在本文回答这几个焦点问题,主要介绍一下32位和64位系统区别和联系,64位的优点和判断方法,及在选购64位系统硬软件时的几点建议仅供交流参考
一、32位和64位的区别
1、32位和64位一般是指CPU的通用寄存器位宽,所以64位的CPU位宽增加一倍
2、可寻址范围大大扩展,32位系统支持最大内存位4G,64位系统理论支持最大内存2^64=18446,744,073,709,551,616,约1600万TB,相当于16EB。(实际还受制于操作系统和主板约束),实际的CPU尤其是这两年的CPU都是采取兼容设计的,内部总线不到64位,后期的CPU逐渐都会采用标准的64位,具体见下文。
3、32位系统和64位系统需要安装支持相应系统模式下的操作系统和驱动软件,也就是32位只能安装32位,64位安装64位的但可兼容32位运算。
4、目前约定俗成的x86就是代表32位操作系统,x64代表64位操作系统,天缘博客中出现很多操作系统标示比如(x86)——代表32位,(x64)——代表64位。
5、目前64位CPU标准有:AMD 64、EMT-64、IA-64。更多关于INTEL 64:http://zh.wikipedia.org/zh-cn/Intel_64
二、64位系统的优点
64位系统的理论优点:
*64位系统理论支持安装最大16EB的内存,具体跟CPU的地址总线宽度有关,地址总线宽度及支持内存大小见下面的表格
*所有64位寄存器仍然使用相同的划分方案,仍支持执行8位运算
*RIP(新的64位指令指针)替代32位的EIP指针(再早期的IP指针为16位),并向下兼容。
*SIMD指令使用新的寄存器,CPU在64位模式下有16、64位MMX寄存器
* XMM寄存器为16位,用来做SSE浮点运算指针
*只有FPU寄存器是80位宽度,其它剩余的寄存器和指令都是64位宽度
更多请参考:http://www.tech-faq.com/cpu.shtml
CPU 地址总线宽度:
| CPU | 地址总线 |
|---|---|
| 8086 | 20 bit |
| 8088 | 20 bit |
| 80286 | 24 bit |
| 80386SX | 24 bit |
| 80386DX | 32 bit |
| 80486SX | 32 bit |
| 80486DX | 32 bit |
| Pentium I | 32 bit |
| K6 | 32 bit |
| Duron | 32 bit |
| Athlon | 32 bit |
| Athlon XP | 32 bit |
| Celeron | 36 bit |
| Pentium Pro | 36 bit |
| Pentium II | 36 bit |
| Pentium III | 36 bit |
| Pentium 4 | 36 bit |
| Athlon | 40 bit |
| Athlon-64 | 40 bit |
| Athlon-64 FX | 40 bit |
| Opteron | 40 bit |
| Itanium | 44 bit |
| Itanium 2 | 44 bit |
更多CPU地址总线宽度:http://www.cpu-world.com/CPUs/CPU.html
地址总线可寻址范围(支持最大内存):
| 地址总线宽度 | 最大内存 |
|---|---|
| 20 bits | 1MB |
| 24 bits | 16MB |
| 32 bits | 4GB |
| 36 bits | 64GB |
| 40 bits | 1TB |
| 44 bits | 16TB |
64位CPU的实用优点:
64位的系统在视频编辑、文件搜索、科学计算、人工智能、平面设计、视频处理、3D动画和游戏、数据库以及各种网络服务器等方面具备更强大的优势,尤其是在工程制图、3D、音视频制作等领域的具有极佳的应用效果。64位系统效能发挥需要三大模块支撑:硬件、操作系统、上层软件。普通的32位软件是无法在64位操作系统上运行的。
三、如何判断您的计算机是否支持64位操作系统
硬件上的区分:
1、CPU: AMD在2003年春季发布第一款针对服务器的x86架构64位服务器处理器皓龙,秋天发布了同样架构的速龙64系列处理器,揭开了64位运算新篇章(当然这是指桌面处理器,专业的64位甚至更高位的处理器早就有了,比如SUN公司的UltraSparc Ⅲ、IBM公司的POWER5、HP公司的Alpha等)。2005年4月26日,微软正式发布了64位操作系统Windows Server 2003 x64 Edition和Windows XP Professional x64 Edition,距离第一片64位x86处理器上市有两年多时间。
也就是说目前发布的通用处理器,包括INTEL、AMD几乎都是64位的,天缘认为只要主板不是“偷工减料”的采用兼容性设计,都是可以支持64位操作系统安装,当然实际支持内存的大小还决定CPU的地址总线宽度和您的主板情况。实际运行还跟前端总线有关,比如早期的FSB和Core i5、Core i7使用的QPI(对抗AMD的HT总线)。更多QPI相关知识:http://baike.baidu.com/view/1377507.htm
2、主板:目前市面的主流主板都是支持64位CPU的。
3、内存:基本无限制,当然为了搭配新最新的CPU和主板,速度上最好不要拖后腿就可以了。
软件上区分:
1、操作系统:目前Windows的大部分系列都有对应的64位版本发布。比如Windows 7除了家庭版初级班没有64位,其它都有,windows Server 2008 SP2只发布64位版本。
2、驱动程序和软件:这一点最为头疼,从目前来看,驱动程序除了部分老设备(比如打印机、扫描仪较老可能会没有64位驱动),新的设备都会发布64位驱动程序,但是64位的软件就非常缺乏,而且很多企业由于应用市场关系,目前64位应用还没到非用不可的地步,所以很多企业都还未开发64位版本软件,即使开发出来,售价也相当高。这种现状可能会持续稍后的3-5年不会一下改观。
平台测试:
比如使用CPU-Z等软件查看CPU是否支持EMT-64指令集即可。EMT-64本来是专指INTEL CPU支持64位指令集,现在也指AMD 64了,如果显示是AMD64也可以。此外还有IA-64,是INTEL独立开发的64位处理器,不兼容32位计算机,是纯的64位技术。谨慎选用
更多关于EMT64知识:http://www.tech-faq.com/em64t.shtml
五、关于64位系统的其它问题综合
1、我是装32位操作系统运行快,还是64位操作系统运行快?
从总体运行效率看,肯定是32位系统快,对于系统硬件配置不是太高端的用户,天缘推荐仍然安装32位操作系统。
更多关于运行速度的分析,请参考:
2、我是否有必要安装64位操作系统?
这里,天缘还是保守一点,对于做科学运算、工程制图、3D制作、音频视频编辑的用户,天缘推荐尝试安装64位操作系统,那样更能彰显64位的优势。
3、商家总是推荐支持64位是怎么回事?
大家不要相信商家所谓的64位支持,纯粹是寻找卖点而已,现在不支持64位系统的已经很少,包括主板、CPU等等。
指令重排的原因以及可能造成的问题
为何要指令重排?
现在的CPU一般采用流水线来执行指令。一个指令的执行被分成:取指、译码、访存、执行、写回、等若干个阶段。然后,多条指令可以同时存在于流水线中,同时被执行。
指令流水线并不是串行的,并不会因为一个耗时很长的指令在“执行”阶段呆很长时间,而导致后续的指令都卡在“执行”之前的阶段上。
相反,流水线是并行的,多个指令可以同时处于同一个阶段,只要CPU内部相应的处理部件未被占满即可。比如说CPU有一个加法器和一个除法器,那么一条加法指令和一条除法指令就可能同时处于“执行”阶段, 而两条加法指令在“执行”阶段就只能串行工作。
相比于串行+阻塞的方式,流水线像这样并行的工作,效率是非常高的。
然而,这样一来,乱序可能就产生了。比如一条加法指令原本出现在一条除法指令的后面,但是由于除法的执行时间很长,在它执行完之前,加法可能先执行完了。再比如两条访存指令,可能由于第二条指令命中了cache而导致它先于第一条指令完成。
一般情况下,指令乱序并不是CPU在执行指令之前刻意去调整顺序。CPU总是顺序的去内存里面取指令,然后将其顺序的放入指令流水线。但是指令执行时的各种条件,指令与指令之间的相互影响,可能导致顺序放入流水线的指令,最终乱序执行完成。这就是所谓的“顺序流入,乱序流出”。
指令流水线除了在资源不足的情况下会卡住之外(如前所述的一个加法器应付两条加法指令的情况),指令之间的相关性也是导致流水线阻塞的重要原因。
CPU的乱序执行并不是任意的乱序,而是以保证程序上下文因果关系为前提的。有了这个前提,CPU执行的正确性才有保证。比如:
a++; b=f(a); c--;
由于b=f(a)这条指令依赖于前一条指令a++的执行结果,所以b=f(a)将在“执行”阶段之前被阻塞,直到a++的执行结果被生成出来;而c--跟前面没有依赖,它可能在b=f(a)之前就能执行完。(注意,这里的f(a)并不代表一个以a为参数的函数调用,而是代表以a为操作数的指令。C语言的函数调用是需要若干条指令才能实现的,情况要更复杂些。)
像这样有依赖关系的指令如果挨得很近,后一条指令必定会因为等待前一条执行的结果,而在流水线中阻塞很久,占用流水线的资源。而编译器的乱序,作为编译优化的一种手段,则试图通过指令重排将这样的两条指令拉开距离, 以至于后一条指令进入CPU的时候,前一条指令结果已经得到了,那么也就不再需要阻塞等待了。比如将指令重排为:
a++; c--; b=f(a);
相比于CPU的乱序,编译器的乱序才是真正对指令顺序做了调整。但是编译器的乱序也必须保证程序上下文的因果关系不发生改变。
指令重排可能产生的问题:
1.无法识别带有隐式因果关系的指令
有些程序逻辑,单纯从上下文是看不出它们的因果关系的。比如:
*addr=5; val=*data;
从表面上看,addr和data是没有什么联系的,完全可以放心的去乱序执行。但是如果这是在某某设备驱动程序中,这两个变量却可能对应到设备的地址端口和数据端口。并且,这个设备规定了,当你需要读写设备上的某个寄存器时,先将寄存器编号设置到地址端口,然后就可以通过对数据端口的读写而操作到对应的寄存器。那么这么一来,对前面那两条指令的乱序执行就可能造成错误。
2.多线程带来的问题
考虑下面的代码:
线程A:
c=10;
b=c;
flag=true;
线程B:
while(flag){
System.out.println(b);
}
如果编译器将线程A的第三条指令重排到第一行,那线程B拿到的b的数据就有可能出错了。
JVM之指令重排分析
引言:在Java中看似顺序的代码在JVM中,可能会出现编译器或者CPU对这些操作指令进行了重新排序;在特定情况下,指令重排将会给我们的程序带来不确定的结果.....
1. 什么是指令重排?
在计算机执行指令的顺序在经过程序编译器编译之后形成的指令序列,一般而言,这个指令序列是会输出确定的结果;以确保每一次的执行都有确定的结果。但是,一般情况下,CPU和编译器为了提升程序执行的效率,会按照一定的规则允许进行指令优化,在某些情况下,这种优化会带来一些执行的逻辑问题,主要的原因是代码逻辑之间是存在一定的先后顺序,在并发执行情况下,会发生二义性,即按照不同的执行逻辑,会得到不同的结果信息。
2. 数据依赖性
主要指不同的程序指令之间的顺序是不允许进行交互的,即可称这些程序指令之间存在数据依赖性。
主要的例子如下:
-
名称 代码示例 说明
-
写后读 a = 1;b = a; 写一个变量之后,再读这个位置。
-
写后写 a = 1;a = 2; 写一个变量之后,再写这个变量。
-
读后写 a = b;b = 1; 读一个变量之后,再写这个变量。
进过分析,发现这里每组指令中都有写操作,这个写操作的位置是不允许变化的,否则将带来不一样的执行结果。
编译器将不会对存在数据依赖性的程序指令进行重排,这里的依赖性仅仅指单线程情况下的数据依赖性;多线程并发情况下,此规则将失效。
3. as-if-serial语义
不管怎么重排序(编译器和处理器为了提高并行度),(单线程)程序的执行结果不能被改变。编译器,runtime 和处理器都必须遵守as-if-serial语义。
分析: 关键词是单线程情况下,必须遵守;其余的不遵守。
代码示例:
-
double pi = 3.14; //A
-
double r = 1.0; //B
-
double area = pi * r * r; //C
分析代码: A->C B->C; A,B之间不存在依赖关系; 故在单线程情况下, A与B的指令顺序是可以重排的,C不允许重排,必须在A和B之后。
结论性的总结:
as-if-serial语义把单线程程序保护了起来,遵守as-if-serial语义的编译器,runtime 和处理器共同为编写单线程程序的程序员创建了一个幻觉:单线程程序是按程序的顺序来执行的。as-if-serial语义使单线程程序员无需担心重排序会干扰他们,也无需担心内存可见性问题。
核心点还是单线程,多线程情况下不遵守此原则。
4. 在多线程下的指令重排
首先我们基于一段代码的示例来分析,在多线程情况下,重排是否有不同结果信息:
-
class ReorderExample {
-
int a = 0;
-
boolean flag = false;
-
-
public void writer() {
-
a = 1; //1
-
flag = true; //2
-
}
-
-
Public void reader() {
-
if (flag) { //3
-
int i = a * a; //4
-
……
-
}
-
}
-
}
上述的代码,在单线程情况下,执行结果是确定的, flag=true将被reader的方法体中看到,并正确的设置结果。 但是在多线程情况下,是否还是只有一个确定的结果呢?
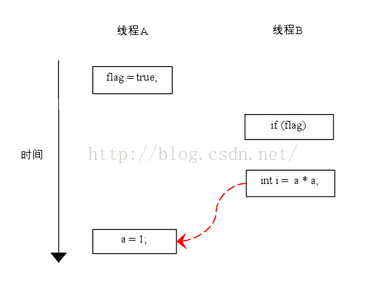
假设有A和B两个线程同时来执行这个代码片段, 两个可能的执行流程如下:
可能的流程1, 由于1和2语句之间没有数据依赖关系,故两者可以重排,在两个线程之间的可能顺序如下:
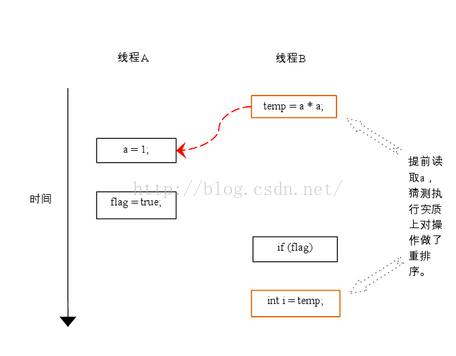
可能的流程2:, 在两个线程之间的语句执行顺序如下:
根据happens- before的程序顺序规则,上面计算圆的面积的示例代码存在三个happens- before关系:
- A happens- before B;
- B happens- before C;
- A happens- before C;
这里的第3个happens- before关系,是根据happens- before的传递性推导出来的
在程序中,操作3和操作4存在控制依赖关系。当代码中存在控制依赖性时,会影响指令序列执行的并行度。为此,编译器和处理器会采用猜测(Speculation)执行来克服控制相关性对并行度的影响。以处理器的猜测执行为例,执行线程B的处理器可以提前读取并计算a*a,然后把计算结果临时保存到一个名为重排序缓冲(reorder buffer ROB)的硬件缓存中。当接下来操作3的条件判断为真时,就把该计算结果写入变量i中。从图中我们可以看出,猜测执行实质上对操作3和4做了重排序。重排序在这里破坏了多线程程序的语义。
核心点是:两个线程之间在执行同一段代码之间的critical area,在不同的线程之间共享变量;由于执行顺序、CPU编译器对于程序指令的优化等造成了不确定的执行结果。
5. 指令重排的原因分析
主要还是编译器以及CPU为了优化代码或者执行的效率而执行的优化操作;应用条件是单线程场景下,对于并发多线程场景下,指令重排会产生不确定的执行效果。
6. 如何防止指令重排
volatile关键字可以保证变量的可见性,因为对volatile的操作都在Main Memory中,而Main Memory是被所有线程所共享的,这里的代价就是牺牲了性能,无法利用寄存器或Cache,因为它们都不是全局的,无法保证可见性,可能产生脏读。
volatile还有一个作用就是局部阻止重排序的发生,对volatile变量的操作指令都不会被重排序,因为如果重排序,又可能产生可见性问题。
在保证可见性方面,锁(包括显式锁、对象锁)以及对原子变量的读写都可以确保变量的可见性。但是实现方式略有不同,例如同步锁保证得到锁时从内存里重新读入数据刷新缓存,释放锁时将数据写回内存以保数据可见,而volatile变量干脆都是读写内存。
7. 可见性
这里提到的可见性是指前一条程序指令的执行结果,可以被后一条指令读到或者看到,称之为可见性。反之为不可见性。这里主要描述的是在多线程环境下,指令语句之间对于结果信息的读取即时性。
8. 参考文献
- http://www.infoq.com/cn/articles/java-memory-model-2
- http://www.cnblogs.com/chenyangyao/p/5269622.html
volatile指令重排案例分析
volatile指令重排案例分析
大厂面试题:
1、请你谈谈对volatile的理解?
2、CAS你知道吗?
3、原子类AtomicInteger的ABA问题谈谈?原子更新引用知道吗?
4、我们都知道ArrayList是线程不安全的,请编码写一个不安全的案例并给出解决方案?
5、公平锁/非公平锁/可重入锁/递归锁/自旋锁谈谈你的理解?请手写一个自旋锁。
6、CountDownLatch、CyclicBarrier、Semaphore使用过吗?
7、阻塞队列知道吗?
8、线程池用过吗?ThreadPoolExecutor谈谈你的理解?
9、线程池用过吗?生产上你是如何设置合理参数?
10、死锁编码及定位分析?
1、volatile概念
volatile是java虚拟机提供的轻量级同步机制
volatile三个特性:
- 保证可见性
- 不保证原子性
- 禁止指令重排
2、volatile禁止指令重排
(1)指令重排有序性:
计算机在执行程序时,为了提高性能,编译器和处理器常常会做指令重排,一般分为以下三种:
![]()
单线程环境里面确保程序最终执行结果和代码顺序执行结果一致。
处理器在进行指令重排序时必须考虑指令之间的数据依赖性
多线程环境中线程交替执行,由于编译器指令重排的存在,两个线程使用的变量能否保证一致性是无法确认的,结果无法预测。
指令重排案例分析one:
public void mySort() {
int x = 11; // 语句1
int y = 12; // 语句2
x = x + 5; // 语句3
y = x * x; // 语句4
}
// 指令重排之后,代码执行顺序有可能是以下几种可能?
// 语句1 -> 语句2 -> 语句3 -> 语句4
// 语句1 -> 语句3 -> 语句2 -> 语句4
// 语句2 -> 语句1 -> 语句3 -> 语句4
// 问题:请问语句4可以重排后变为第1条吗?
// 不能,因为处理器在指令重排时必须考虑指令之间数据依赖性。
指令重排案例分析two:

指令重排案例分析three:
public class BanCommandReSortSeq {
int a = 0;
boolean flag = false;
public void methodOne() {
a = 1; // 语句1
flag = true; // 语句2
// methodOne发生指令重排,程序执行顺序可能如下:
// flag = true; // 语句2
// a = 1; // 语句1
}
public void methodTwo() {
if (flag) {
a = a + 5; // 语句3
}
System.out.println("methodTwo ret a = " + a);
}
// 多线程环境中线程交替执行,由于编译器指令重排的存在,两个线程使用的变量能否保证一致性是无法确认的,结果无法预测。
// 多线程交替调用会出现如下场景:
// 线程1调用methodOne,如果此时编译器进行指令重排
// methodOne代码执行顺序变为:语句2(flag=true) -> 语句1(a=5)
// 线程2调用methodTwo,由于flag=true,如果此时语句1还没有执行(语句2 -> 语句3 -> 语句1 ),那么执行语句3的时候a的初始值=0
// 所以最终a的返回结果可能为 a = 0 + 5 = 5,而不是我们认为的a = 1 + 5 = 6;
}
(2)禁止指令重排底层原理:
volatile实现禁止指令重排优化,从而避免多线程环境下程序出现乱序执行的现象。
先了解下概念,内存屏障(Memory Barrier)又称内存栅栏,是一个CPU指令,它的作用有两个:
- 保证特定操作执行的顺序性;
- 保证某些变量的内存可见性(利用该特性实现volatile内存可见性)
volatile实现禁止指令重排优化底层原理:
由于编译器和处理器都能执行指令重排优化。如果在指令间插入一条Memory Barrier则会告诉编译器和CPU,不管什么指令都不能和这条Memory Barrier指令重排,也就是说通过插入内存屏障,就能禁止在内存屏障前后的指令执行重排优化。内存屏障另外一个作用就是强制刷出各种CPU的缓存数据,因此任何CPU上的线程都能读取到这些数据的最新版本。
左边:写操作场景:先LoadStore指令,后LoadLoad指令。
右边:读操作场景:先LoadLoad指令,后LoadStore指令。

3、volatile使用场景
单例模式(DCL-Double Check Lock双端检锁机制)
如果此时你也把volatile禁止指令重排底层原理也解释清楚了,面试官可能会接着问你,你知道volatile使用场景吗?
单例模式(DCL-Double Check Lock双端检锁机制)就是它的使用场景