一、引入问题
python语言的简洁性以及脚本特点十分适合连接和网页处理,因此在python的计算生态中,与url和网页处理有关的第三方库有很多。这些库的作用不同,使用方法不同,用户的体验也不同。其中我们今天就先来了解requests库、BeautifulSoup库。
二、requests库的使用
(一)requests库的概述
requests库是一个简洁且简单处理HTTP请求的第三方库,它的最大优点是程序编写过程更接近正常URL访问过程。这个库建立在python语言的urlib3库的基础上,类似这种在其他函数库之上再封装功能,提供更友好函数的方式在python语言中十分常见。在python生态圈里,任何人都有通过技术创新或体验创新发表意见和展示才华的机会。
(二)介绍requests库的一些函数
1、get()获取网页
import requests
#使用get方法打开淘宝连接
r = requests.get('http://ip.taobao.com/service/getIpInfo2.php?ip=111.174.77.14')
print(type(r))
结果:

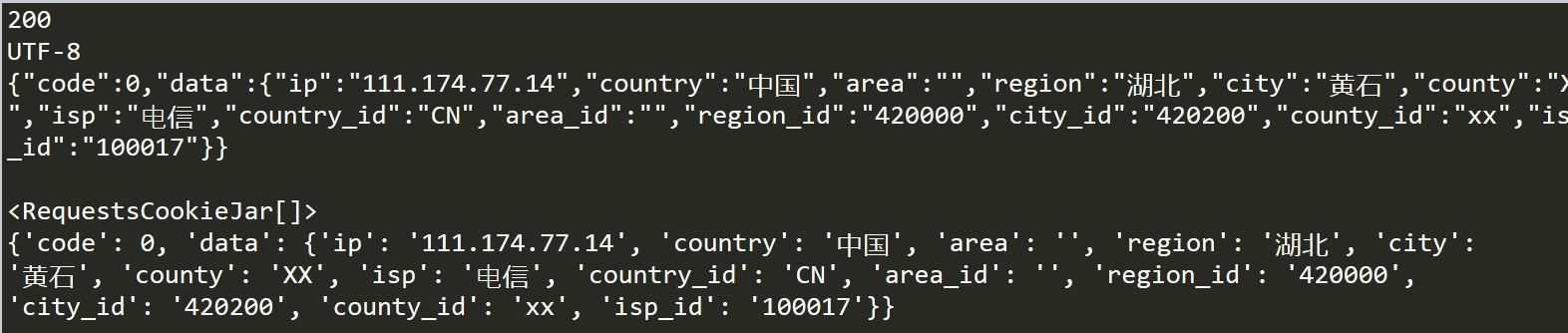
2、requests的一些基本方法
import requests
r = requests.get('http://ip.taobao.com/service/getIpInfo2.php?ip=111.174.77.14')
print(r.status_code)#打印get请求的状态码
print(r.encoding)#打印编码
print(r.text)#打印请求到的内容
print(r.cookies)
print(r.json())#输出json格式数据
结果:
3、根据以上内容进行实际操作
import requests
r = requests.get('http://ip.taobao.com/service/getIpInfo2.php?ip=111.174.77.14')
result = r.json()
country = result['data']['country']
area = result['data']['area']
region = result['data']['region']
print(country+area+region)
结果:

三、BeautifulSoup4库的使用
(一)BeautifulSoup4库的概述
BeautifulSoup是一种专门用于进行HTML/XML数据解析的一种描述语言,可以很好的分析和筛选HTML/XML这样的标记文档中的指定规则数据。在数据筛选过程中其基础技术是通过封装HTML DOM树实现的一种DOM操作,通过加载网页文档对象的形式,从文档对象树模型中获取目标数据。
(二)介绍BeautifulSoup4库的一些使用函数
import requests
from bs4 import BeautifulSoup
r = requests.get('http://www.baidu.com')
r.encoding = None
result = r.text
bs = BeautifulSoup(result,'html.parser')
print(bs.title)
print(bs.title.text)
结果:
