1.单变量分析绘图
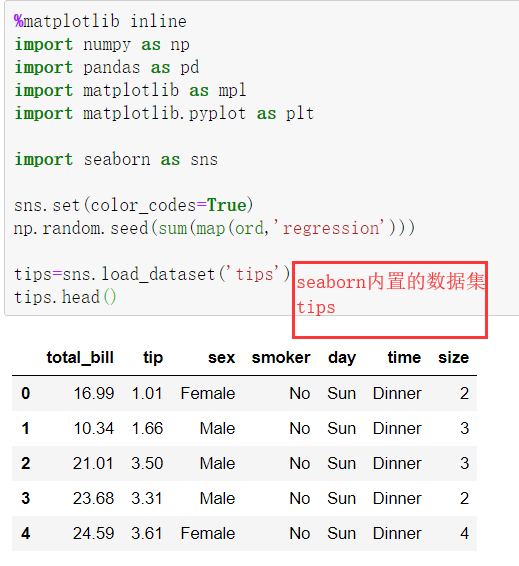
%matplotlib inline import numpy as np import pandas as pd import matplotlib as plt from scipy import stats,integrate import seaborn as sns sns.set(color_codes=True) np.random.seed(sum(map(ord,'distributions'))) x = np.random.normal(size=100) sns.distplot(x,kde=False)
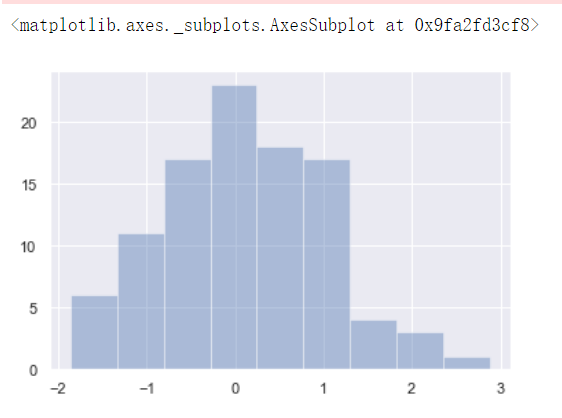
数据分布情况
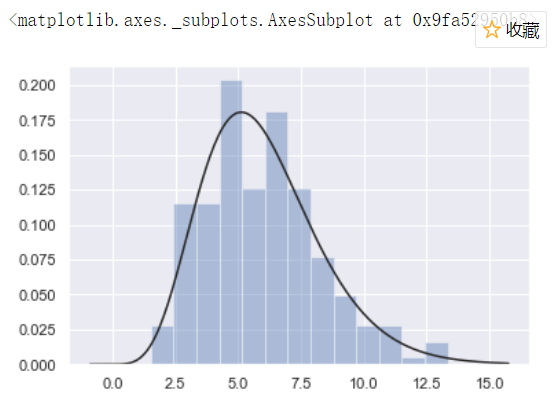
sns.distplot(x,bins=20,kde=False) bins=20 平均分成20等份 x = np.random.gamma(6,size =200) sns.distplot(x,kde=False,fit=stats.gamma)
kdeplot(核密度估计图)
核密度估计(kernel density estimation)是在概率论中用来估计未知的密度函数,属于非参数检验方法之一。通过核密度估计图可以比较直观的看出数据样本本身的分布特征
numpy.random.gamma
numpy.random.gamma(形状,比例= 1.0,尺寸=无)-
从Gamma分布中抽取样本。
从具有指定参数,形状(有时指定为“k”)和比例(有时指定为“theta”)的Gamma分布中抽取样本 ,其中两个参数均> 0。
参数: - shape : float或array_like浮点数
-
伽玛分布的形状。应该大于零。
- scale : float或array_like浮点数,可选
-
伽玛分布的规模。应该大于零。默认值等于1。
- size : int或int的元组,可选
-
输出形状。如果给定的形状是例如,则 绘制样本。如果大小为(默认),单值,如果返回,并都标量。否则,绘制样本。
(m, n, k)m * n * kNoneshapescalenp.broadcast(shape, scale).size
返回: - out : ndarray或标量
-
从参数化的伽玛分布中提取样本。
也可以看看
scipy.stats.gamma
distplot
displot()集合了matplotlib的hist()与核函数估计kdeplot的功能,增加了rugplot分布观测条显示与利用scipy库fit拟合参数分布的新颖用途。具体用法如下:
seaborn.distplot(a, bins=None, hist=True, kde=True, rug=False, fit=None, hist_kws=None, kde_kws=None, rug_kws=None, fit_kws=None, color=None, vertical=False, norm_hist=False, axlabel=None, label=None, ax=None)
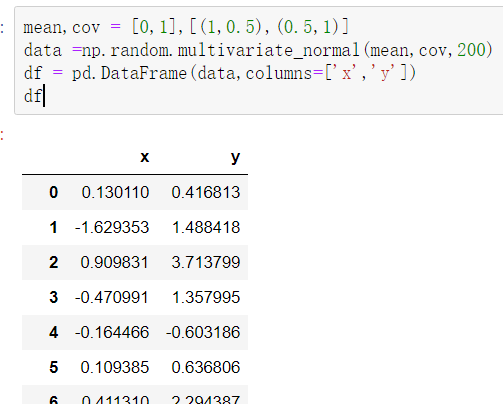
根据均值和协方差生成数据
mean,cov = [0,1],[(1,.5),(.5,1)] 均值,协方差 data =np.random.multivariate_normal(mean,cov,200) df = pd.DataFrame(data,columns=['x','y']) df
numpy.random.multivariate_normal
numpy.random.multivariate_normal(mean, cov, size, check_valid, tol)
| 参数: |
|
|---|---|
| 返回: |
|
pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False) 参数: data : ndarray(结构化或同类),Iterable,dict或DataFrame Dict可以包含Series,数组,常量或类似列表的对象 在版本0.23.0中更改:如果数据是dict,则为Python 3.6及更高版本维护参数顺序。 index : 索引或类似数组 用于结果框架的索引。如果没有索引信息部分输入数据且没有提供索引,则默认为RangeIndex columns : 索引或类似数组 用于生成框架的列标签。如果未提供列标签,则默认为RangeIndex(0,1,2,...,n) dtype : dtype,默认无 要强制的数据类型。只允许一个dtype。如果没有,推断 copy : boolean,默认为False 从输入中复制数据。仅影响DataFrame / 2d ndarray输入
观测两个变量之间的分布关系最好用散点图
sns.jointplot(x='x',y='y',data=df) sns.jointplot(x=df['A'], y=df['B'],data = df)
#设置xy轴,显示columns名称 #设置数据
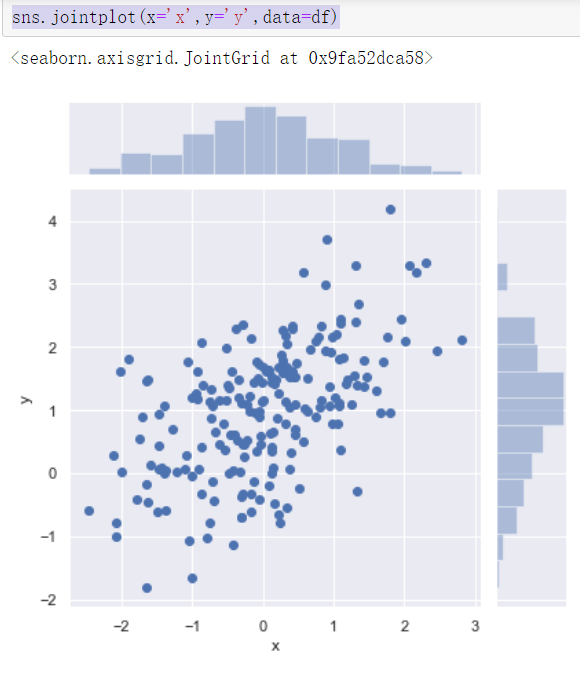
x,y =np.random.multivariate_normal(mean,cov,1000).T
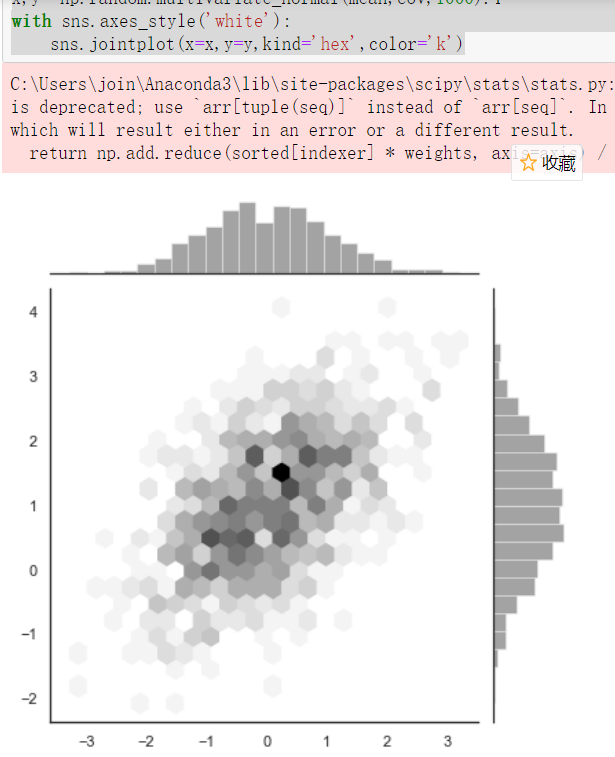
with sns.axes_style('white'):
sns.jointplot(x=x,y=y,kind='hex',color='k')
通过sns.axes_style(style=None, rc=None) 返回一个sns.set_style()可传的参数的字典
kind = 'scatter',#设置类型
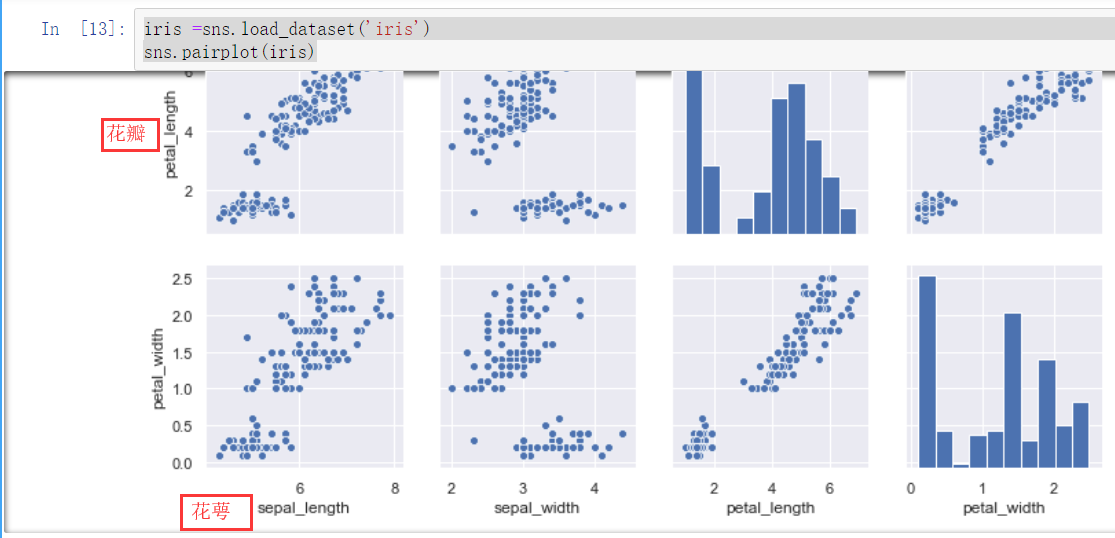
iris =sns.load_dataset('iris') iris是seaborn自己的一个鸢尾花的数据集 sns.pairplot(iris) 将花瓣,花萼的长度宽度作比较
2.回归分析绘图
regplot()和Implot()都可以绘制回归分析图,建议第一种
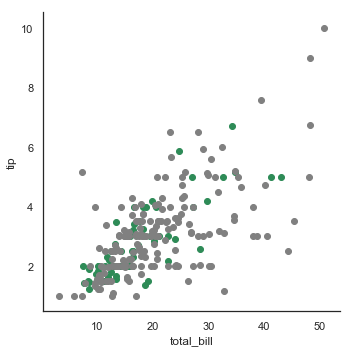
sns.regplot(x='total_bill',y='tip',data=tips) 全称 regressionplot
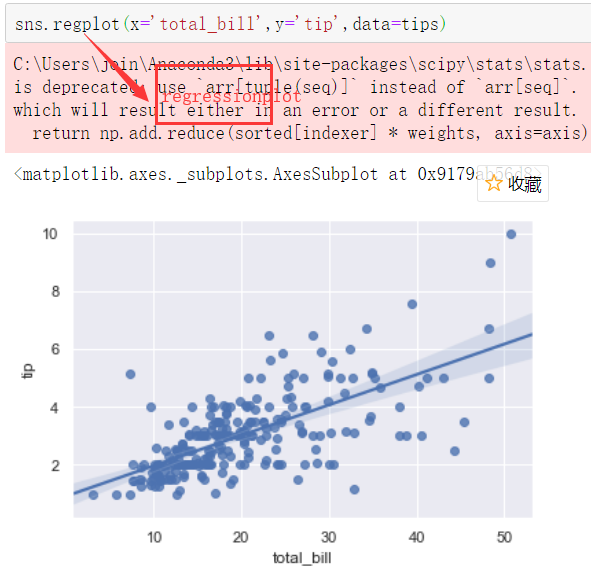
3.多变量分析绘图
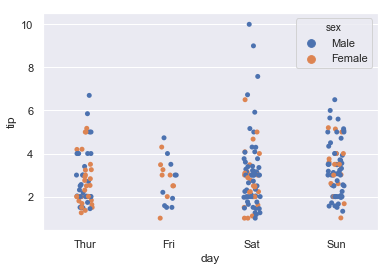
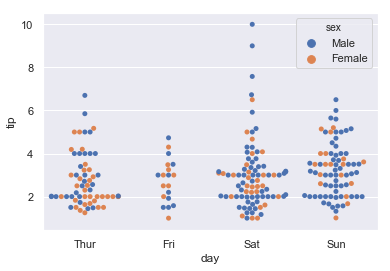
sns.stripplot(x='day',y='tip',hue='sex',data=tips) hue分不同种类数据的column name sns.swarmplot(x='day',y='tip',hue='sex',data=tips)
swarmplot:绘制具有非重叠点的分类散点图。
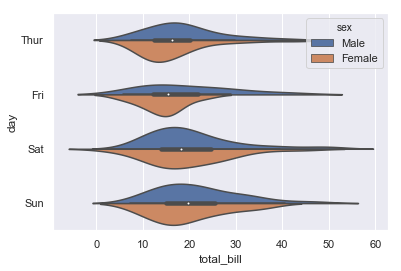
sns.violinplot(x='total_bill',y='day',hue='sex',data=tips,split=True) 俗称小提琴图,越胖的地方数据就越多
4.分类属性绘图
sns.barplot(x='day',y='total_bill',hue='size',data=tips) 显示值得集中趋势可以用条形图

sns.pointplot(x='day',y='total_bill',hue='size',data=tips) 点图可以更好的描述变化差异
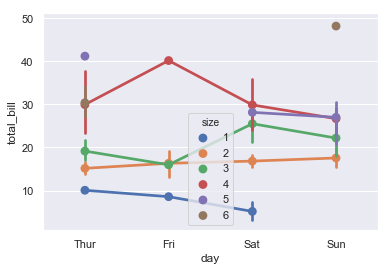
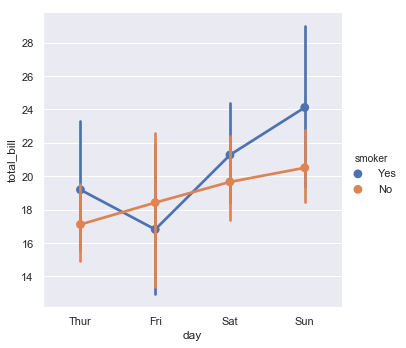
sns.factorplot(x='day',y='total_bill',hue='smoker',data=tips) 多层面板分类图

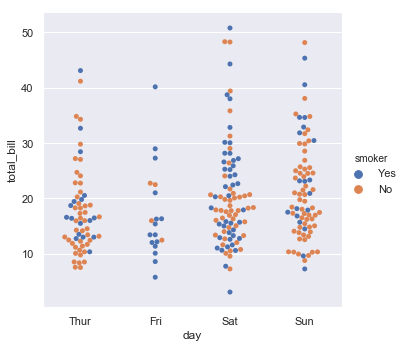
sns.factorplot(x='day',y='total_bill',hue='smoker',data=tips,kind='swarm')
5.facetgrid函数
用于展示子集
g = sns.FacetGrid(tips,col='time') col:列 sns.set_style('white')
g = sns.FacetGrid(tips,col='time') g.map(plt.hist,'tip') hist:条形图
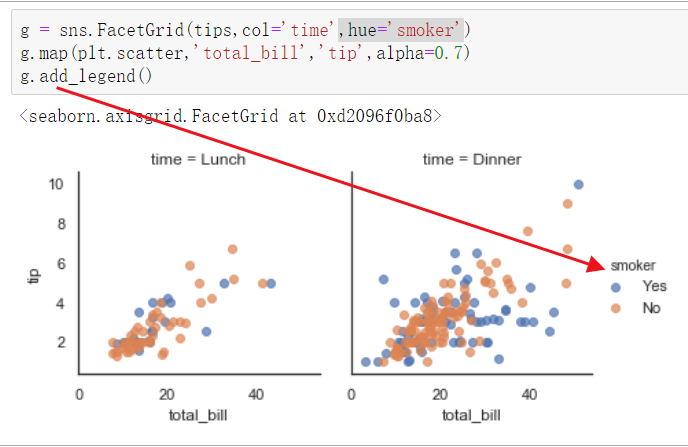
g = sns.FacetGrid(tips,col='time',hue='smoker') g.map(plt.scatter,'total_bill','tip',alpha=0.7) scatter散点图,alpha散点图的透明程度 0-1越来越深 g.add_legend()
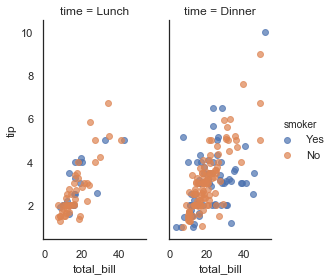
g = sns.FacetGrid(tips,col='time',hue='smoker',size=4,aspect=0.5) g.map(plt.scatter,'total_bill','tip',alpha=0.7) edgecolor:边界颜色 如'white' linewidth 线宽 s:散点的大小 g.add_legend()
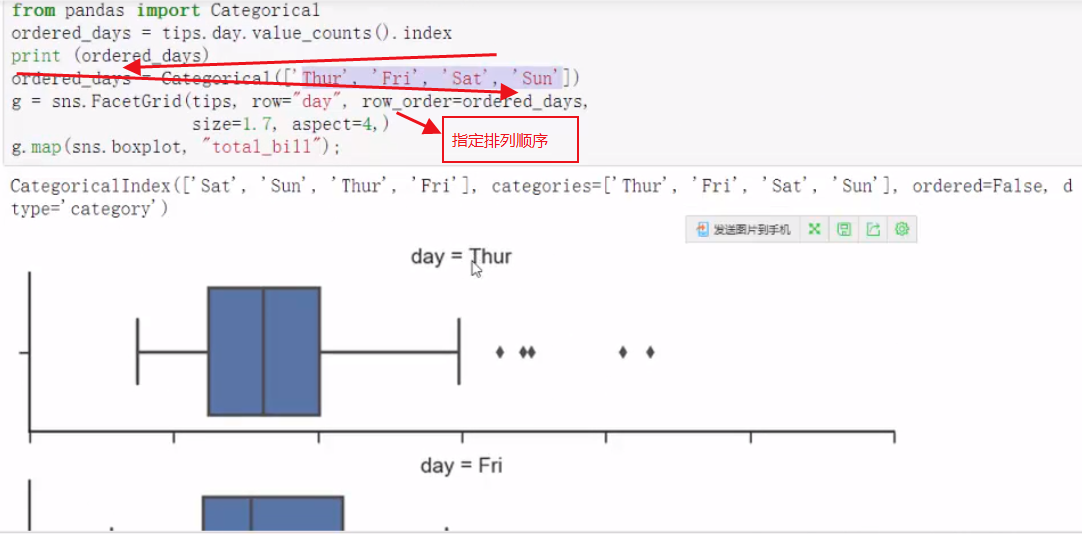
pal = dict(Lunch='seagreen',Dinner='gray') g=sns.FacetGrid(tips,hue='time',palette=pal,size=5) palette:调色板 hue_kws:指定什么形状(圆形,三角形。。)
g.map(plt.scatter,'total_bill','tip')
6.热度图(heatmap)
对于一离散性数据,通过热度图颜色变化的趋势表示出数值的变化
%matplotlib inline import numpy as np np.random.seed(0) import seaborn as sns import matplotlib.pyplot as plt sns.set()
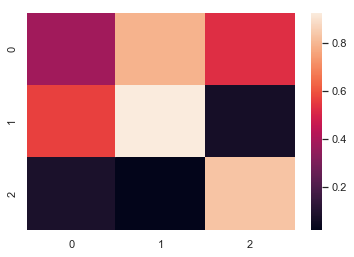
uniform_data = np.random.rand(3,3) 随机生成一个3x3的矩阵 print(uniform_data) heatmap = sns.heatmap(uniform_data)
[[0.38344152 0.79172504 0.52889492] [0.56804456 0.92559664 0.07103606] [0.0871293 0.0202184 0.83261985]]
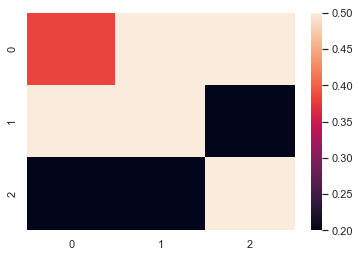
ax = sns.heatmap(uniform_data,vmin=0.2,vmax=0.5) 小于0.2显示一种颜色,大于0.5的显示一种颜色
normal_data = np.random.randn(3,3) print(normal_data) jeatmap = sns.heatmap(normal_data,center=0) center=0,相当于0点,大于0颜色越深数值越大,反之,同理
[[ 1.53502913 0.56644004 0.14926509] [-1.078278 1.39547227 1.78748405] [-0.56951726 0.17538653 -0.46250554]]

flights = sns.load_dataset('flights') flights也是seaborn内置的数据集 flights.head()
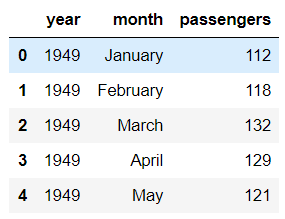
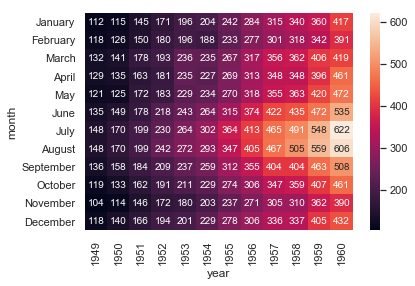
flights = flights.pivot('month','year','passengers') pivot行转列函数,即month是列 print(flights) sns.heatmap(flights)
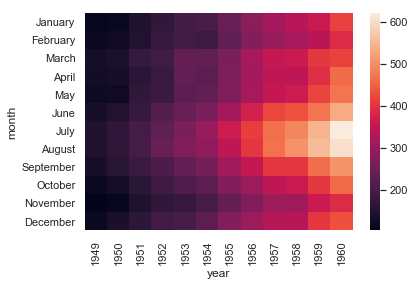
ax =sns.heatmap(flights,annot=True,fmt='d') annot:把数据插入进来 linewidth:设置格子之间的间距(图中格子是没有间距的) cmap:调色板 cbar=False 把图中右边的条形柱隐藏掉
fmt格式化,如果去掉图里面的数会乱码