一、TF-IDF(Term Frequency-Inverse Document Frequency,词频-逆文件频率)的定义
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。即,一个词语在一篇文章中出现的次数越多,同时在所有文档中出现的次数越少,越能够代表该文章,越能反映文章的特性,这就是TF-IDF的含义。
1)词频(TF,Term Frequency),一般指的给定某一个词语在该文件中出现的次数,这个数字一般会被归一化(一般是词频除以文章总次数)。一些通用的词语对于主题并没有太大的作用,反倒是一些出现频率较少的词才能够表达文章的主题和特征,所以单纯的使用TF不够准确。权重的设计:一个词预测主题能力越强,权重越大;反之,权重越小。所有统计的文章中,如果一些词只是在其中很少的文章中出现,那么这样的词对文章的主题的作用很大,这些词的权重应该设计的较大,这就是IDF完成的工作所在。
公式:

2)逆向文件频率(IDF,inverse document frequency)的主要思想:如果包含该词的文档越少,分母越小,IDF越大,这说明IDF有很好的类区分能力;如果包含该词的文档越多,即该词越常见,分母越大,IDF就越小。
公式:
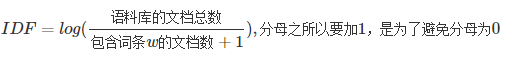
3)在某个文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,则TF较高,IDF也较高,可以产生出高权重的TF-IDF,说明这个词语对文章的重要性越大,因此TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
TF-IDF=TF*IDF(可以看到,TF-IDF与TF成正比,也就是说TF-IDF和一个词在文档中的出现次数成正比;TF-IDF与IDF成反比,也就是说TF-IDF和一个词在所有文档中的出现次数(包含该词的文档数)成反比,处于分母部分。
4)应用
*自动提取某篇文章中的关键字,就是计算出文档的每个词的TF-IDF值,降序排列,前几名就是该文章的主要关键字。处理文本时,对于一篇文章,文章由很多的词组成,通过与停用词表相对比,我们容易过滤掉一些停用词(stopwords,比如“的”,“是”等),只保留一些关键字,但是剩下的关键词也不是同等重要的,我们要确定这些词在文章中的权重,这样才能确定文章的主题,我们可以通过使用TF-IDF算法来计算各个关键词的权重。
*信息检索时,对于每个文档,都可以分别计算一组搜索词(“中国”、“蜜蜂”、“养殖”)的TF-IDF,将它们相加就可以得到整个文档的TF-IDF,这个值最高的文档就是与搜索词最匹配的文档。
5)TF-IDF算法的优缺点
优点:简单快速,结果比较符合实际情况;
缺点:单纯以”词频”来衡量一个词的重要性,显然不够全面,有时候重要的词语可能出现的次数并不多,而且这种算法无法体现词在文章中的位置信息,出现位置靠前的词语和出现位置靠后的词语都一视同仁,这是不正确的,因为有可能对全文的第一段和某段的第一句,应该给予较大的权重。
二、TF-IDF的python代码实现文本的关键字提取
主要思想就是先进行预处理一下,先将文本结巴分词进行分词操作,再停用词表进行过滤掉停用词,剩下出文本的一些关键字,然后计算每个词的TF-IDF值,按照TF-IDF值降序输出关键词。
python代码实现:
参考链接:
http://www.ruanyifeng.com/blog/2013/03/tf-idf.html
https://blog.csdn.net/zrc199021/article/details/53728499
https://blog.csdn.net/google19890102/article/details/29369793