1.基础模型
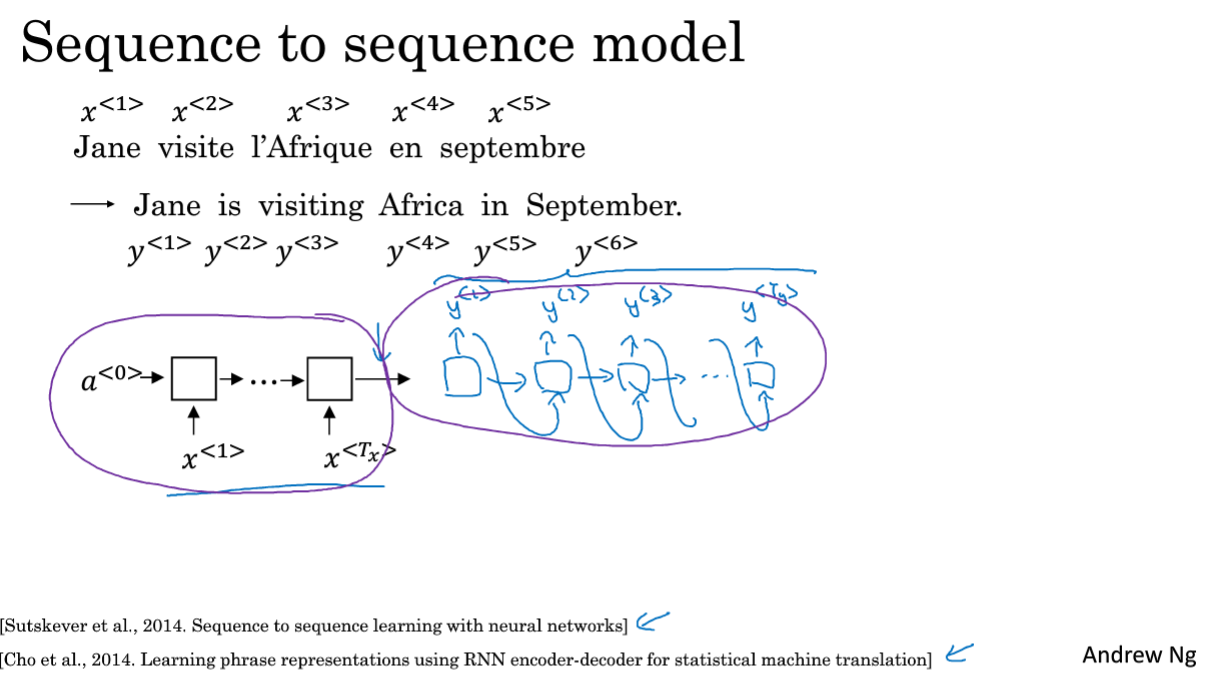
将法语翻译为英语,分为编码和解码阶段,将一个序列变为另一个序列。即序列对序列模型。
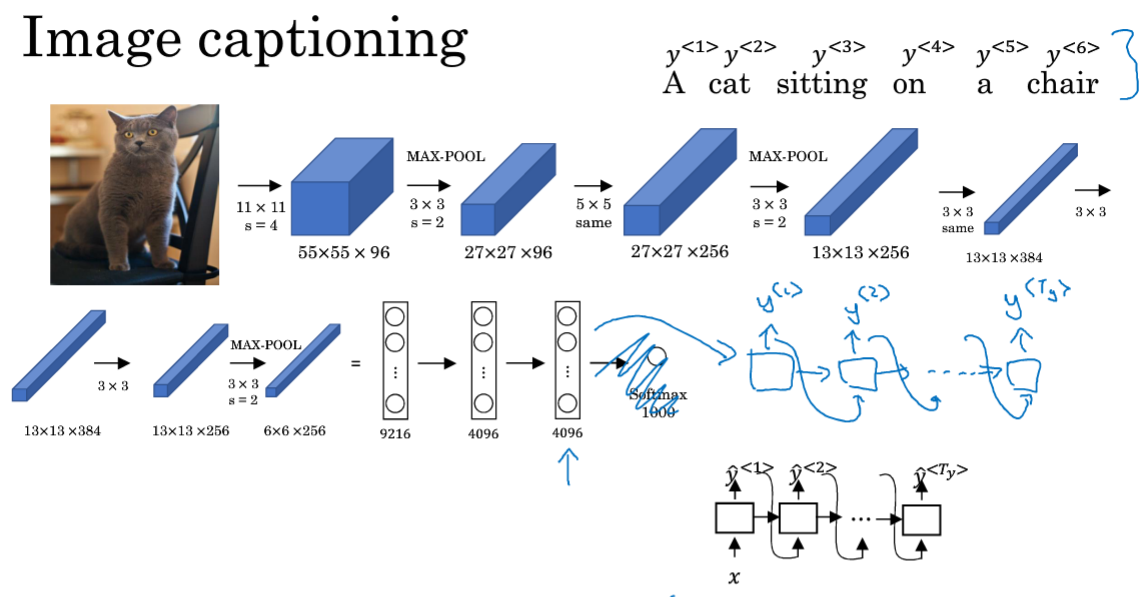
从图中识别出物体的状态,将图片转换为文字。
先使用CNN处理图片,再使用RNN将其转换为语言描述。
2.选择最可能的句子
7.注意力模型直观理解
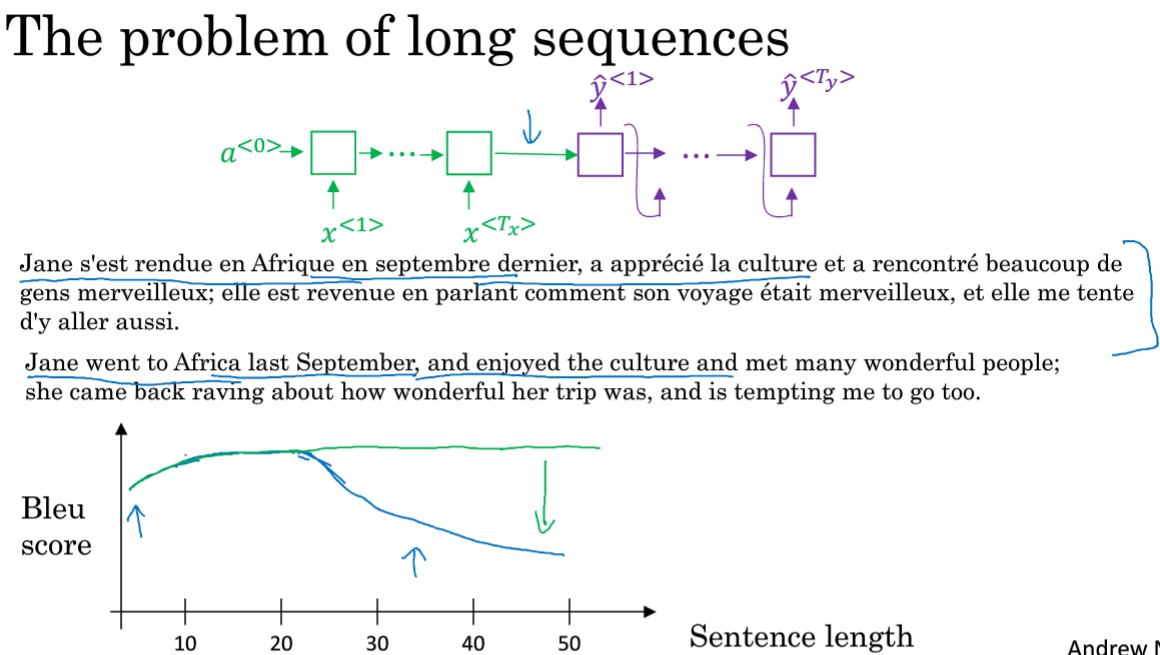
绿色部分是输入法语句子并记忆,在感知机中传递,紫色是解码网络,生成英文翻译;
人翻译的时候会选择看一段翻译一段,而在NN中如果是记忆整个句子,那效果就如Blue得分的蓝线随着单词的增长而降低。
在神经网络中,记忆长句子是很困难的。
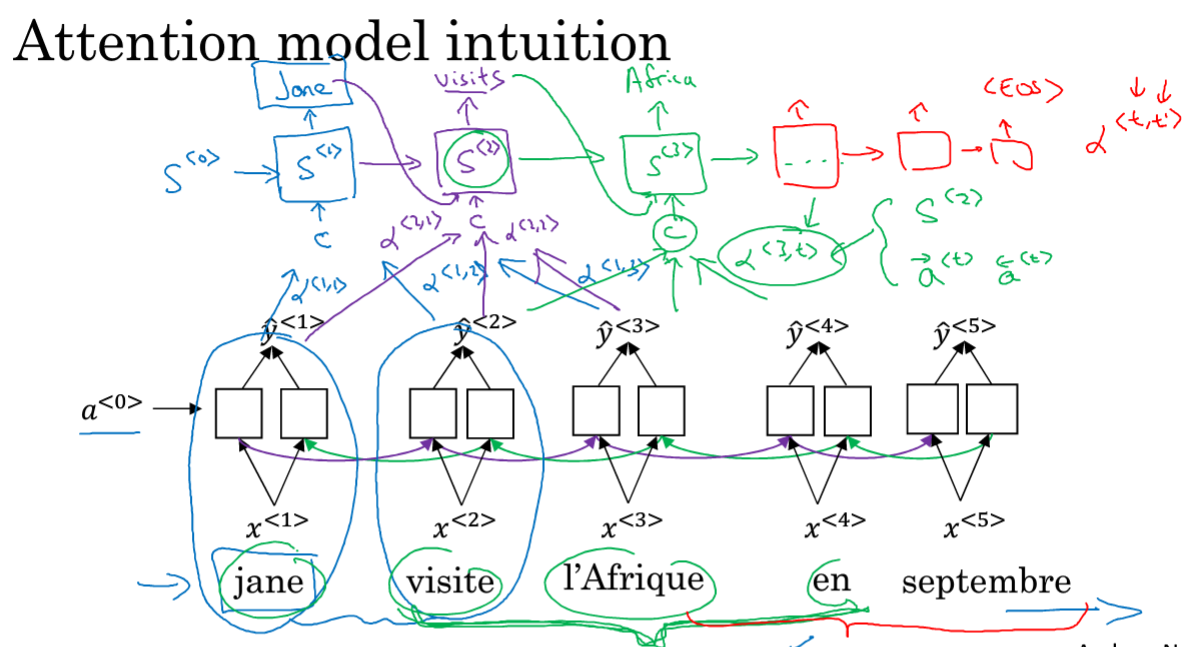
使用双向RNN获取特征集,使用另一个RNN来进行翻译。
在预测第一个单词Jane时,需要考虑法语中jane和其附近的词,这时会根据距离给予每个单词一个注意力权重,
比如对jane是α<1,1>,visite是a<1,2>,l'Afrique是a<1,3>这样将原来的网络输入根据不同的权重来预测单词Jane;
在生成第二个单词的时候,又会有(紫色笔)不同的注意力权重, 并且输入上一个单元的输出;绿色笔是预测第三个词。
α<t,t’>会告诉在尝试生成第T个英文单词,应该花多少注意力在第t个法语词上,当生成一个特定的英文词时,它允许在每个时间步内去看周围词距内的法语需要多少注意力。
8.注意力模型
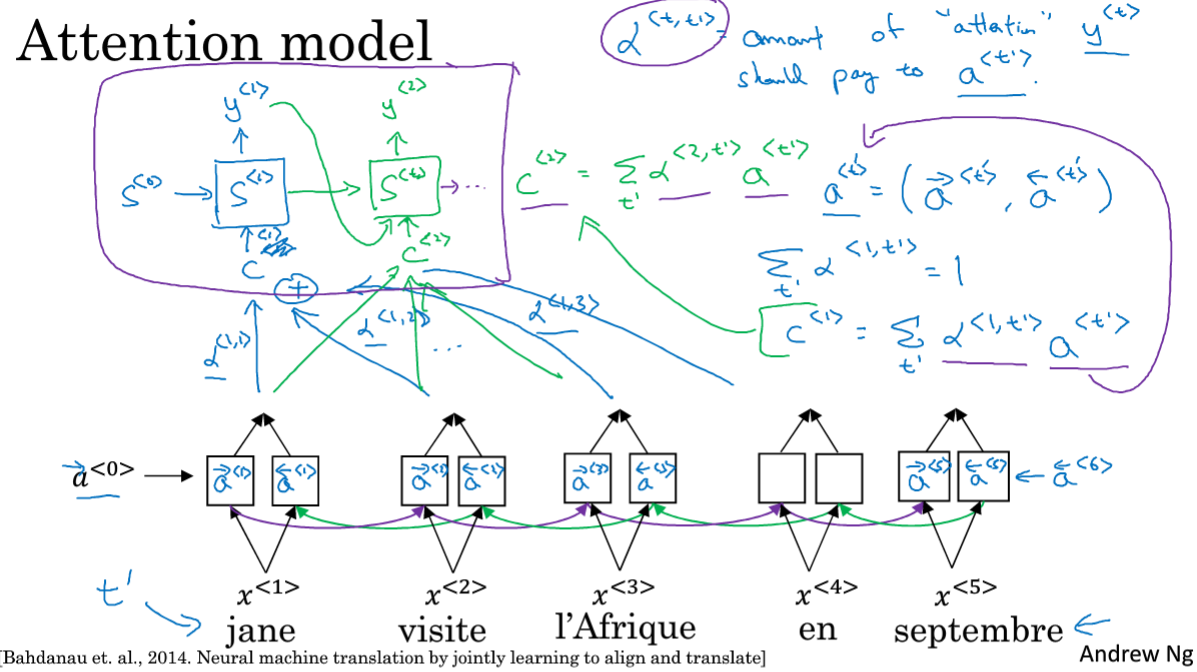
是将上一节的进行了一点展开讲解,对于预测某一单词,Σα<1,t'>=1,是说在生成第一个单词的时候,总共t'个可影响的单词,它们的影响总和为1,并且状态C是根据其对应的注意力来计算的。
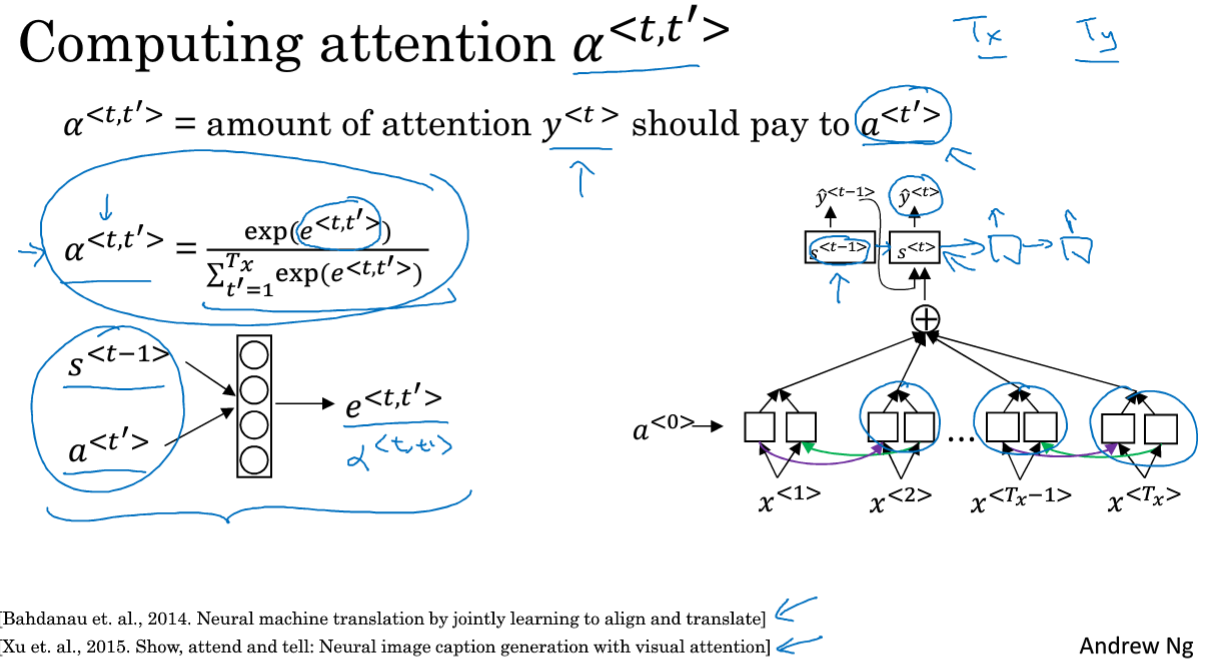
softmax函数能够保证和为1,左下角的图输入为上一个预测结果和当前词的Attention,右下角的图也就是左下角的具体化。
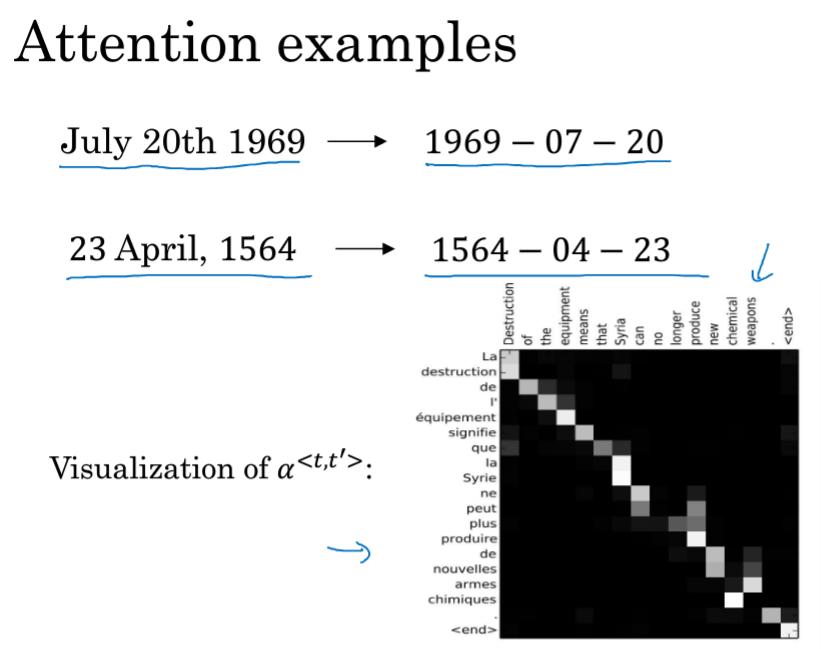
右下角的图左边是出入,上面是输出,能够发现注意力??