问题
- 分布式哈希一致性的动机是什么?
- 相比其他有什么好处
概述
我们谈论的分布式哈希一致性常常使用在负载均衡,权衡一个策略的好坏,我们常常谈到扩展性和容错性。我们可以从以下两个方面来考量
- 扩展性 :水平扩展和垂直扩展,加减一台cluster 是否对整个集群有影响。
- 容错性 :假如一台cluster 是否会影响到其他的 cluster,是否可以用比较小的代价进行恢复。
负载均衡
负载均衡使用的策略 :
- 随机访问策略。系统随机访问,服务器负载压力不均衡,所以有可能分配的不合理。
- 轮询策略。请求均匀分配,如果服务器有性能差异,则无法实现性能好的服务器能够多承担一部分。
- 权重轮询策略。权值需要静态配置,无法自动调节,不适合对长连接和命中率有要求的场景。
- Hash取模策略。不稳定,如果列表中某台服务器宕机,则会导致路由算法产生变化,由此导致命中率的急剧下降。 一致性哈希策略。
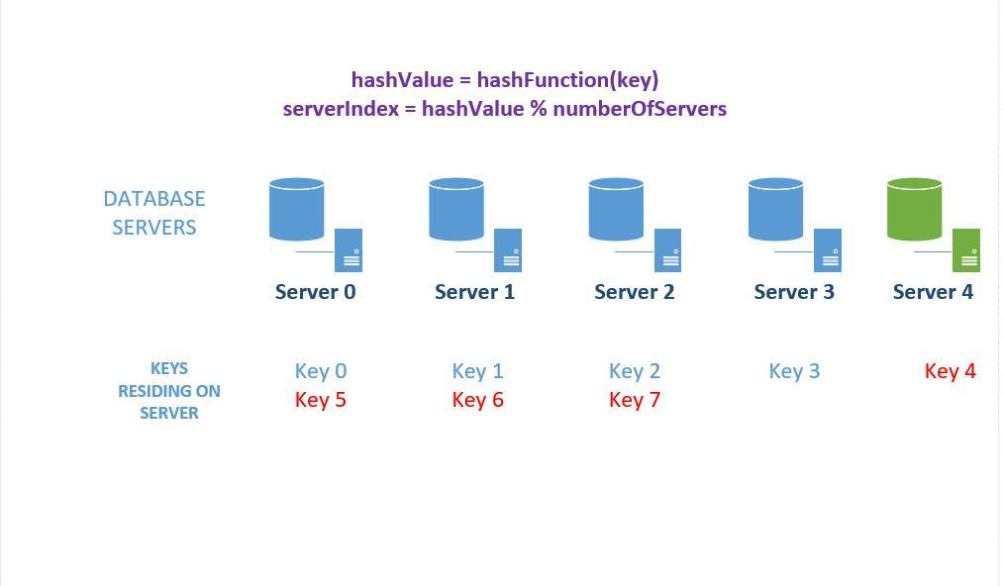
Hash取模策略
hash取模可以定义为 “ key % n = 目标cluster ”,key可以相当于 java 中的hashcode ,n 则为当前所有集群机器的数量。 但是它的缺点很明显,假如使用hash取模策略,若增加台cluster,(图片来自参考资料)
减少台机器
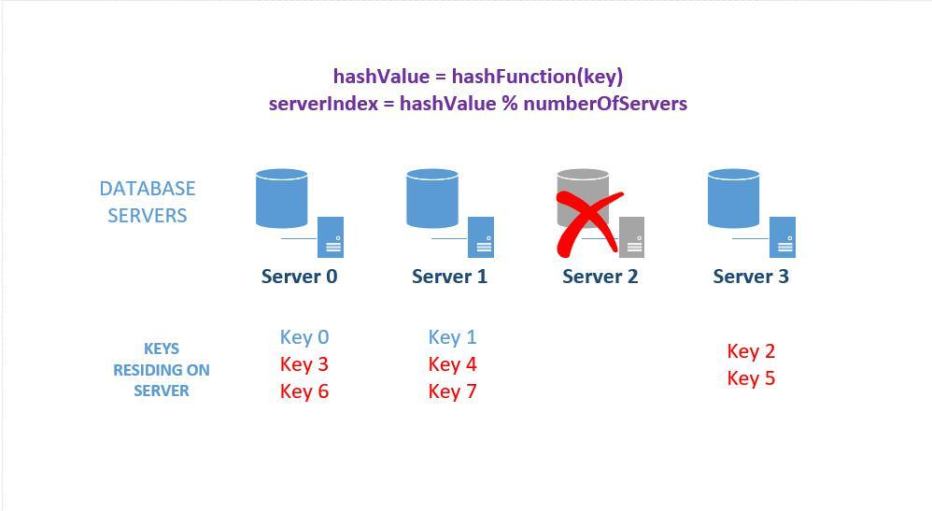
可以看到增加台机器,会导致key 重新映射,那么迁移工作将是巨大的,而减少一台也是同样的道理,最重要的原因是该策略是依赖机器的数量进行分配目标机器。
分布式一致性hash算法
直接上图(来源见参考资料)
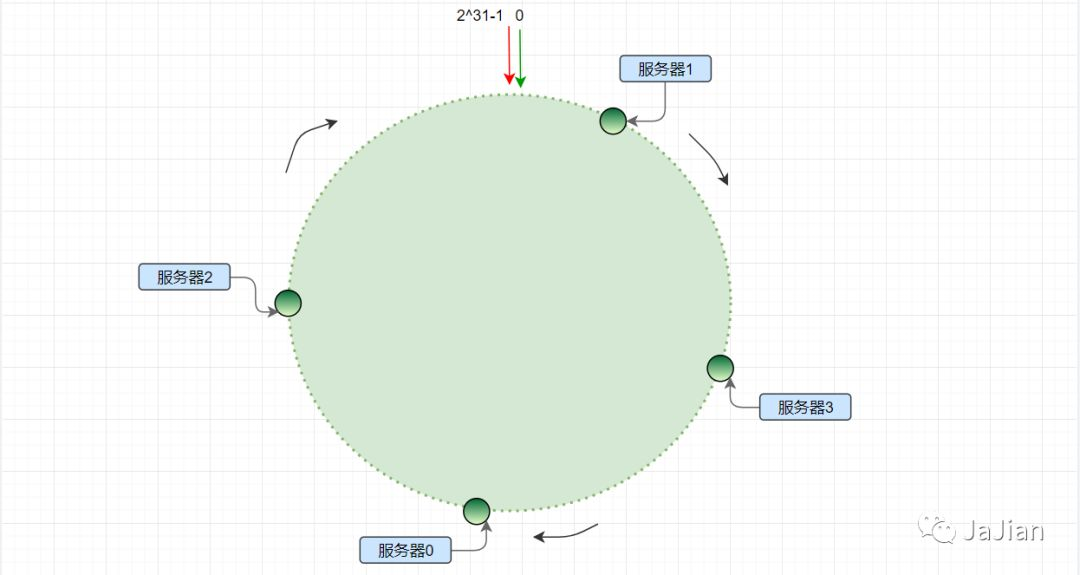
上面是hash环,cluster 分布在hash环上,请求经过hash 等到的key沿着顺时针,第一个到达的节点就是目标cluster .
扩展性和容错性
假如增加/减少了一台机器,对其他的cluster并没有什么影响,而某台cluster发生故障后,恢复的时候只需要将故障节点的keys 放在沿着hash环下一台节点就可以了。
虚拟节点
但是我们将节点分布在hash 环上的时候有可能分布不均,例如
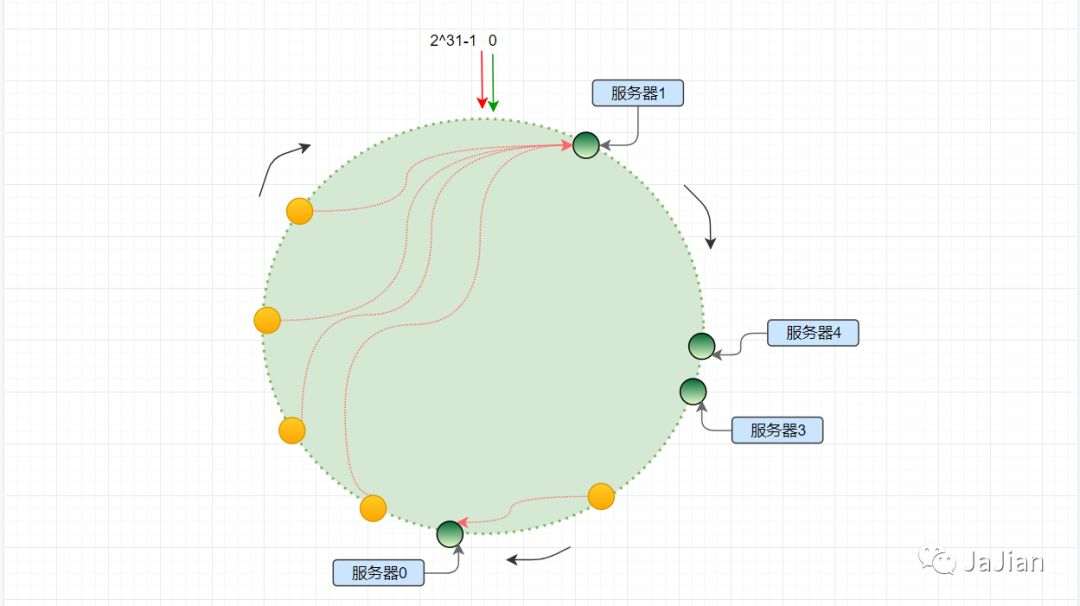
上图,服务器1接受的请求在平等条件下肯定比其他的多,我们可以通过增设虚拟节点的方式来解决这个问题,虚拟节点并不是真实的物理节点,是虚构出来的,这样可以解决节点在hash 环中不平衡的问题,同时也是根据权重不同可以分配多几个虚拟节点。
运用
- rocketmq 集群消费端 和 dubbo (RPC) 对服务提供者负载均衡的时候会使用
- MySQL 分库分表的实现也是可以使用一致性Hash 算法 (这个在后续的文章中会提到)
这里的dubbo中的一致性hash 算法的运用和 数据库的运用有点不同,为什么呢? dubbo 是 RPC ,某个节点down 或是增加了节点,并没有影响,而数据库就不同了,数据库存储的是数据,某个节点down 了数据就找不到了,后续文章再详细说明。
具体实现
我们看一下 dubbo 中关于hash 一致性算法的实现,,主要的实现是依靠 TreeMap 的 ceilingEntry 方法, 该方法的注解 :
The ceilingEntry(K key) method is used to return a key-value mapping associated with the least key greater than or equal to the given key, or null if there is no such key.
就是返回最相近的值,这和 一致性 hash 算法的key 绕着圈走到最近的节点思路一致。 dubbo 中的一致性hash实现在 ConsistentHashLoadBalance 类,我们直接看 doSelect 方法,其中 invokers 就是候选的节点,invocation 是调用者的封装,最后返回的 Invoker 自然就是目标 invoker .
1 public class ConsistentHashLoadBalance extends AbstractLoadBalance { 2 public static final String NAME = "consistenthash"; 3 4 /** 5 * Hash nodes name 6 */ 7 public static final String HASH_NODES = "hash.nodes"; 8 9 /** 10 * Hash arguments name 11 */ 12 public static final String HASH_ARGUMENTS = "hash.arguments"; 13 14 private final ConcurrentMap<String, ConsistentHashSelector<?>> selectors = new ConcurrentHashMap<String, ConsistentHashSelector<?>>(); 15 16 @SuppressWarnings("unchecked") 17 @Override 18 protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) { 19 String methodName = RpcUtils.getMethodName(invocation); 20 String key = invokers.get(0).getUrl().getServiceKey() + "." + methodName; 21 // using the hashcode of list to compute the hash only pay attention to the elements in the list 22 int invokersHashCode = invokers.hashCode(); 23 ConsistentHashSelector<T> selector = (ConsistentHashSelector<T>) selectors.get(key); 24 if (selector == null || selector.identityHashCode != invokersHashCode) { 25 selectors.put(key, new ConsistentHashSelector<T>(invokers, methodName, invokersHashCode)); 26 selector = (ConsistentHashSelector<T>) selectors.get(key); 27 } 28 //该给 ConsistentHashSelector 方法 29 return selector.select(invocation); 30 } 31 32 private static final class ConsistentHashSelector<T> { 33 34 private final TreeMap<Long, Invoker<T>> virtualInvokers; 35 36 private final int replicaNumber; 37 38 private final int identityHashCode; 39 40 private final int[] argumentIndex; 41 42 ConsistentHashSelector(List<Invoker<T>> invokers, String methodName, int identityHashCode) { 43 this.virtualInvokers = new TreeMap<Long, Invoker<T>>(); 44 this.identityHashCode = identityHashCode; 45 URL url = invokers.get(0).getUrl(); 46 this.replicaNumber = url.getMethodParameter(methodName, HASH_NODES, 160); 47 String[] index = COMMA_SPLIT_PATTERN.split(url.getMethodParameter(methodName, HASH_ARGUMENTS, "0")); 48 argumentIndex = new int[index.length]; 49 for (int i = 0; i < index.length; i++) { 50 argumentIndex[i] = Integer.parseInt(index[i]); 51 } 52 // replicaNumber就是复制的节点,默认是 160 ,假如invokers 的数量是 5 ,那么总的节点数就是 5*160 53 for (Invoker<T> invoker : invokers) { 54 String address = invoker.getUrl().getAddress(); 55 for (int i = 0; i < replicaNumber / 4; i++) { 56 byte[] digest = md5(address + i); 57 for (int h = 0; h < 4; h++) { 58 long m = hash(digest, h); 59 // virtualInvokers 是个 TreeMap 60 virtualInvokers.put(m, invoker); 61 } 62 } 63 } 64 } 65 66 public Invoker<T> select(Invocation invocation) { 67 String key = toKey(invocation.getArguments()); 68 byte[] digest = md5(key); 69 return selectForKey(hash(digest, 0)); 70 } 71 72 private String toKey(Object[] args) { 73 StringBuilder buf = new StringBuilder(); 74 for (int i : argumentIndex) { 75 if (i >= 0 && i < args.length) { 76 buf.append(args[i]); 77 } 78 } 79 return buf.toString(); 80 } 81 82 private Invoker<T> selectForKey(long hash) { 83 //看这里!!调用 ceilingEntry 方法 84 Map.Entry<Long, Invoker<T>> entry = virtualInvokers.ceilingEntry(hash); 85 if (entry == null) { 86 entry = virtualInvokers.firstEntry(); 87 } 88 return entry.getValue(); 89 } 90 91 private long hash(byte[] digest, int number) { 92 return (((long) (digest[3 + number * 4] & 0xFF) << 24) 93 | ((long) (digest[2 + number * 4] & 0xFF) << 16) 94 | ((long) (digest[1 + number * 4] & 0xFF) << 8) 95 | (digest[number * 4] & 0xFF)) 96 & 0xFFFFFFFFL; 97 } 98 99 private byte[] md5(String value) { 100 MessageDigest md5; 101 try { 102 md5 = MessageDigest.getInstance("MD5"); 103 } catch (NoSuchAlgorithmException e) { 104 throw new IllegalStateException(e.getMessage(), e); 105 } 106 md5.reset(); 107 byte[] bytes = value.getBytes(StandardCharsets.UTF_8); 108 md5.update(bytes); 109 return md5.digest(); 110 } 111 112 } 113 114 }
上面使用了hash 算法 ,在和 https://github.com/RJ/ketama 该地址下看到的有点相似,这里我们只需要知道hash 的作用是使得使值均匀分布。
总结
通过本文了解了分布式哈希一致性相对与其他的负载均衡策略的优势。
参考资料
- https://www.acodersjourney.com/system-design-interview-consistent-hashing/
- https://www.cnblogs.com/jajian/p/10896624.html