写在前面:
感受Hash与k进制的异曲同工之妙
优雅的暴力算法
本人目前高三,写博不太方便
非原创内容标明出处
luuuuuuuuuna~
话说点了NO之后那颗小心心就碎了
|
目录
|
简介
-
Hash函数

|
A hash function is any function that can be used to map data of arbitrary size to data of a fixed size The values returned by a hash function are called hash values, hash codes, digests, or simply hashes Hash functions are often used in combination with a hash table, a common data structure used in computer software for rapid data lookup Hash functions accelerate table or database lookup by detecting duplicated records in a large file They are also useful in cryptography. A cryptographic hash function allows one to easily verify that some input data maps to a given hash value, but if the input data is unknown, it is deliberately difficult to reconstruct it (or any equivalent alternatives) by knowing the stored hash value ——Wikipedia |
|
译: Hash函数是可以用来将任意大小的数据映射到固定大小的数据的任何函数 Hash函数返回的值称为Hash值 Hash函数通常与Hash表结合使用,Hash表是计算机软件中通用的快速数据查找的数据结构 Hash函数通过检测大文件中的重复记录来加速表或数据库查找 它们在密码学中也很有用。加密Hash函数能轻松验证某些输入数据映射到给定的Hash值,但输入数据未知,则通过知道存储的散列值故意难以重新获得初始输入值(或任何等效的输入值) |
Hash表
|
In computing, a hash table (hash map) is a data structure that implements an associative array abstract data type, a structure that can map keys to values. A hash table uses a hash function to compute an index into an array of buckets or slots, from which the desired value can be found Ideally, the hash function will assign each key to a unique bucket, but most hash table designs employ an imperfect hash function, which might cause hash collisions where the hash function generates the same index for more than one key. Such collisions must be accommodated in some way In a well-dimensioned hash table, the average cost (number of instructions) for each lookup is independent of the number of elements stored in the table. Many hash table designs also allow arbitrary insertions and deletions of key-value pairs, at constant average cost per operation ——Wikipedia |
|
译: 在计算中,Hash表是实现关联数组抽象数据类型的数据结构,该结构可以将键映射到值。Hash表使用Hash函数将索引计算到桶或槽的数组中,从中可以找到所需的值 理想情况下,Hash函数会将每个键分配给一个唯一的容器,但大多数Hash表设计都使用了一个不完善的Hash函数,这可能会导致Hash函数在为多个键生成相同索引时发生Hash冲突。这种冲突必须以某种方式进行调节 在尺寸良好的Hash表中,每次查找的平均成本(指令数)与表中存储的元素数无关。许多Hash表设计也允许任意插入和删除键值对,每次操作的平均成本不变 |
-
Hash应用
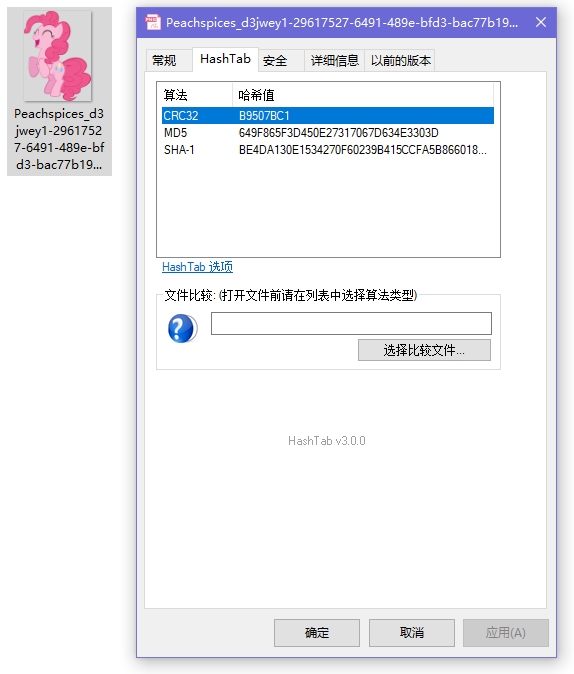
Windows自带Hash计算
也可以下载Hash计算器来计算
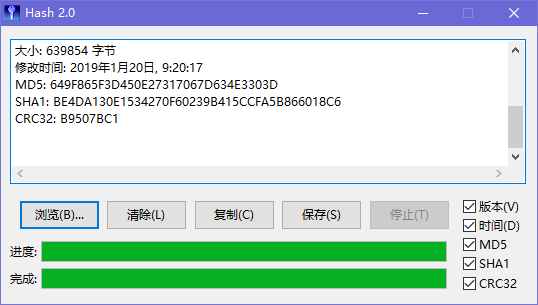
可以看到使用记事本打开后的原信息好多好多

但是得到的Hash值却只有那么少一点
value = hash(key)
实际中的Hash主要有两种应用:加密和压缩。在加密方面,Hash哈希是把一些不同长度的信息转化成杂乱的128位的编码,这些编码值叫做HASH值,最广泛应用的Hash算法有MD4、MD5、SHA1。在压缩方面,Hash哈希是指把一个大范围映射到一个小范围,往往是为了节省空间,使得数据容易保存
——https://www.cnblogs.com/coder2012/p/3954736.html
-
其他
看到的一个有趣的东西
虑对结果加密:
阿呆:我心中想一个数,假设为A,然后A在乘以一个数B,得到结果C。A是我的密钥,我把结果C告诉你。你来猜A是奇数还是偶数,猜中了,算你赢
小星:这不行,如果你告诉我C是12,我猜A是奇数,你可以说A是4,B是3。我猜A是偶数,你可以说A是3,B是4。要不你告诉我C是多少的时候,也告诉我B是多少
阿呆:那这不行,告诉你C和B,不等于告诉你A是多少了,还猜个p,不行得换个方式

不可逆加密:
阿呆:小星,你看这样可以不,我想一个A,经过下面的过程:
1.A+123=B
2.B^2=C
3.取C中第2~4位数,组成一个3位数D
4.D/12的结果求余数,得到E
阿呆:我把E和上述计算方式都告诉你,你猜A是奇数还是偶数,然后我告诉你A是多少,你可以按上述的计算过程来验证我是否有说谎
小星:嗯,我想想,假如阿呆你想的A为5,那么:
5+123=128
128^2=16384
D=638
E=638 mod 12
小星:咦,厉害了,一个A值对应一个唯一的E值,根据E还推算不出来A。整蛮好,这个算公平,谁撒谎都能被识别出来
小星:阿呆,你出题吧 ……

这种丢掉一部分信息的加密方式称为“单向加密”,也叫Hash算法
——http://www.sohu.com/a/232586831_100078137
原理
value = hash(key)
通过同一个hash函数,处理数字量大的key,得到数字量小易处理的value,从而能高效进行各种操作,如查重、查存在等
实现
代码先摸了,毕竟高三时间紧
-
Hash函数
首先,写Hash函数的原则:大的映射到小的
大体可以分为三种基本方法:加法、乘法和移位
加法哈希是通过遍历数据中的元素然后每次对某个初始值进行加操作,其中加的值和这个数据的一个元素相关
hash += int(key.at(i))
乘法哈希是通过遍历数据中的元素然后每次对初始值进行乘法操作,其中乘的值无需和数据有关系
hash = (hash * 16777619)^int(key.at(i))
移位哈希是通过遍历数据中的元素然后每次对初始值进行移位操作
hash = (hash << 4)^(hash >> 28)^int(key.at(i))
三种方法经常混着用
——https://www.cnblogs.com/coder2012/p/3954736.html
关于模数为什么要选择素数
对于特殊数据合数会发生大量碰撞,而质数可以避免这种情况
——https://www.cnblogs.com/cryingrain/p/11144225.html
-
冲突解决
Hash函数将大数据映射到小数据上,会导致不同的key映射到同一个value,导致冲突
目前的冲突解决有两种思路,四种方法
从函数(生成)上解决:
再Hash
从容器(地址)上解决:
开放地址
链地址
建立公共溢出区
类比
类比k进制:
例①
当2进制转化为10进制:
01011001 → 89
2个不同字符,长度为8的信息,使用一种算法,转化成10个不同字符,长度为2的信息
从意义上看,“01011001”和“89”表示同一个东西
例②
当2进制转化为16进制:
10110110 → B6
2个不同字符,长度为8的信息,使用一种算法,转化成16个不同字符,长度为2的信息
从意义上看,“10110110”和“B6”表示同一个东西
上面两个例子能帮助感知什么是“映射”,同一意义经映射后能表达为不同信息,而不同信息经映射后能成为同一意义
但是,相比于hash,这种映射是不冲突的,因为能用来表示信息的字符数量不同(如12345...ABCDE...)
当能用来表示信息的字符数量映射前映射后一样,甚至映射后能用的字符数量比映射前的还要少时,将长信息映射成短信息,虽然方便了操作,但会造成信息的冲突
这就是hash了