es核心概念
索引(index)=数据库
文档(document)=每条数据
类型(type)=表结构
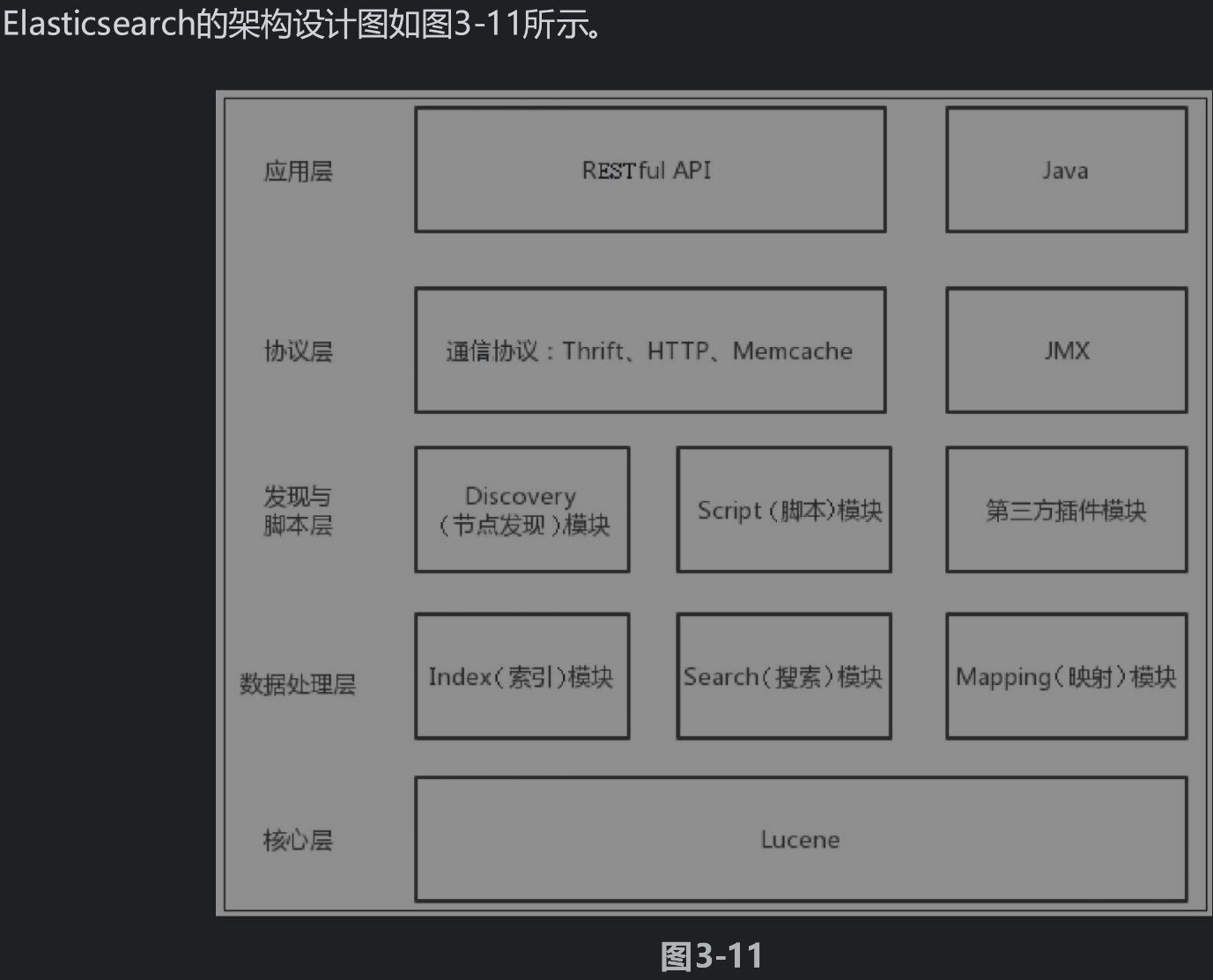
Elasticsearch的核心概念有Node、Cluster、Shards、Replicas、Index、Type、Document、Settings、Mapping和Analyzer
1.node: 节点
2.cluster: 集群
Elasticsearch的集群是由具有相同cluster.name (默认值为elasticsearch)的一个或多个Elasticsearch节点组成的,各个节点协同工作,共享数据。同一个集群内节点的名字不能重复,但集群名称一定要相同。
节点的状态有Green、Yellow和Red三种
3.shards: 分片
在Elasticsearch中,默认为一个索引创建5个主分片,并分别为每个主分片创建一个副本。
4.replics: 副本
指的是对主分片的备份,这种备份是精确复制模式。每个主分片可以有零个或多个副本,主分片和备份分片都可以对外提供数据查询服务。当构建索引进行写入操作时,首先在主分片上完成数据的索引,然后数据会从主分片分发到备份分片上进行索引。
5.index:索引
在Elasticsearch中,索引由一个和多个分片组成。在使用索引时,需要通过索引名称在集群内进行唯一标识。
6.type: 类别
类别指的是索引内部的逻辑分区,通过Type的名字在索引内进行唯一标识。在查询时如果没有该值,则表示需要在整个索引中查询。
7.document: 文档
索引中的每一条数据叫作一个文档,与关系数据库的使用方法类似,一条文档数据通过_id在Type内进行唯一标识
8.settings:
Settings是对集群中索引的定义信息,比如一个索引默认的分片数、副本数等
9.mapping:
Mapping表示中保存了定义索引中字段(Field)的存储类型、分词方式、是否存储等信息,有点类似于关系数据库(如MySQL)中的表结构信息。
在Elasticsearch中,Mapping是可以动态识别的。如果没有特殊需求,则不需要手动创建Mapping,因为Elasticsearch会根据数据格式自动识别它的类型。当需要对某些字段添加特殊属性时,如定义使用其他分词器、是否分词、是否存储等,就需要手动设置Mapping了。一个索引的Mapping一旦创建,若已经存储了数据,就不可修改了。
10.analyzer:
Analyzer表示的是字段分词方式的定义。一个Analyzer通常由一个Tokenizer和零到多个Filter组成。在Elasticsearch中,默认的标准Analyzer包含一个标准的Tokenizer和三个Filter,即Standard Token Filter、Lower Case Token Filter和Stop Token Filter。
当我们向Elasticsearch写入数据时,Elasticsearch根据文档标识符ID将文档分配到多个分片上。当查询数据时,Elasticsearch会查询所有的分片并汇总结果。对用户而言,这个过程是透明的,用户并不知道数据到底存在哪个分片上。
数据写入过程
- 分段存储
索引数据在磁盘上的是以分段形式存储的。
索引文件被拆分为多个子文件,其中每个子文件就叫作段,每个段都是一个倒排索引的小单元。
删除数据时,由于分段不可修改的特性,Elasticsearch不会把文档从旧的段中移除,因而是新增一个.del文件,.del文件中会记录这些被删除文档的段信息。被标记删除的文档仍然可以被查询匹配到,但它会在最终结果被返回前通过.del文件将其从结果集中移除。
当更新数据时,由于分段不可修改的特性,Elasticsearch无法通过修改旧的段来反映文档的更新,于是,更新操作变成了两个操作的结合,即先删除、后新增。Elasticsearch会将旧的文档从.del文件中标记删除,然后将文档的新版本索引到一个新的段中。在查询数据时,两个版本的文档都会被一个查询匹配到,但被删除的旧版本文档在结果集返回前就会被移除。
倘若频繁更新数据,则每次更新都是新增新的数据到新分段,并标记旧的分段中的数据,存储空间的浪费会更多。
每当有新的数据写入时,就将其先写入JVM的内存中。在内存和磁盘之间是文件系统缓存,文件缓存空间使用的是操作系统的空间。当达到默认的时间或者内存的数据达到一定量时,会触发一次刷新(Refresh)操作。刷新操作将内存中的数据生成到一个新的分段上并缓存到文件缓存系统,稍后再被刷新到磁盘中并生成提交点。
需要指出的是,由于新的数据会继续写入内存,而内存中的数据并不是以段的形式存储的,因此不能提供检索功能。只有当数据经由内存刷新到文件缓存系统,并生成新的段后,新的段才能供搜索使用,而不需要等到被刷新到磁盘才可以搜索。
在Elasticsearch中,写入和打开一个新段的过程叫作刷新。在默认情况下,每个分片会每秒自动刷新一次。这就是Elasticsearch能做到近实时搜索的原因,因为文档的变化并不是立即对搜索可见的,但会在一秒之内变为可见。
客户端
- 获取文档索引的词向量
词向量,在Elasticsearch中的英文名称为“Term Vectors”。那么什么是词向量呢?我们可以通俗地理解为:词向量是关于词的一些统计信息的统称。
文档处理过程
首先需要明确一点,写入磁盘的倒排索引是不可变的。Elasticsearch为什么要这样做,主要是基于以下几个考量:
(1)读写操作轻量级,不需要锁。如果Elasticsearch从来不需要更新一个索引,则就不必担心多个程序同时尝试修改索引的情况。
(2)一旦索引被读入文件系统的内存,它就会一直在那儿,因为不会改变。
此外,当文件系统内存有足够大的空间时,大部分的索引读写操作是可以直接访问内存,而不是磁盘就能实现的,显然这有助于提升Elasticsearch的性能。
Elasticsearch不是重写整个倒排索引,而是增加额外的索引反映最近的变化。每个倒排索引都可以按顺序查询,从最“老旧”的索引开始查询,最后把结果聚合起来。
当一个文档被删除时,它实际上只是在.del文件中被标记为删除。在进行文档查询时,被删除的文档依然可以被匹配查询,但是在最终返回之前会从结果中删除。当一个文档被更新时,旧版本的文档会被标记为删除,新版本的文档在新的段中被索引。当对文档进行查询时,该文档的不同版本都会匹配一个查询请求,但是较旧的版本会从结果中被删除。被删除的文件越积累越多,每个段消耗的如文件句柄、内存、CPU等资源越来越大。如果每次搜索请求都需要依次检查每个段,则段越多,查询就越慢。这些势必会影响Elasticsearch的性能,那么Elasticsearch是如何处理的呢?Elasticsearch引入了段合并段。
文档处理解析
一个索引一般由多个分片构成,当用户执行添加、删除、修改文档操作时,Elasticsearch需要决定把这个文档存储在哪个分片上,这个过程就称为数据路由
- 主分片的个数在索引建立之后不能修改。因为修改索引主分片数目会直接导致路由规则出现严重问题,部分数据将无法被检索。
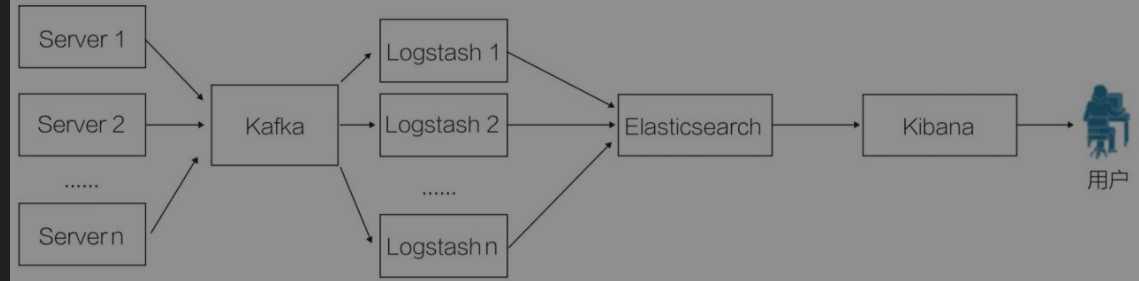
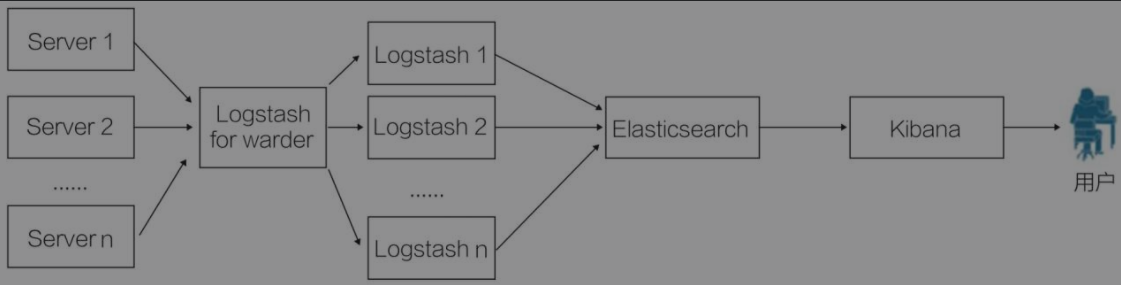
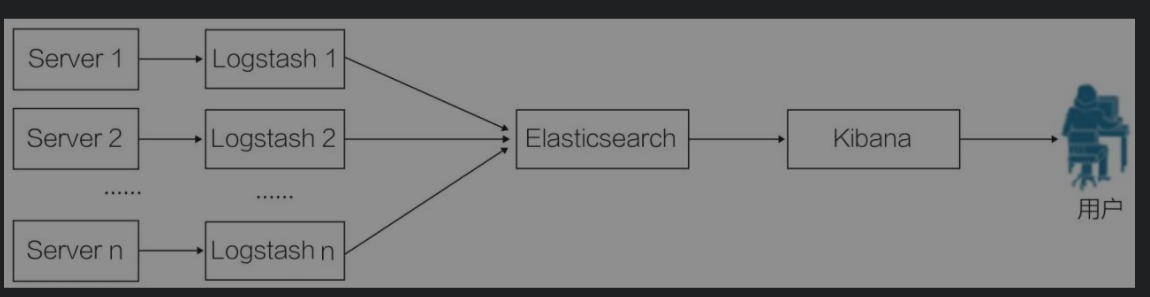
elk
小型elk
大型elk