讨论(其实是向大佬取经)之后,我沿袭其构造思想。将整体思路表述如下:
1)对于整体字符串构造正则表达式,对于嵌套内容利用“(.*)"进行构造,目的为仅仅检查最外层的逻辑,符号是否正确。而对于其中具体的项、因子,我会在构造之中进行同步的检查。若符合则构造,不符合则报错。
2)在构造过程中,先将项之间的符号处理成一个,再扫描表达式,以"+-" > "*" > "嵌套”的优先级进行构造,其中嵌套包含的“+-”号需要特殊考虑。在扫描的过程中按照不同的优先级,构造分支节点类型,再将左子树,右子树构造的字符串提取出来,递归进行下一层树的构建。
3)构造好之后对树进行中序遍历,访问叶子节点就输出其求导结果,访问分支节点就读取其符号类型,进行不同的求导规则递归调用,如“*”,就递归调用“左子树求导 * 右子树输出 + 左子树输出 * 右子树求导”,其中的括号问题,则针对优先级进行填充,若父节点优先级较高,则在自述输出时为其填充括号。
在化简的思路上,由于在构造过程中耗费大量心血,化简我仅仅考虑了符号的减少输出以及项中包含0,包含常数时求导结果的化简,取到了一些成果,但仍有较大的优化空间。
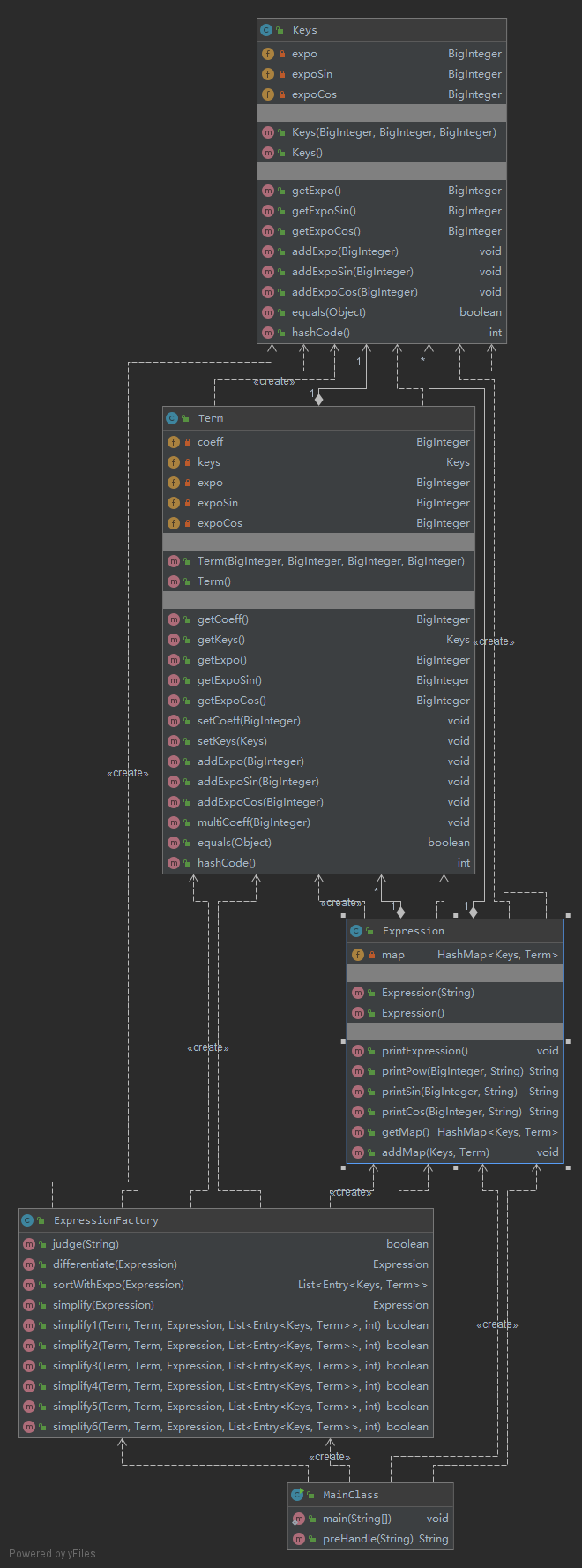
代码分析如下:
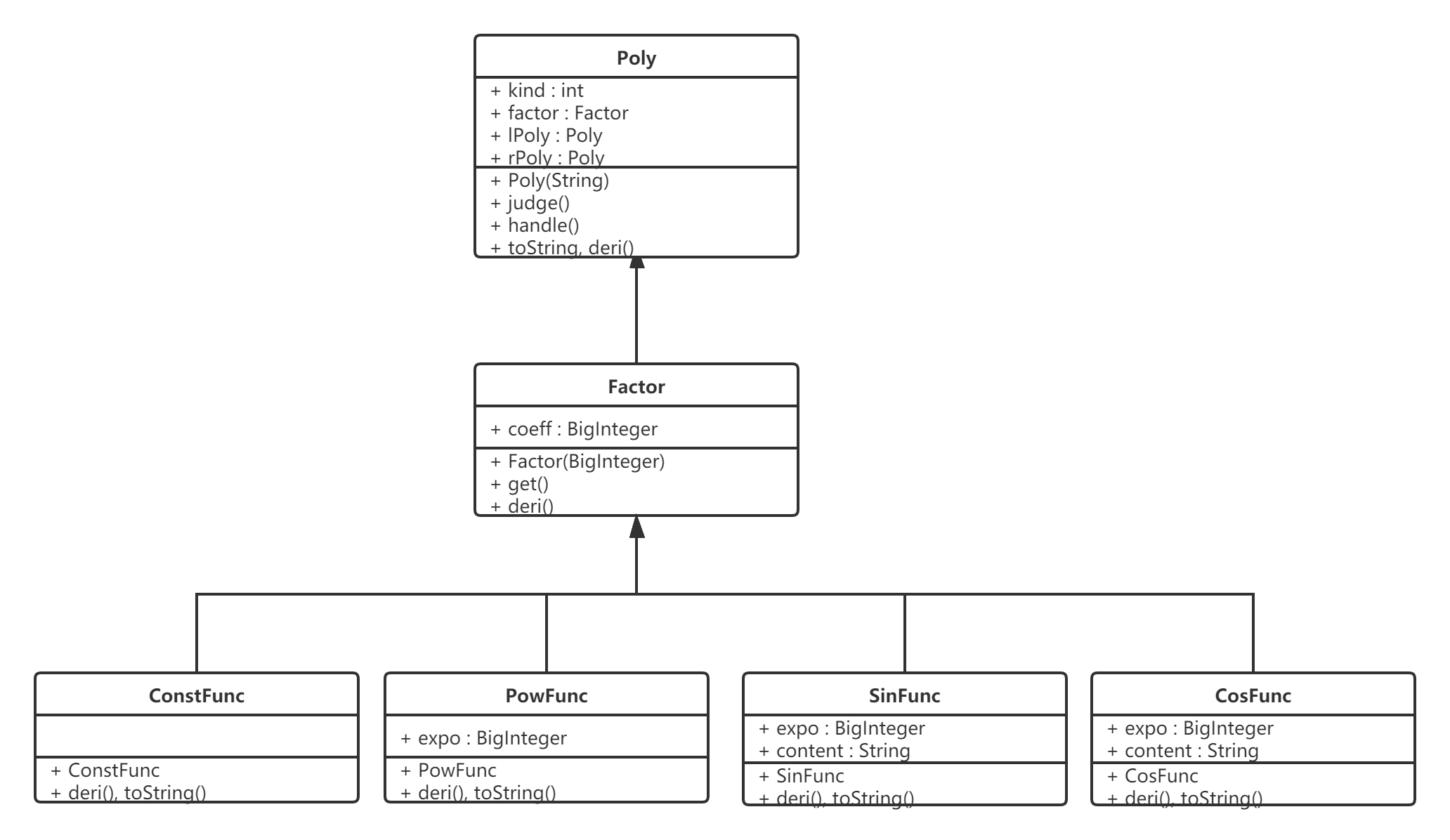
UML图
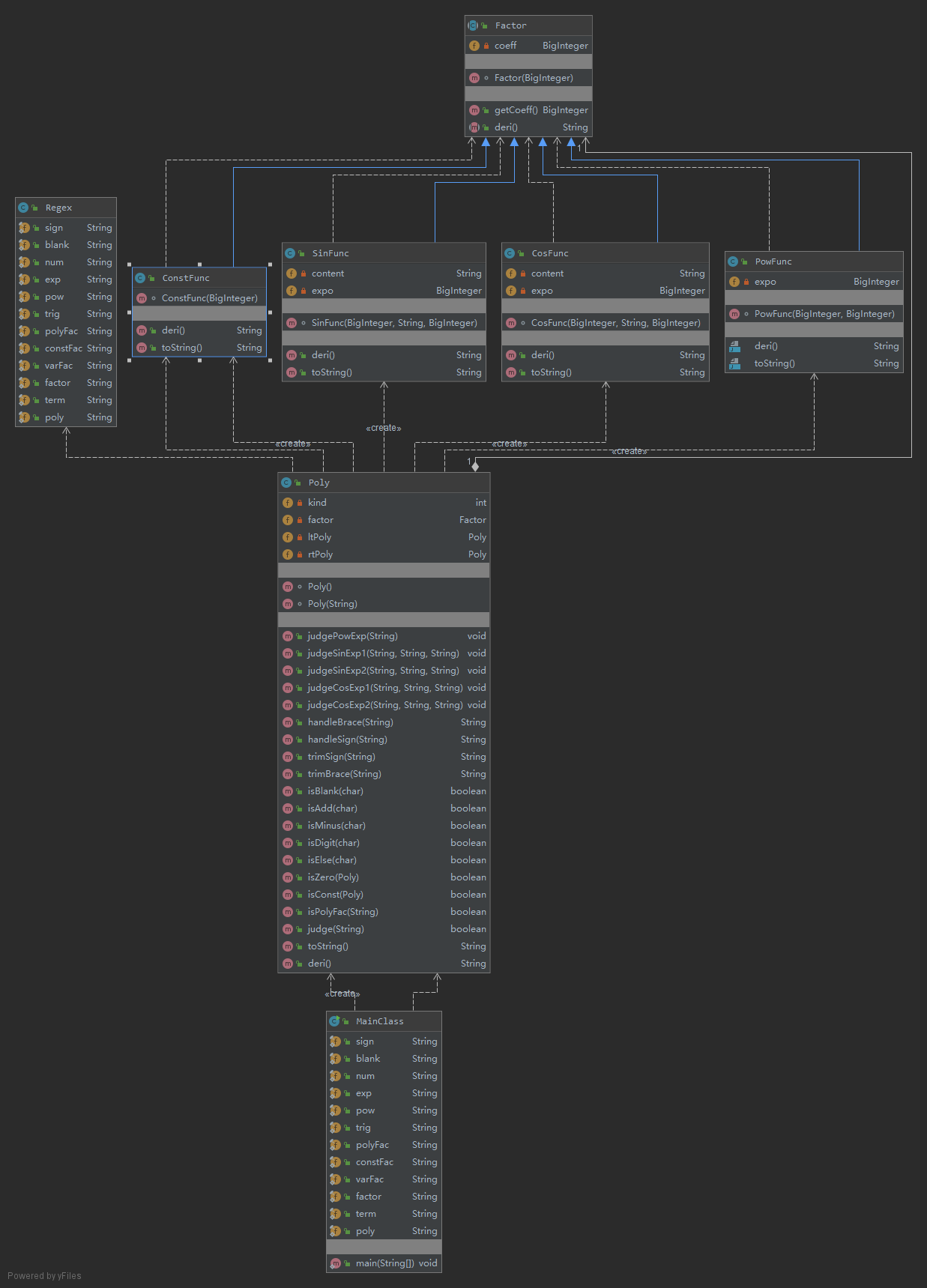
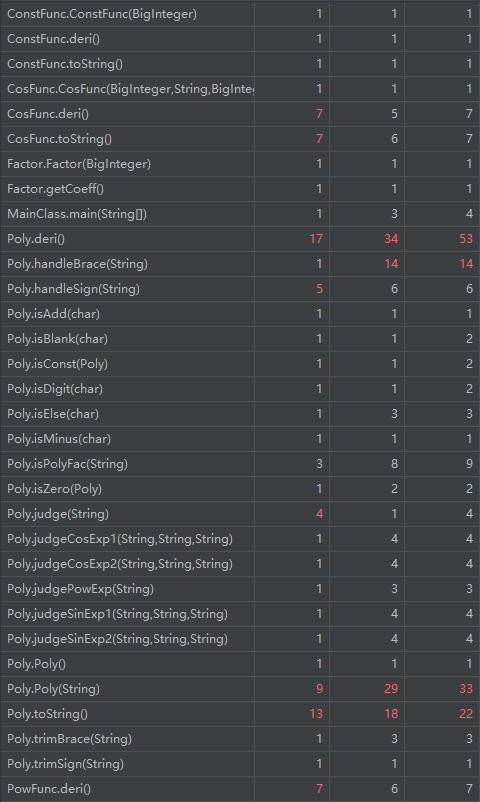
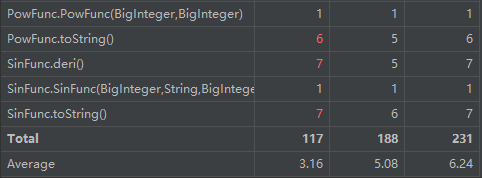
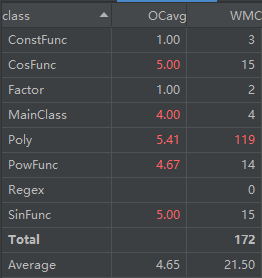
由于采用了递归调用的方式,Poly类的输出,求导以及其连带了某些函数的求导,输出都出现了复杂度较高的情况,但这种思路较前两周有了更大的提升,本身也更符合面向对象的思维方式。对于函数组合的方式,我并未将其分成单独的类,这有些符合面向过程的思维方式,可以得到进一步的完善,本身对于降低耦合度也会有很大的帮助。
- 评测
在第三次作业之中,本人也遇到了一个差点致命的错误,就是指数的存储形式,指导书所言不大于50,这就诱导了我用Long储存,然而遇到超Long的数会直接报错,这一点超出了我的测试范围,导致我在中测最后一个点卡了许久,几近绝望。后经高人指导,幡然醒悟。才苟进了强测。在强测之中遇到了项中符号的错误格式无法判断的情况,我为其单独书写了一个正则判断错误,这本身也体现出了我构造测试用例一个不全面的表现。
在互测之中,我将之前测试的用例以及一些自动生成的数据进行测试,发现了一些同学的bug,主要集中在多符号的处理,以及嵌套内部内容处理的问题上,这些都是我在写自己程序之中最头疼也是测试最久的地方。
四、程序bug分析
具体的bug分析在前三个部分都有提到,我在此进行一下总结:
- 属性存储形式不对导致溢出的bug
- 多符号处理产生的漏判错误格式的bug
- 优化过程中循环调用产生的bug
后两个bug直接极大影响了我的测试成绩,也是我在测试自己程序忽视的地方。
五、互测hack策略
互测hack是一个斗智斗勇的环节,也是OO课程设计的一大亮点。互测让我们既做了开发者又做了用户(对用户透明)。对于hack我自己在第一单元采用的策略有几个:
- 先采用简单的测试用例,采用debug的形式对程序运行逻辑进行分析,再构造一些极端测试用例,观察是否有程序检测的覆盖
- 采用自动生成的测试用例,进行大范围的盲狙,发现bug,再逐步缩小范围进行bug定位,最终定位bug错误原因。
- 用脚本进行普遍测试,发现错误
诸多策略结合使用,可以提升自己的hack效率,避免盲开枪浪费机会也浪费时间的现象。
六、对象创建模式
这三次作业本身都是应用工厂模式创建对象的一个良好的机会,但由于输入条件的简单,我的表达式工厂仅用来协助创造了求导,以及输出的方法。而本身表达式的创建我使用了表达式对象自身的构造方法,这种方法也直接导致了构造方法的复杂度,耦合度较高。将构造方法移植到工厂中进行构建我认为更符合创建模式,而且可以一定程度上解耦。
在第三次作业之中我引入了抽象类表示因子,引入了抽象方法求导与因子输出,再将多种因子继承,实现方法。构造表达式时利用多态进行对象的管理。这种实践较为成功。
七、心得体会
第一单元的三次作业难度逐步提升,本人在第三次作业中耗费精力甚多,可能有如下原因:
- 对于树的数据结构实现不熟练,大一下知识基础储备不扎实,需补齐
- 思维不具有化整为零的特点,思考许多种情况导致思维一团乱麻,无从下手
- 思维不连贯,导致构造好功能之后在括号处理方面遇到了好多bug,究其原因就是括号处理初期思想错误。
第一单元也在继承、多态、接口、对象创建模式等方面对我们进行了强化练习,两次实验三次作业效果都很好。也让我们体会到了这门课有多么充实,多么硬核。互测的圣杯之战是多么惨烈。要想活下去,就继续战斗吧!勇士们。
总结:多看讨论区,多构造样例,多向大佬请教:)