谷歌在2017年发表了一篇论文名字《Attention Is All You Need》,提出了一个基于attention的结构来处理序列模型相关的问题,比如机器翻译。传统的神经机器翻译大都是利用RNN或者CNN来作为encoder-decoder的模型基础,而谷歌最新的只基于Attention的Transformer模型摒弃了固有的定式,并没有用任何CNN或者RNN的结构。该模型可以高度并行地工作,所以在提升翻译性能的同时训练速度也特别快。
attention是干嘛的?
1、更新不同语境下词的表征;个人理解,NLP中指代消解,语义歧义问题较多,attention解决的是分配注意力(权重)问题,每个词对当前词的影响权重。传统的word2vec中,向量训练好后永久不变,不同词在不同的语境下有不同的表达,self--attention通过词权重更新词的重要性。
2、能并行计算,能抓住语序信息;包括CNN,LSTM,自然语言通过embedding的方式变为低维向量空间,attention做到了重点关系挖掘,但内在语序信息会丢失,transform中通过位置编码(position Encoding)来解决。这一机制后面会讲解。
本着快速了解attention的原则,抓住重点,拒绝长篇大论
attention是对time step input 的信息赋予不同的权重。加入attention的RNN结构model如下图(亦称为soft attention)
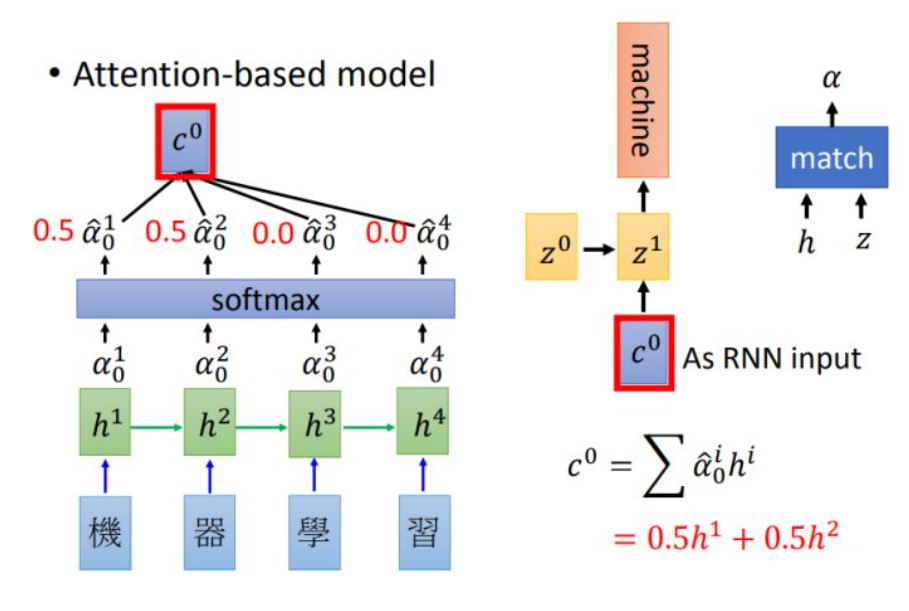
中 是
对应的权重,算出所有权重后会进行softmax和加权,得到
。
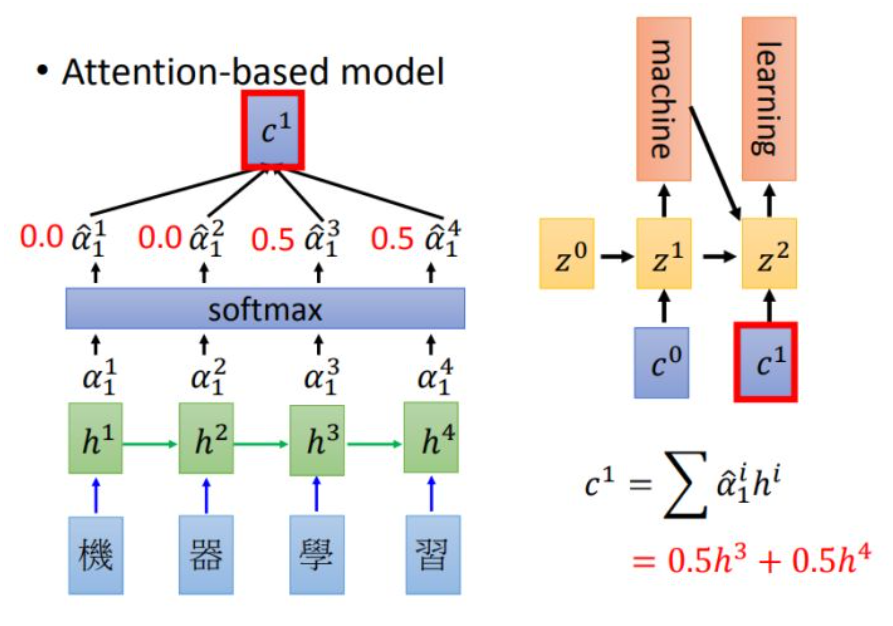
encoder 和decoder的结构是RNN,decoder使用的attention输出结构 作为RNN的输入。
attention的结构如下图:
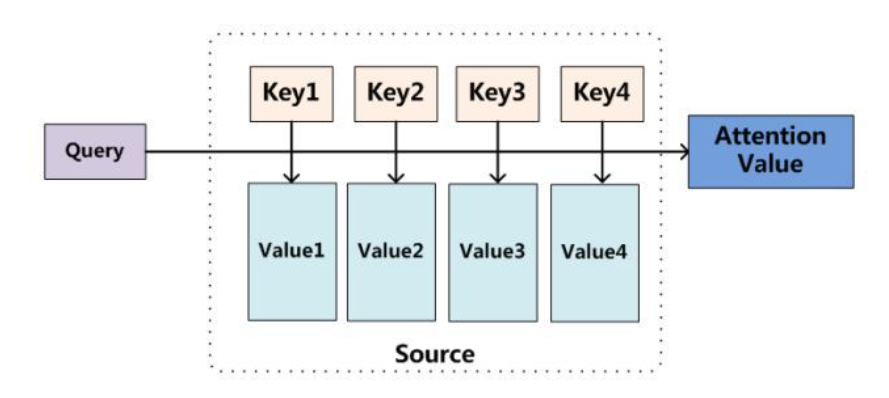
输入是query(Q), key(K), value(V),输出是attention value。如果与之前的模型对应起来的话,query就是 ,key就是
,value也是
。模型通过Q和K的匹配计算出权重,再结合V得到输出:
我们可以这样来看待Attention机制(上图):将Source中的构成元素想象成是由一系列的<Key,Value>数据对构成,此时给定Target中的某个元素Query(解码器隐藏层状态st-1),通过计算Query和各个Key(输入句子中每个单词)的相似性或者相关性,得到每个Key对应Value(输入句子中每个单词对应的语义编码,即各个编码器隐藏层状态h1-ht )的权重系数(也就是,编码器每个隐藏层向量的权重ai,j),然后对Value进行加权求和,即得到了最终的Attention数值。所以本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。
对于Attention机制的具体计算过程,如果对目前大多数方法进行抽象的话,可以将其归纳为两个过程:第一个过程是根据Query和Key计算权重系数,第二个过程根据权重系数对Value进行加权求和。而第一个过程又可以细分为两个阶段:第一个阶段根据Query和Key计算两者的相似性或者相关性;第二个阶段对第一阶段的原始分数值进行归一化处理。
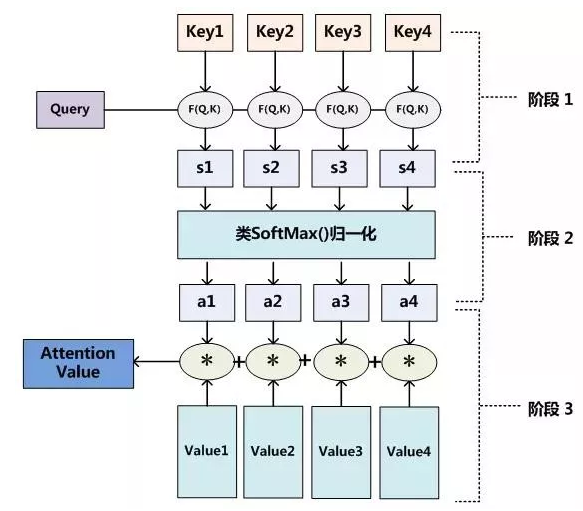
在第一阶段,根据query和key计算两者的相似性或者相关性,常用的方法:点积、向量cosine相似性或者引入额外的神经网络求值;

在第二阶段,由于阶段一方法不同数值的取值范围也不一致,第二阶段引入softmax进行归一化转化,
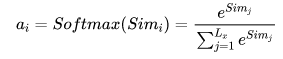
在第三阶段,计算结果α为value对应的权重系数,进行加权即可得到attention数值。

transform的结构和attention机制一样,transformer模型也采用了encoder-decoder架构,论文中encoder层由6个encoder堆叠在一样,每一个encoder和encoder结构如下:
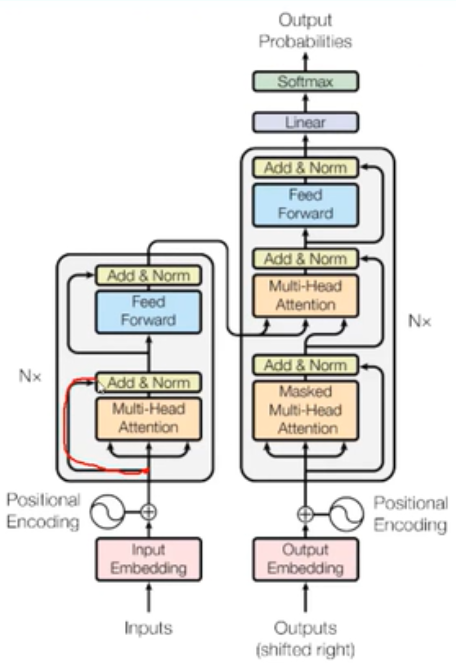
结构主要特征:
1、self_attention;2、mutil_head;3、多层堆叠,位置编码,残差连接;4、并行加速计算;5、decoder中attention计算方式不同,并加入mask机制
positional encoding,维度和embedding维度一样, 论文中计算方法如下,其中pos指当前词在句子中的位置,I是指向量中每个值的index,可以看出,偶数位置使用正弦编码,奇数位置使用余弦编码。
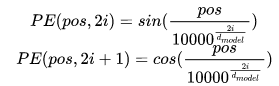
bert基于transform构建,使用了transform的encoder部分,Bidirectional Encoder Representations from Transform
训练方法:1、15%的词会被随机mask,预测mask的词来学习;2、预测两个句子是否应该在一起,seq(连个句子的连接符),cls(两个要分类的向量)
Seq2Seq与transformer对比
- seq2seq缺点: 这里用代替这个词略显不妥当,seq2seq虽已老,但始终还是有其用武之地,seq2seq最大的问题在于将Encoder端的所有信息压缩到一个固定长度的向量中 ,并将其作为Decoder端首个隐藏状态的输入,来预测Decoder端第一个单词(token)的隐藏状态。在输入序列比较长的时候,这样做显然会损失Encoder端的很多信息,而且这样一股脑的把该固定向量送入Decoder端,Decoder端不能够关注到其想要关注的信息。上述两点都是seq2seq模型的缺点,后续论文对这两点有所改进,如著名的《Neural Machine Translation by Jointly Learning to Align and Translate》,虽然确确实实对seq2seq模型有了实质性的改进,但是由于主体模型仍然为RNN(LSTM)系列的模型,因此模型的并行能力还是受限。
- Transformer优点: transformer不但对seq2seq模型这两点缺点有了实质性的改进(多头交互式attention模块),而且还引入了self-attention模块,让源序列和目标序列首先“自关联”起来,这样的话,源序列和目标序列自身的embedding表示所蕴含的信息更加丰富,而且后续的FFN层也增强了模型的表达能力(ACL 2018会议上有论文对Self-Attention和FFN等模块都有实验分析,见论文:《How Much Attention Do You Need?A Granular Analysis of Neural Machine Translation Architectures》),并且Transformer并行计算的能力是远远超过seq2seq系列的模型,因此我认为这是transformer优于seq2seq模型的地方。
模型分类
soft attention /hard attention
soft attention 可被嵌入到模型中进行训练并传播梯度
hard attention 不计算输出,根据概率对encoder 进行输出采样,反向传播时运用蒙特卡洛进行梯度估计
global / local attention
global attention 对所有encoder输出进行计算
local attention 介于soft 和hard之间,会预测一个位置并选取一个窗口进行计算。
self attention
传统attention是计算Q和K之间的依赖关系,self attention 分别计算Q和K自身的依赖关系
优势
- 输出序列到输入序列‘顺序’不同情况下表现较好
- 相比RNN可以编码更长的序列信息
缺点
- 对序列顺序不敏感
- 通常和RNN结合使用,不能并行
大佬文章:
Seq2Seq以及注意力机制
seq2seq 任务只是输入和输出都是序列的任务,翻译系统类似,从一种语言到另一种语言。
编码器-解码器(Encoder-Decoder)模型最初是由Cho等提出应用到机器翻译中,由于机器翻译中是文本到文本的转换,Sutskever等也称编码器-解码器模型为序列到序列学习(Seq2Seq)
相关论文如下:
【1】Cho K, Van Merriënboer B, Gulcehre C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation[J]. arXiv preprint arXiv:1406.1078, 2014.
【2】Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks[C]//Advances in neural information processing systems. 2014: 3104-3112.
Encoder-Decoder模型
Seq2Seq任务最常见的是Encoder - Decoder模型,将序列编码成一个上下文矩阵,再使用Decoder来解码,context vector作为编码器到解码器的输入,也就是编码器要将整个序列的信息压缩成一个固定长度的向量。
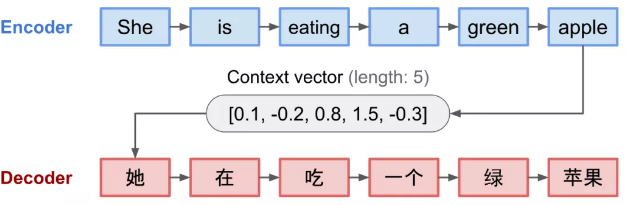
弊端有三:
1、对编码器而言,语义向量context vector 无法表示真个序列的信息;
2、先输入到网络的序列携带的信息可能会被覆盖掉,输入序列越长,这种问题更严重;
3、解码器在解码时,对于输入的每个单词的权重是不一致的。
一般在NMT(neural machine translation,神经机器翻译)任务上,还添加了attention机制。