一、grep家族
grep是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
在上一次的博客中已经使用过egrep通过正则表达式来匹配正确IP地址,这里的用法就不多说了。
fgrep 命令于 grep 和 egrep 命令不同,因为它搜索字符串而不是搜索匹配表达式的模式。fgrep 命令使用快速的压缩算法。$, *, [, |, (, ) 和 等字符串被 fgrep 命令按字面意思解释。这些字符并不解释为正则表达式,但它们在 grep 和 egrep 命令中解释为正则表达式。
用fgrep搜索字符串如下例子:

二、sed
sed意为流编辑器(Stream Editor),在Shell脚本和Makefile中作为过滤器使用非常普遍,也就是 把前一个程序的输出引入sed的输入,经过一系列编辑命令转换为另一种格式输出。(主要用来编辑一个或多个文件;简化对文件的反复操作)
编辑命令格式为:
pattern/action pattern正则表达式,action为编辑操作
sed编辑过程:

这过程中文件内容没有改,除非使用重定向存储输出。
如下例子:


log文件中的内容:

1./pattern/p:打印匹配pattern的行。

由上图可知sed是把待处理文件的内容连同处理结果一起输出到标准输出的,因此p命令 表示除了把文件内容打印出来之外还额外打印一遍匹配pattern的行。
要想只输出处理结果,应加上-n选项,这种用法相当于grep命令
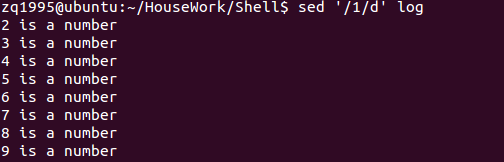
2、/pattern/d:删除匹配的行
如下图:
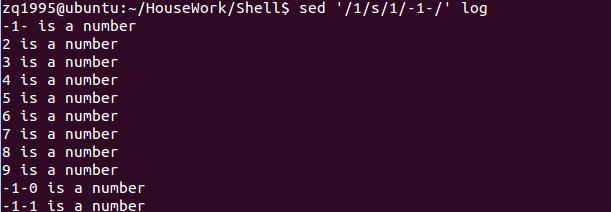
3. /pattern/s/pattern1/pattern2/:查找符合pattern的行,将该行第一个匹配pattern1的字符串替换为pattern2
4. /pattern/s/pattern1/pattern2/g:查找符合pattern的行,将该行所有匹配 pattern1的字符串替换为pattern2
以下是这两个的实现从中可以看出区别:

5、sed -i会修改原文件

6、正则表达式
与grep一样, sed也支持特殊元字符,来进行模式查找、替换。不同的是, sed使用的正则表达式是括在斜杠线"/"之间的模式。
^:行首定位符
$:行尾定位符
.:匹配除换行符以外的单个字符
*:匹配零个或多个前导字符
[]:匹配指定字符组内的任意字符
[^]:匹配不在指定字符组内的任意字符
&:保存查找串以便在替换串中引用: s/test/*&*/g 符号&代表查找串。 test将被替换为*test*
三、awk
sed以行为单位处理文件,awk比sed强的地方在于不仅能以行为单位还能以列为单位处理文
件。 awk缺省的行分隔符是换行,缺省的列分隔符是连续的空格和Tab,但是行分隔符和列分隔
符都 可以自定义。
编辑命令的格式为: /pattern/{actions}
awk程序一行一行读出待处理文件,如果某一行与pattern匹配,或者满足condition条件,则执行相应的actions,如果一条awk命令只 有actions部分,则actions作用于待处理文件的每一行。
自动变量$0、$1、$2分别表示一整行、第一列、第二列等;

awk命令的condition部分还可以是两个特殊 的condition-BEGIN和END,对于每个待处理文文件,BEGIN后面的actions在处理整个文件之前执行 一次, 后面的END actions 在整个文件处理完之后执行一次。