拖延症又犯了,不想写作业,但是冥冥之中想到了一句话:与其感慨路难行,不如马上出发。出自dota英雄骷髅弓箭手——克林克兹。于是就这样把我从泥潭中捞了出来。

——————————————————————————————————————————————————————
由于涉及到以后效率评判的问题,重新写了下代码。主要思想是利用二叉排序树结点存储英文单词,然后中序遍历树,将树的信息读取到结构体中,按照单词的频率排序并输出结果。
下面来说一下各部分代码:
1.树的节点的结构体,word用来储存单词的字符信息,考虑到几乎没有单词超过50字符长度,所以长度max设置为50,count是单词个数,*left和*right是指向左右儿子节点的指针。
1 stru啊ct tnode{asdas 2 char word[MAX]; 3 int count; 4 struct tnode *left,*right; 5 };
2.准备用来存储结点内容的表的结构体,理所当然,w要拷贝tnode中word的内容,所以长度也是50。
1 typedef struct word{ 2 int num; 3 char w[50]; 4 }List;
3. cmp()函数,比较两个字符的大小,为以后的qsot做准备。
1 int cmp(const void *a,const void *b) 2 { 3 List *p1 = (List*)a; 4 List *p2 = (List*)b; 5 if(p1->num!=p2->num) 6 return p2->num-p1->num; 7 else 8 return strcmp(p1->w,p2->w); 9 }
4.treeword()函数,作用是构建一个word树,传入一个结点指针(通常是根节点)和一个字符串指针,将word插入树的适当位置(与根节点作对比,若字符小于根节点字符,继续向做遍历,否则向右,直到访问到空指针,生成新的叶子节点),若指向的是树中原有的单词,则对应结点的num增加,若没有按照前面流程生成叶子节点。
1 struct tnode* treewords(struct tnode *p,char *w) 2 { 3 int cond; 4 if(p==NULL){ 5 p=(struct tnode*)malloc(sizeof(struct tnode)); 6 strcpy(p->word,w); 7 p->count=1; 8 p->left=p->right=NULL; 9 } 10 else if((cond=strcmp(w,p->word))==0) 11 p->count++; 12 13 else if(cond<0) 14 p->left=treewords(p->left,w); 15 16 else 17 p->right=treewords(p->right,w); 18 return (p); 19 }
5.treeprint()函数,传入一个节点指针(通常为根节点),然后将其作为根节点中序遍历整个子树。期间arr储存所有节点指针,并得到curr,节点的数目。
1 void treeprint(struct tnode *p) 2 { 3 if(p!=NULL){ 4 5 treeprint(p->left); 6 arr[curr++]=p; 7 treeprint(p->right); 8 9 } 10 }
6,主函数,较复杂,先贴出整个代码:
1 int main() 2 { 3 char word[MAX]; 4 char *fname ; 5 FILE *fin; 6 FILE *fout; 7 char c; 8 int i,k,n; 9 struct tnode *root; 10 root=NULL; 11 12 13 printf("文件输入请按一,标准输入请按二:"); 14 int sflag; 15 scanf("%d",&sflag); 16 17 if(sflag==1) 18 { 19 printf("请输入文件名称: "); 20 scanf("%s",fname); 21 fin = fopen(fname,"r"); 22 fout = fopen("result.txt","w"); 23 } 24 else 25 { 26 fin = stdin; 27 fout = stdout; 28 } 29 30 while((c=fgetc(fin))!=EOF){ 31 ungetc(c,fin); 32 for(i=0;(c=fgetc(fin))!=' '&&c!=' '&&c!=EOF;i++) 33 { 34 if((c>='A'&&c<='Z')||(c>='a'&&c<='z')) 35 { 36 c=tolower(c); 37 word[i]=c; 38 }else 39 break; 40 } 41 word[i]='�'; 42 if(strlen(word)>0) 43 root=treewords(root,word); 44 } 45 46 treeprint(root); 47 48 for(i=0;i<curr;i++) 49 { 50 list[i].num=arr[i]->count; 51 strcpy(list[i].w,arr[i]->word); 52 } 53 n=curr; 54 qsort(list,n+1,sizeof(list[0]),cmp); 55 56 for(k=0;k<curr;k++) 57 { 58 fprintf(fout,"%s %d ",list[k].w,list[k].num); 59 } 60 for(k=0;k<10;k++) 61 { 62 printf("%s %d ",list[k].w,list[k].num); 63 64 } 65 fclose(fin); 66 fclose(fout); 67 printf("Time used = %lf",(double)clock()/CLOCKS_PER_SEC); 68 return 0; 69 }
(1) 首先,这几行代码是选择文件输入,还是标准输入输出的,重定向更简单,只需要调用一下freopen。
printf("文件输入请按一,标准输入请按二:"); int sflag; scanf("%d",&sflag); if(sflag==1) { printf("请输入文件名称: "); scanf("%s",fname); fin = fopen(fname,"r"); fout = fopen("result.txt","w"); } else { fin = stdin; fout = stdout; }
(2)读入字符,一直读到EOF,并且检查字符串合法性,遇到大写字母转化为小写,不能同个单词统计两次。后面是将字符长度大于0的单词传入word树。
1 while((c=fgetc(fin))!=EOF){ 2 3 for(i=0;(c=fgetc(fin))!=' '&&c!=' '&&c!=EOF;i++) 4 { 5 if((c>='A'&&c<='Z')||(c>='a'&&c<='z')) 6 { 7 c=tolower(c); 8 word[i]=c; 9 }else 10 break; 11 } 12 word[i]='�'; 13 if(strlen(word)>0) 14 root=treewords(root,word); 15 }
(3)将arr的数据拷贝到list,然后利用list进行快排,然后两个for循环,一个是将结果写入txt,一个是将前十个结果输出到屏幕上。
1 treeprint(root); 2 3 for(i=0;i<curr;i++) 4 { 5 list[i].num=arr[i]->count; 6 strcpy(list[i].w,arr[i]->word); 7 } 8 n=curr; 9 qsort(list,n+1,sizeof(list[0]),cmp); 10 11 for(k=0;k<curr;k++) 12 { 13 fprintf(fout,"%s %d ",list[k].w,list[k].num); 14 } 15 for(k=0;k<10;k++) 16 { 17 printf("%s %d ",list[k].w,list[k].num); 18 19 }
下面展示运行结果:
1.从控制台输入文件名,然后在屏幕输出结果,并且同时生成一个txt保存结果。
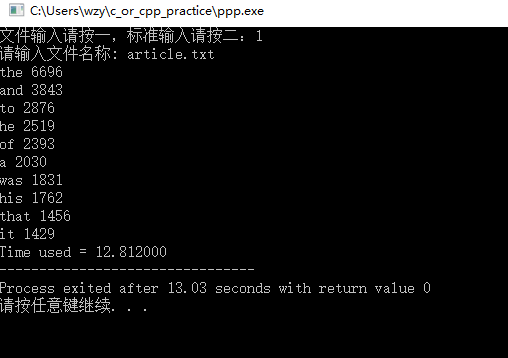
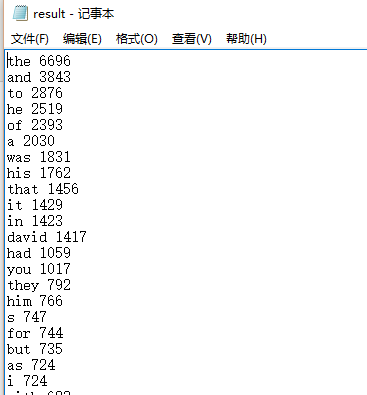
2,从控制台选择标准输入输出。

3.从cmd运行程序,输入文件名运行。

4,从cdm运行程序,进行标准输入输出。
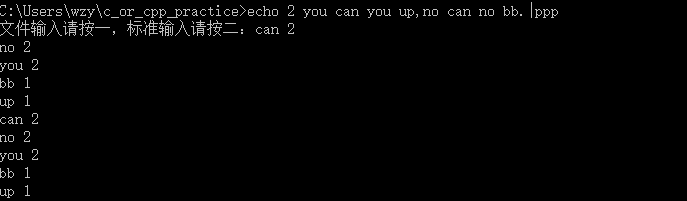
5,其余关于批量处理的还没有研究。
最最关键的必做题来了
1.个人项目耗时记录表1,B列是计划时间,D列是实际时间。

2.表二
项目:词频统计++
项目类型:个人项目
项目完成情况:已完成
项目改进:未变更
项目日期:2016.9.12-2016.9.13
12号
| 类别c | 内容c | 开始时间s | 结束e | 中断I | 净时间T |
| 项目实践 | 计划 | 9:20 | 9:45 | 5m | 20m |
| 项目实践 | 需求分析 | 10:00 | 10:40 | 10m | 30m |
| 项目实践 | 具体设计 | 10:40 | 13:50 | 130m | 60m |
| 项目实践 | 编码 | 15:30 | 16:30 | 0m | 60m |
| 项目实践 | 编码 | 20:30 | 24:00 | 30m | 180m |
13号
| 类别c | 内容c | 开始时间s | 结束e | 中断I | 净时间T |
| 项目实践 | 编码 | 00:00 | 00:40 | 0m | 40m |
| 项目实践 | 编码 | 10:30 | 11:30 | 10m | 50m |
| 项目实践 | 编码 | 13:40 | 15:00 | 50m | 30m |
| 项目实践 | 计算工作量 | 15:00 | 15:20 | 0m | 20m |
| 项目实践 | 写博客 | 20:00 | 23:45 | 45m | 180m |
对比表1,2,还是比较接近的,代码编写时间多了很多,那是编写时遇到了不少问题,网上比较水,关键时候还得认真看书。博客时间也多了一个小时,一是没想到写那么多,自己思路那么慢。
二是这个博客老是崩溃,加个图自己就卡了,有时需要重写,浪费好多时间。在表格里写东西光标居然不跟着移动。
最后,真的是眼睛好疼,先到这里了。