——————————1月8日————————————
1. 继续这个https://www.cnblogs.com/BlueBlueSea/p/12129104.html来解决问题。
2.在这里搜到https://huggingface.co/transformers/main_classes/tokenizer.html
可以通过add_special_tokens函数来为bert的vocab添加特殊token,那么真的是这样的吗?如果我把<s1><e1>这些添加进去会出现什么问题吗?
//再次感觉到谷歌的厉害,百度真废。。
但是我凭空添加进去的token,并未经过预训练,那它的表示该如何获得?它的表时是否会有意义呢?
3.先来梳理一下bert的执行流程
①首先通过main函数获取控制台的输入参数:

匹配到对应的数据预处理:
②从预训练模型中加载tokenizer:
![]()
获取训练数据:
![]()
③加载预训练的bert模型:

④设置优化器:

⑤将训练数据转换为可以训练的格式:

⑥设置dataloader:

⑦对模型进行训练,计算损失函数:

并且进行反向传播更新参数:

以上①-⑦都是main函数中的内容。
4.论文中介绍了三种输入格式:
实体范围确认:(1)Standard input :并没有给出任何实体的边界信息,因为作者认为bert有这个能力去确认实体x的边界,但是这样的问题就是,当有多于两个实体的时候,无法确认是关注的哪两个实体间的关系。
(2)位置嵌入POSITIONAL EMB.:为了解决标准输入中无法确认是哪两个实体的问题,作者引入了两个新的分段嵌入,一个被添加到范围s1中,另一个被加入到范围s2中,
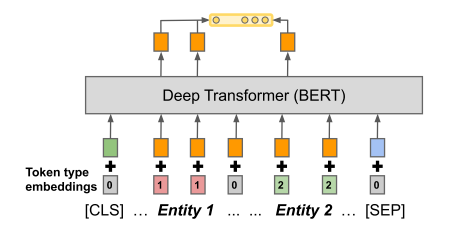
也就是这个样子的输入,对实体1位置标记为1,实体2位置标记为2,其他位置为0.
https://blog.csdn.net/u014108004/article/details/84142035在这个博客中可以看到,bert微调是很简单的过程,只需要修改processor就可以了,而不用设置其他segment嵌入和position嵌入。
(3)Entity marker tokens 实体标签标记:在实体范围中加入<s1><e1>/<s2><e2>标记。
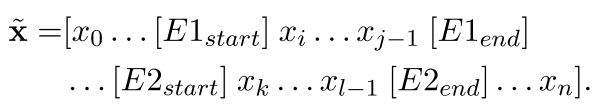
也就是将其变为一个新的插入后的序列。
5.论文中介绍的三种输出格式
从bert编码中,提取一个固定长度的表示,三种方法都依赖于bert的最后一层隐层输出,![]() 。
。
①[CLS] token:因为每个句子都以[CLS]作为开始,所以采取[CLS]对应的输出h0,作为关系的固定长度表示/
②Entity mention pooling 实体提及池:获取到对应![]() 和e2的,
和e2的,![]() ,进行拼接作为关系表示;
,进行拼接作为关系表示;
③实体开始状态 Entity start state:这种方法也十分简单,是针对第三种输入的,直接拼接两个token的开始标记的隐层输出。也就是<s1>和<s2>的输出。
![]()
6.对⑤将训练数据转换为可输入特征
①首先将单词分词,然后返回回实体1和实体2的位置信息:
![]()
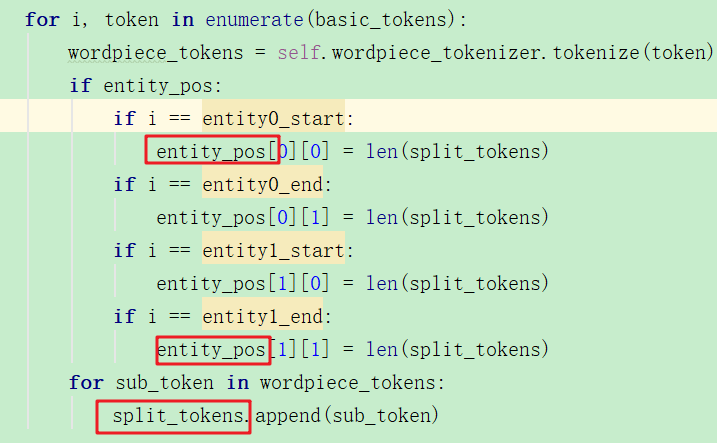
这里获得了new entity的位置标记信息:
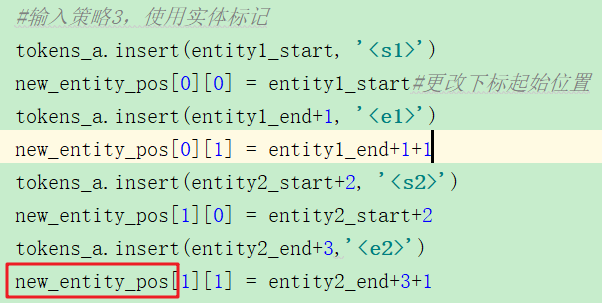
②获取到segment_ids,它是用来标记当前是第一句,还是第二句的,第一句的token都标记为0,第二句的token都标记为1.(当然这里没有第二句b)

③将输入由token转换为id,之后再进行padding补齐,补0:

//那我要使用第一种输入,不就得把代码各种给改了?我觉得还是不要吧,就先把当前这个第三种输入先运行出来。草。
那么问题来了,在将token转换为id的函数中:

如果token不在vocab中该如何处理?那就会报错。并且vocab的范围是有限的。这个应该如何处理?
我查看了源码,发现玄机在这里:

例如一个单词不在vocab中,那就会对它做切分,如果找到它的组成部分在vocab中,那么就将其存储。也就是说token进行了split之后,如果彻底找不到片段在vocab中,那么就设置为UNK了。可以显而易之的是,进行了tokensplit后,len(list)长度会大于等于原来的token长度。
但是我又觉得套代码有问题,为什么呢,因为它完全没有提到BLANK的事情,就很烦。
如果要解决这个oov的错误,很简单,那就将tokenize放在添加<s1><s2>等之后。
7.代码中不同的位置嵌入策略
因为bert中需要三阶段的输入,包括tokenid、位置嵌入信息、typeid(也就是前一句,还是后一句)
①:实体1被标记为1 ,实体2被标记为2,其余为0.(这里开始或结束都分别指示<s1><e1>)

②:两个实体token开始处的被设为1,其余为0。也就是对实体边界还是模糊的?
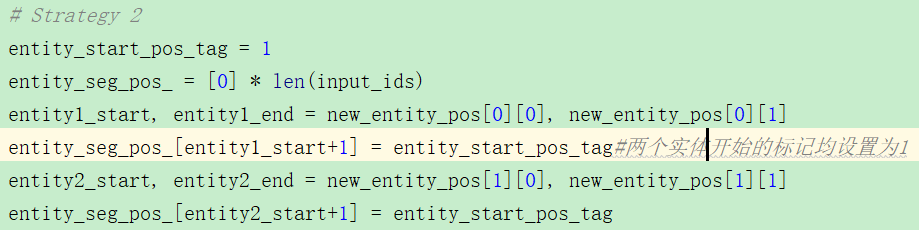
③:这个我觉得非常奇怪,居然实体1和实体2的pos信息还不一致,那它后续如何使用呢?
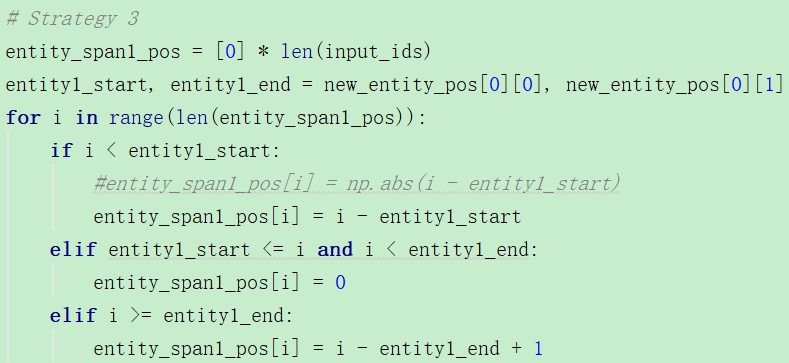
这里对实体1来说,左边是负值,实体表示为0,右边表示为正值。不明白这里有什么意义,之后在训练时又是如何使用的?
8.开始训练
获取到这些特征后,了解每个特征的意义:

转化为tensor并形成数据集:
![]()
然后就到了模型的forward部分,进行bert,获取bert的最终层的输出,这也太快了。。
![]()