这两天看了很多web漏洞扫描器编写的文章,比如W12scan以及其前身W8scan,还有猪猪侠的自动化攻击背景下的过去、现在与未来,以及网上很多优秀的扫描器和博客,除了之前写了一部分的静湖ABC段扫描器,接下来有空的大部分时间都会用于编写这个扫描器,相当于是对自己的一个阶段性挑战吧,也算是为了完善自己的技术栈。
因为想把扫描器做成web应用,像W12scan,bugscan,AWVS那样的,部署好了之后登陆,添加需要扫描的url,自动化进行漏洞扫描,首先需要将扫描器的web界面完成,也就是前后端弄好,漏洞扫描作为后面添加进去的功能,在原基础上进行修改。
因为时间不是很宽裕,所以选择Flask框架进行web的开发,学习的视频是:
https://study.163.com/course/courseMain.htm?courseId=1004091002
找了很久的视频,要么就是太短了,对于很多地方没有讲透彻,要么就是几百集的教程丢过来,过于繁杂。
文档可以看官方文档,或者是这个:
http://www.pythondoc.com/flask-mega-tutorial/
当然遇到不会的问题还需要谷歌搜索一下,发挥自己的主观能动性。
接下来慢慢更新这一篇博客,先学Flask,哪里不会点技能树的哪里吧。当然也不能放弃代码审计,CTF和网课的学习
2020/4/2更新
框架快搭建好了,先做了登录界面
然后扫描器的基础功能也在readme里面写好了,侧重的功能模块是信息搜集和FUZZ模块
碎遮 Web漏洞扫描器
环境要求:
python版本要求:3.x,python运行需要的类库在requirements.txt中,执行
pip3 install -r requirements.txt
进行类库的下载
主要功能:
一,输入源采集:
1,基于流量清洗
2,基于日志提取
3,基于爬虫提取
二,输入源信息搜集(+)
1,被动信息搜集:(公开渠道可获得信息,与目标系统不产生直接交互)
1,whois 信息 获取关键注册人的信息 chinaz
2,在线子域名挖掘(这里不会ban掉自身IP,放进被动信息搜集中)
3,绕过CDN查找真实IP
4,DNS信息搜集
5,旁站查询
6,云悉指纹
7,备案信息
8,搜索引擎搜索
9,备案查询
2,主动信息搜集:
1,旁站C段服务简单扫描
2,子域名爆破
3,CMS指纹识别
4,敏感目录,文件扫描
5,端口及运行服务
6,服务器及中间件信息
7,WAF检测
8,敏感信息泄露 .svn,.git 等等
9,登录界面发现
三,SQL注入漏洞
四,XSS漏洞检测
五,命令执行类漏洞
六,文件包含类漏洞
七,登录弱密码爆破
八,FUZZ模块
可视化界面:
使用flask+javascript+html+css编写
启动index.py,在浏览器中访问127.0.0.1:5000访问
准备开始模块的编写,加油趴
整个项目现在完成了1/3的样子,因为自己缺乏架构的经验,所以暂时只能走一步看一步,最开始使用MySQL数据库准备换成redis非关系型数据库加快读写速度,扫描器在写的过程中丰富了自己对于各方面知识的掌握
贴上W12scan的代码架构镇楼
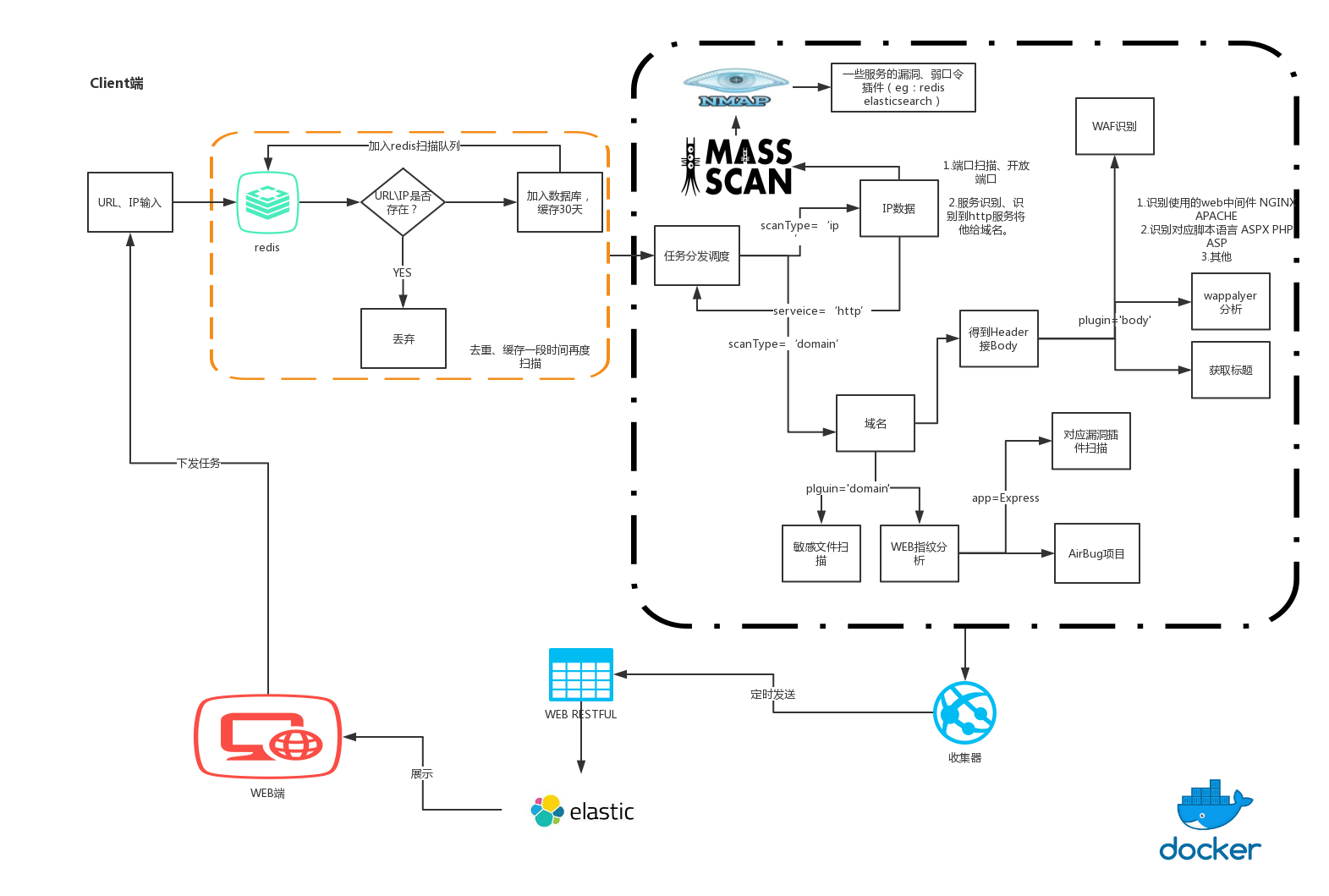
从架构图里面跟自己扫描器的想法进行了一些验证和补充。自己写的时候应该不会用到elastic,可以考虑使用redis和MySQL数据库两个相互进行配合存储数据。
另外在扫描范围上要进行合法范围的扩大化。