一、递归的定义
在高级语言中,调用自己和其他函数并没有本质的不同。把一个直接调用自己或通过一系列的调用语句间接地调用自己的函数,称作递归函数。
递归算法求解问题的基本思想是:对于一个较为复杂的问题,把原问题分解成若干个相对简单且类似的子问题,这样较为复杂的原问题就变成了相对简单的子问题;而简单到一定程度的子问题可以直接求解;这样,原问题就可以递推得到解。
1.适用于递归算法求解的问题的充分必要条件是:
(1)问题具有某种可借用的类同自身的子问题描述的性质
(2)某一有限步的子问题(也称作本原问题)有直接的解存在
2.当一个问题存在上述两个基本要素时,设计该问题的递归算法的方法是:
(1)把对原问题的求解表示成对子问题求解的形式
(2)设计递归出口
二、递归和迭代的区别
斐波那契数列数如下,现在想要用迭代和递归来打印出前40为斐波那契数列数
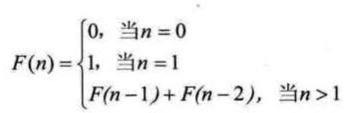
1.迭代算法
int main() { int i; int a[40]; a[0]=0; a[1]=1; printf("%d ",a[0]); printf("%d ",a[1]); for(i = 2;i < 40;i++) { a[i] = a[i-1] + a[i-2]; printf("%d ",a[i]); } printf(" "); return 0; }
2.递归算法
int Fbi(int i) /* 斐波那契的递归函数 */ { if( i < 2 ) return i == 0 ? 0 : 1; return Fbi(i - 1) + Fbi(i - 2); /* 这里Fbi就是函数自己,等于在调用自己 */ } int main() { int i; for(i = 0;i < 40;i++) printf("%d ", Fbi(i)); return 0; }
3.迭代和递归的区别
迭代使用的是循环结构,递归使用的是选择结构。
递归能使程序的结构更清晰、更简洁、更容易让人理解,从而减少读懂代码的时间。但是大量的递归调用会建立函数的副本,会耗费大量的时间和内存。
迭代不需要反复调用函数和占用额外的内存。
三、递归和栈的关系
1.外部程序调用非递归函数时
对于非递归函数,外部程序在进行函数调用时,系统要保存两类信息:(1)外部程序的返回地址;(2)外部程序的变量当前值
当执行完被调用函数,返回外部程序前,系统首先要恢复外部程序的变量当前值,然后返回外部程序的返回地址。
2.递归函数的执行过程的三个特点
①函数名相同;②不断地自调用③最后被调用的函数要最先被返回
3.外部程序调用递归函数时,系统要做的工作
系统使用堆栈来保存递归函数调用的信息。系统用于保存递归函数调用信息的堆栈称为运行时栈。每一层递归调用所需保存的信息构成运行时栈的一个工作记录,在进入下一层递归调用时,系统就建立一个新的工作记录,并把这个工作记录进栈称为运行时栈的新栈顶;当返回一层递归调用时,系统就退栈一个工作记录。这样,栈顶的工作记录中保存的就一定是当前调用函数的信息。
因为栈顶的工作记录保存的是当前调用函数的信息,所以栈顶的工作记录也称为活动记录。
4.简而言之递归与栈的作用
递归过程需要执行它的前行和退回阶段。递归过程退回的顺序是它前行顺序的逆序。在退回过程中,可能要执行某些动作,包括恢复在前行过程中存储起来的某些数据。这种存储某些数据,并在后面右以存储的逆序恢复这些数据,以提供之后使用的需求,显然,编译器就是使用栈来实现递归的。
对于每一层递归,函数的局部变量、参数值以及返回地址都被压入栈中。在退回阶段,位于栈顶的局部变量、参数值和返回地址被弹出,用于返回调用层次中执行代码的其余部分,也就是恢复了调用的状态。
四、递归算法到非递归算法的转换
一般来说,如下两种情况的递归算法可以转换成非递归算法
(1)有些问题(如阶乘问题),既存在递归结构算法,也存在循环结构算法
(2)存在借助堆栈的循环结构算法。所有递归算法都可以借助堆栈转换成循环结构算法。此时有两种转换方法:
①借助堆栈,用非递归算法形式化模拟递归算法的执行过程。
②根据要求的问题的特点,设计借助堆栈的循环结构算法。