个人觉得HashMap一开始的数据结构是这样的:
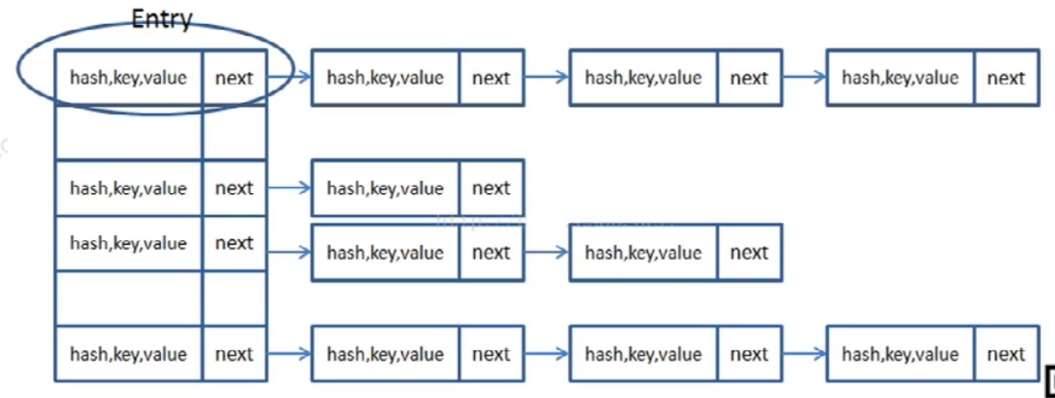
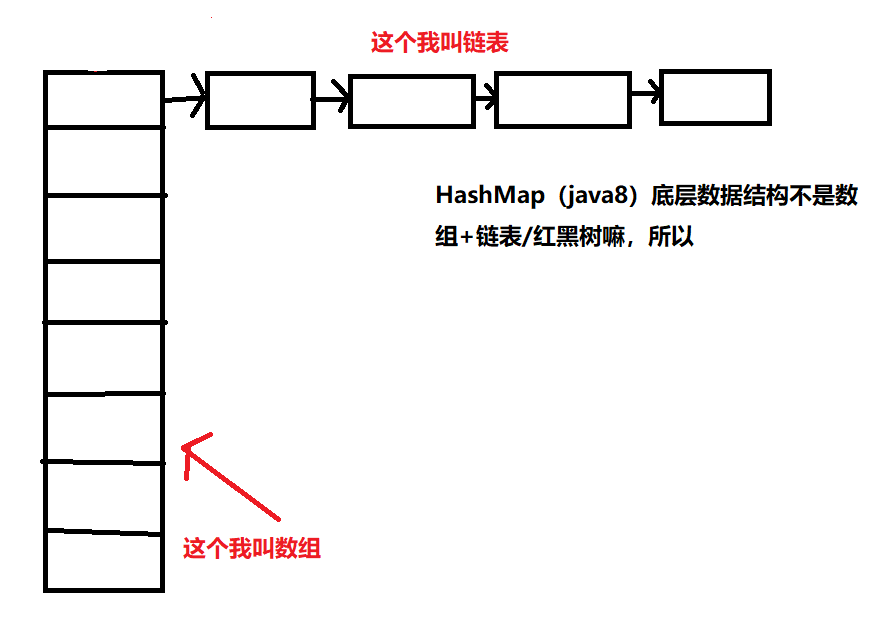
我怕我的描述有误,所以先在这把我要描述的数据结构先画一下,然后再看流程图和代码解析
每一个存储的单元:

是在Java定义的Node (我叫它节点)
Node在Java的代码表现为:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
//还有其它一些函数,此次省略
}
所以上图是这样画的
HashMap的几个成员变量:
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 16 是HashMap默认大小(在不指定大小创建的时候)
static final int MAXIMUM_CAPACITY = 1 << 30; // 2^30 是HashMap得到最大长度size
static final float DEFAULT_LOAD_FACTOR = 0.75f; //负载因子,和阈值有关, 阈值 = size * 负载因子
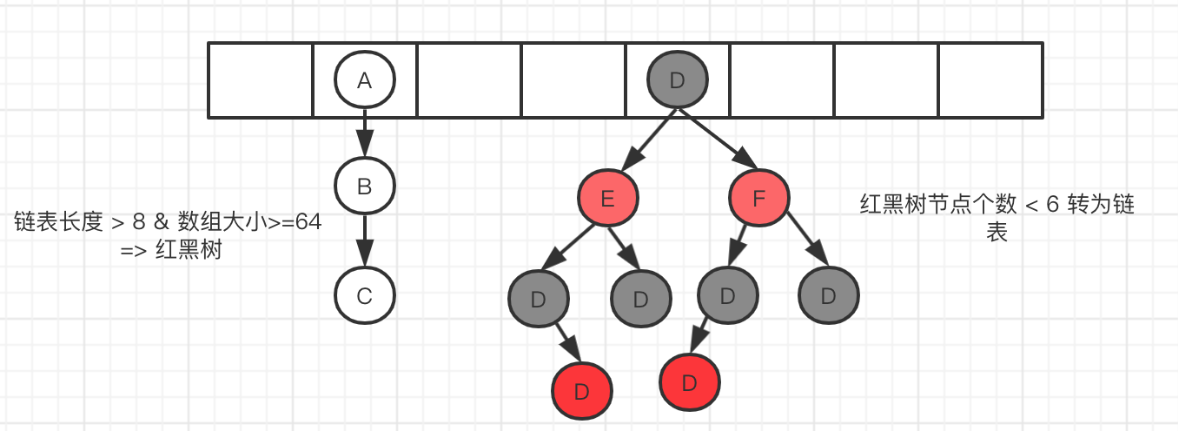
static final int TREEIFY_THRESHOLD = 8; //用于判断链表转红黑树的,链表长度是否大于8
static final int UNTREEIFY_THRESHOLD = 6; //用于红黑树转链表的,红黑树大小是否小于6
static final int MIN_TREEIFY_CAPACITY = 64; //用于判断链表转红黑树的,size是否大于64
红黑树的结构:
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // 父节点
TreeNode<K,V> left; // 左边节点
TreeNode<K,V> right; // 右边节点
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red; // 颜色,root 节点为黑色
}
想看数据结构的实际插入是怎样的,可以看这个:
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html (不会使用的话,看这个视频:https://www.bilibili.com/video/BV1yT4y1w7FS)
链表转红黑树的方法:treeifyBin(),相关函数的说明
https://blog.csdn.net/weixin_42340670/article/details/80517036
下面就开始看一下put的流程图吧:
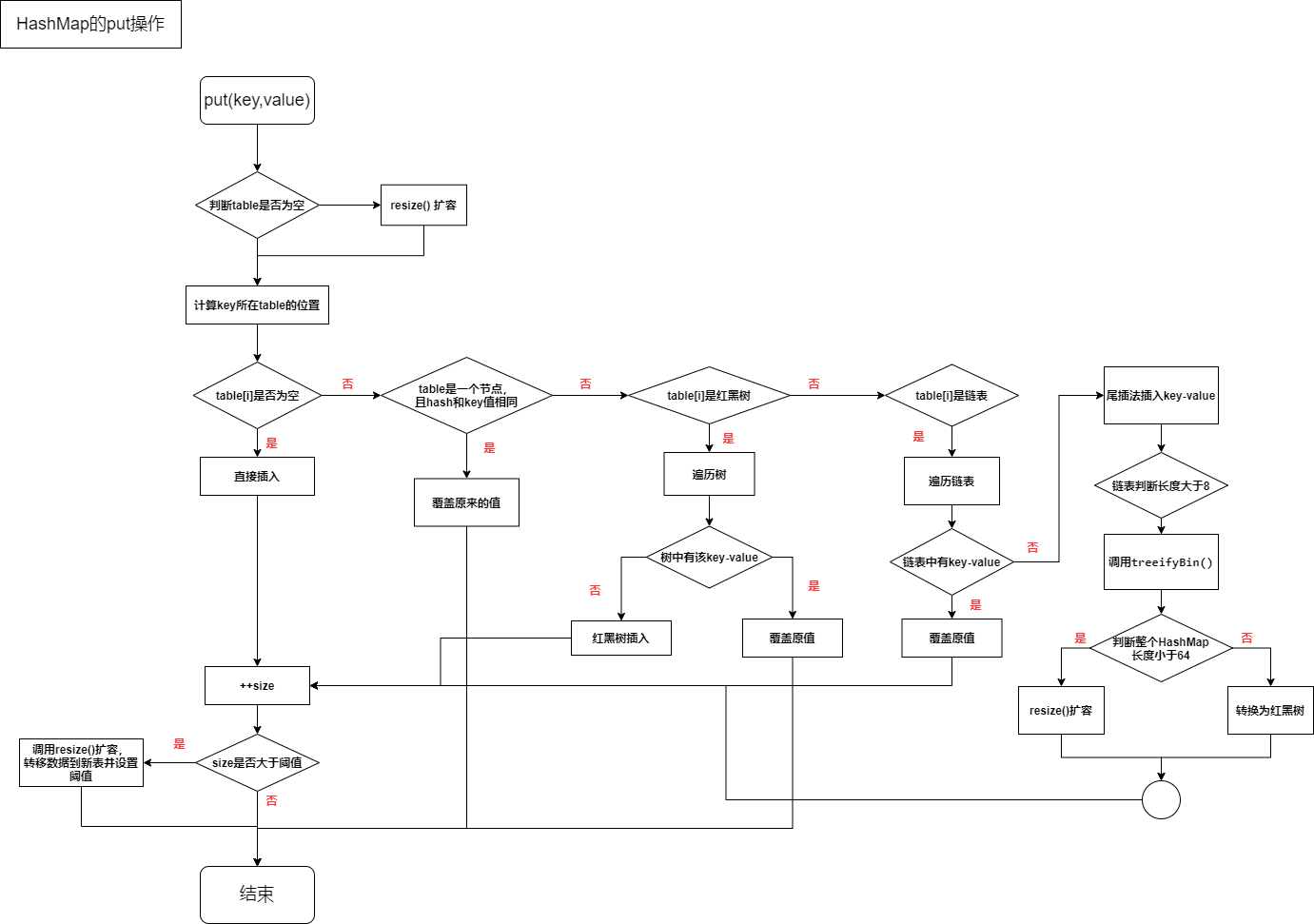
代码解析
put() 方法因为直接调用 putVal() 方法,所以我们看 putVal() 方法是怎么写的就好了

final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}

从图片中我们可以分为7个部分:
- 当HashMap第一次put时,且初始化的时候使用系统默认的参数,这个时候,HashMap才开始分配大小(扩容函数resize())
- 当对应的hash位置为null时,执行插入(数据用newNode()方法生成一个Node来存放到数组中)
- 当对应hash位置的key和我们本次put的key是一样(equals也相同)的时候,再用第6部分(第六个方框)把原来的数据替换掉
- TreeNode是红黑树的数据结构,所以当Hash位置对应的数据结构是TreeNode的时候,调用红黑树的插入方法putTreeVal(),至于执不执行第6部分(第六个方框),要看对应流程图描述
- 循环遍历链表中的数据,第一个if()中的表达式:(e = p.next) == null 可以分为: e = p.next ; e==null; 上面这个if主要功能是插入新的数据和判断是否在插入数据以后需要把链表转为红黑树;下面的这个if是为了当key的hash数据一样时,用第6部分(第六个方框)把原来的数据替换掉
- 覆盖原来的数据 ,e 就是这个原来的数据
- HashMap的size增1,并且判断,当size大于阈值的时候扩容(resize())
优质博文推荐
关于HashMap,volatile,synchroinzed面试题的三篇博文
https://blog.csdn.net/zhengwangzw/category_9827338.html