图神经网络历史脉络:
不动点理论:图神经网络(Graph Neural Network, GNN)-> 图卷积神经网络(Graph Convolutional Neural Network, GCN)
最早的GNN主要解决的还是分子结构分类等图论问题欧氏空间(图像 image )序列文本(text)很多场景可以转换成图 ,然后使用图神经网络建图。
2005 提出图神经网络
2009 Franco博士在其论文中定义了图神经网络的理论基础(它的理论基础是不动点理论:。给定一张图 GG,每个结点都有其自己的特征(feature), 本文中用xvxv表示结点v的特征;连接两个结点的边也有自己的特征,本文中用x(v,u)x(v,u)表示结点v与结点u之间边的特征;GNN的学习目标是获得每个结点的图感知的隐藏状态 hvhv(state embedding),这就意味着:对于每个节点,它的隐藏状态包含了来自邻居节点的信息。)
2013 图信号处理(Graph Signal Processing)Bruna首次提出图上基于频域(Spectral-domian)和基于空域(Spatial-domain)的卷积神经网络
2014 在word2vec [4]的启发下,Perozzi等人提出了DeepWalk [5],开启了深度学习时代图表示学习的大门。
Bordes等人提出了大名鼎鼎的TransE [6],为知识图谱的分布式表示(Represent Learning for Knowledge Graph)奠定了基础。
图均指图论中的图(Graph):是一种由若干个结点(Node)及连接两个结点的边(Edge)所构成的图形,用于刻画不同结点之间的关系。
状态更新与输出
最初,它的理论基础是不动点理论。
给定一张图 GG,每个结点都有其自己的特征(feature), 本文中用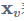 表示结点v的特征;连接两个结点的边也有自己的特征。
表示结点v的特征;连接两个结点的边也有自己的特征。
本文中用x(v,u)表示结点v与结点u之间边的特征;
GNN的学习目标是获得每个结点的图感知的隐藏状态 hvhv(state embedding),这就意味着:对于每个节点,它的隐藏状态包含了来自邻居节点的信息。那么,如何让每个结点都感知到图上其他的结点呢?
GNN通过迭代式更新所有结点的隐藏状态来实现,在t+1t+1时刻,结点vv的隐藏状态按照如下方式更新:

上面这个公式中的 ff 就是隐藏状态的状态更新函数,也被称为局部转移函数(local transaction function)。
公式中的xco[v]指的是与结点v相邻的边的特征,xne[v]指的是结点vv的邻居结点的特征,htne[v]则指邻居结点在t时刻的隐藏状态。
注意 f 是对所有结点都成立的,是一个全局共享的函数。
g被称为局部输出函数(local output function),描述如何适应下游任务:

与 f 类似,g 也可以由一个神经网络来表达,它也是一个全局共享的函数。那么,整个流程可以用下面这张图表达
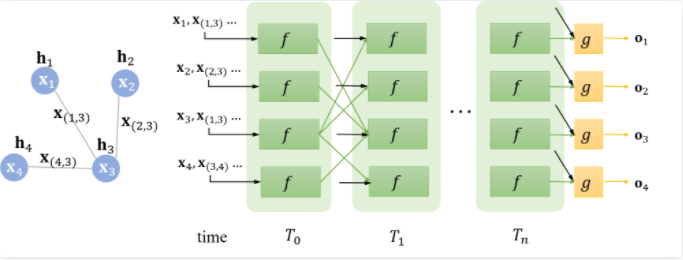

对于不同的图来说,收敛的时刻可能不同
实例:化合物分类
目标:给定一个环烃化合物的分子结构(包括原子类型,原子键等),模型学习的目标是判断其是否有害。、
这是一个典型的二分类问题,一个训练样本如下图所示:

化合物的分类实际上需要对整个图进行分类。
作者用图上红色的结点表示化合物的根结点的表示作为整个图的表示。
Atom feature 中包括了每个原子的类型(Oxygen, 氧原子)、原子自身的属性(Atom Properties)、化合物的一些特征(Global Properties)等。
不动点理论
GNN的理论基础是不动点(the fixed point)理论。这里的不动点理论专指巴拿赫不动点定理(Banach's Fixed Point Theorem)。首先我们用 F表示若干个 f堆叠得到的一个函数,也称为全局更新函数,那么图上所有结点的状态更新公式可以写成:
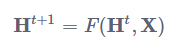
不动点定理指的就是,不论H0是什么,只要 F 是个压缩映射(contraction map),H0经过不断迭代都会收敛到某一个固定的点,我们称之为不动点。
下图对压缩映射做出解释:

上图的实线箭头就是指映射 F, 任意两个点 x,y在经过 F 这个映射后,分别变成了 F(x),F(y)。
压缩映射就是指,d(F(x),F(y))≤cd(x,y),0≤c<1。
也就是说,经过 F变换后的新空间一定比原先的空间要小,原先的空间被压缩了。
想象这种压缩的过程不断进行,最终就会把原空间中的所有点映射到一个点上。
f是由神经网络实现的,我们该如何实现它才能保证它是一个压缩映射呢?我们下面来谈谈 ff 的具体实现
具体实现


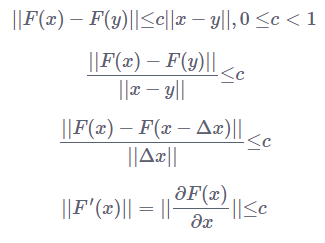
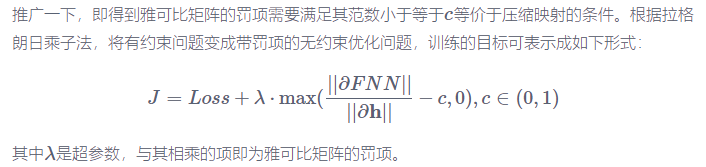
模型学习
下面我们来具体叙述一下图神经网络中的损失 Loss是如何定义,以及模型是如何学习的
以社交网络举例,虽然每个结点都会有隐藏状态以及输出,但并不是每个结点都会有监督信号(Supervision)。比如说,社交网络中只有部分用户被明确标记了是否为水军账号,这就构成了一个典型的结点二分类问题。

模型如何学习过程:根据前向传播计算损失的过程,不难推出反向传播计算梯度的过程。在前向传播中,模型
- 调用 ff若干次,比如 Tn次,直到 hTnv收敛。
- 此时每个结点的隐藏状态接近不动点的解。
- 对于有监督信号的结点,将其隐藏状态通过 g 得到输出,进而算出模型的损失
