转自:https://blog.csdn.net/gracejpw/article/details/102593225
1.sklearn建立随机森林分类器
import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inline from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.datasets import load_wine from sklearn.model_selection import train_test_split wine = load_wine() wine wine.data wine.target #切分训练集和测试集 Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data,wine.target,test_size=0.3) #建立模型 clf = DecisionTreeClassifier(random_state=0) rfc = RandomForestClassifier(random_state=0) clf = clf.fit(Xtrain,Ytrain) rfc = rfc.fit(Xtrain,Ytrain) #查看模型效果 score_c = clf.score(Xtest,Ytest) score_r = rfc.score(Xtest,Ytest) #打印最后结果 print("Single Tree:",score_c) print("Random Forest:",score_r)
Single Tree: 0.8888888888888888
Random Forest: 0.9444444444444444
2.红酒数据集
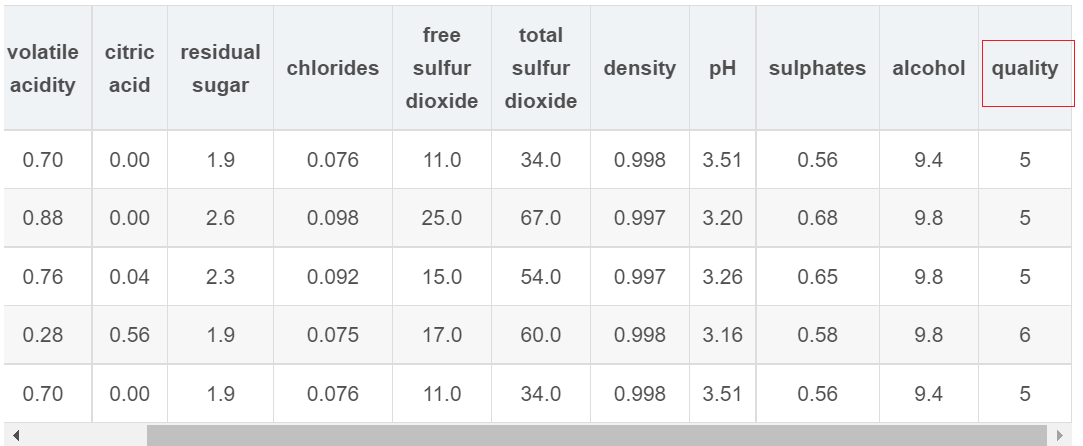
它包含11个特征,以及quality分数,从0至9表示10个级别,随机森林可以将它们成功地多分类。