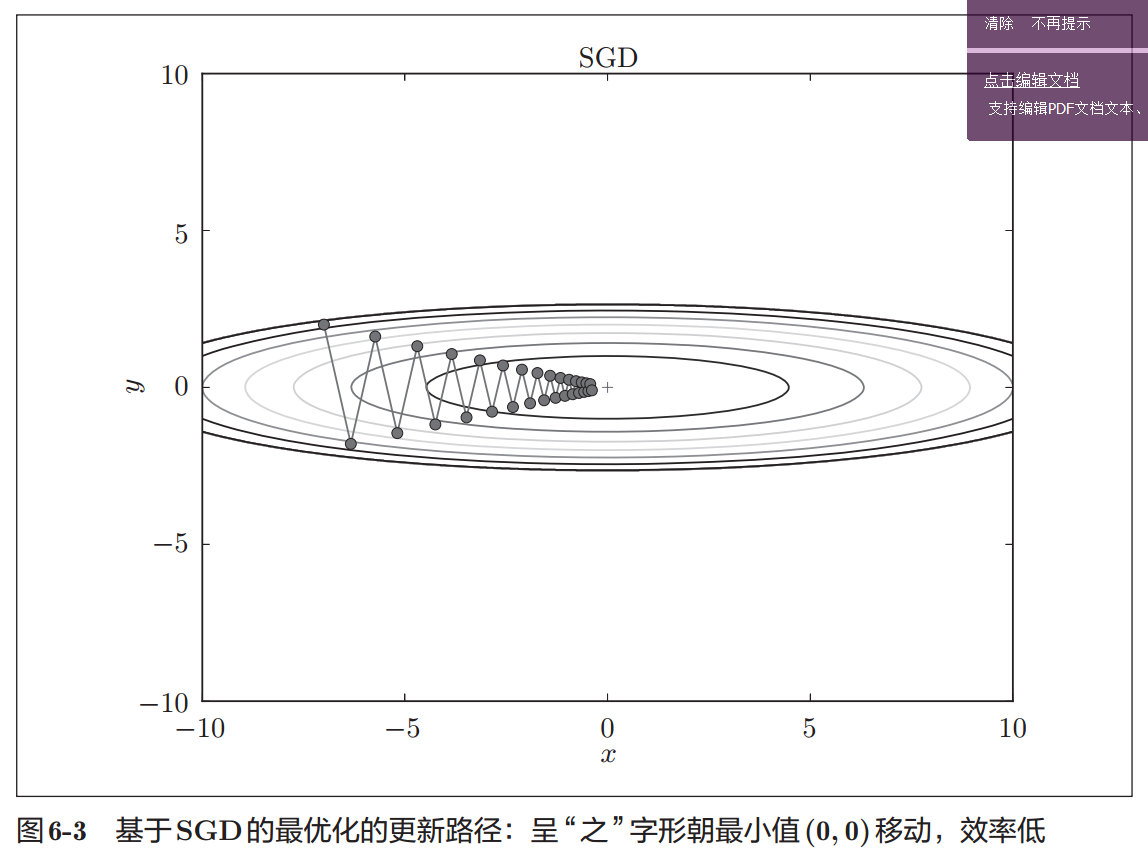
SGD
权重更新公式
[W leftarrow W - eta frac{{partial L}}{W}]
优缺点分析
由于SGD不同的参数都用了相同的学习率,在许多情况SGD的梯度都没有指向最小值方向,使SGD的学习变得低效,SGD想要很好的收敛需要在调节学习率上下很大的功夫。。

python代码
class SGD: def __init__(self, lr=0.01): self.lr = lr def update(self, params, grads): for key in params.keys(): params[key] -= self.lr * grads[key]
Momentum
权重更新公式

优缺点分析
momentum即动量,它模拟的是物体运动时的惯性,即更新的时候在一定程度上保留之前更新的方向,同时利用当前batch的梯度微调最终的更新方向。这样一来,可以在一定程度上增加稳定性,从而学习地更快,并且还有一定摆脱局部最优的能力。更新路径就像小球在碗中滚动一样。和SGD相比,我们发现“之”字形的“程度”减轻了。这是因为虽然x轴方向上受到的力非常小,但是一直在同一方向上受力,所以朝同一个方向会有一定的加速。反过来,虽然y轴方向上受到的力很大,但是因为交互地受到正方向和反方向的力,它们会互相抵消,所以y轴方向上的速度不稳定。因此,和SGD时的情形相比,可以更快地朝x轴方向靠近,减弱“之”字形的变动程度。

python代码实现
class Momentum: def __init__(self, lr=0.01, momentum=0.9): self.lr = lr self.momentum = momentum self.v = None def update(self, params, grads): if self.v is None: self.v = {} for key, val in params.items(): self.v[key] = np.zeros_like(val) for key in params.keys(): self.v[key] = self.momentum * self.v[key] - self.lr * grads[key] params[key] += self.v[key]
AdaGrad
权重更新公式

优缺点分析
在神经网络的学习中,学习率(数学式中记为η)的值很重要。学习率过小,会导致学习花费过多时间;反过来,学习率过大,则会导致学习发散而不能正确进行。在关于学习率的有效技巧中,有一种被称为学习率衰减(learning ratedecay)的方法,即随着学习的进行,使学习率逐渐减小。实际上,一开始“多”学,然后逐渐“少”学的方法,在神经网络的学习中经常被使用。逐渐减小学习率的想法,相当于将“全体”参数的学习率值一起降低。而AdaGrad进一步发展了这个想法,针对“一个一个”的参数,赋予其“定制”的值。AdaGrad会为参数的每个元素适当地调整学习率 。

python代码
class AdaGrad: def __init__(self, lr=0.01): self.lr = lr self.h = None def update(self, params, grads): if self.h is None: self.h = {} for key, val in params.items(): self.h[key] = np.zeros_like(val) for key in params.keys(): self.h[key] += grads[key] * grads[key] params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
Adam
权重更新公式

python代码实现
class Adam: """Adam (http://arxiv.org/abs/1412.6980v8)""" def __init__(self, lr=0.001, beta1=0.9, beta2=0.999): self.lr = lr self.beta1 = beta1 self.beta2 = beta2 self.iter = 0 self.m = None self.v = None def update(self, params, grads): if self.m is None: self.m, self.v = {}, {} for key, val in params.items(): self.m[key] = np.zeros_like(val) self.v[key] = np.zeros_like(val) self.iter += 1 lr_t = self.lr * np.sqrt(1.0 - self.beta2**self.iter) / (1.0 - self.beta1**self.iter) for key in params.keys(): #self.m[key] = self.beta1*self.m[key] + (1-self.beta1)*grads[key] #self.v[key] = self.beta2*self.v[key] + (1-self.beta2)*(grads[key]**2) self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key]) self.v[key] += (1 - self.beta2) * (grads[key]**2 - self.v[key]) params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7) #unbias_m += (1 - self.beta1) * (grads[key] - self.m[key]) # correct bias #unbisa_b += (1 - self.beta2) * (grads[key]*grads[key] - self.v[key]) # correct bias #params[key] += self.lr * unbias_m / (np.sqrt(unbisa_b) + 1e-7)