用途:
- 存储少量的数据,+ *int 切片, 其他操作方法
- 切片还是对其进行任何操作,获取的内容全部是strl类型
- 存储数据单一
格式: 在python中用引号引起来的就是字符串
'今天吃了没?'
1. 索引切片
索引顺序如下图:
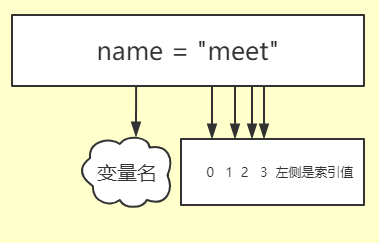
name = "meet,alex,wusir,wangsir,Eva_j"
01234567 (索引) #从左向右数数
-4-3-2-1 (索引) #从右向左数数
格式:
区间[起始位置:终止位置]
原则:
顾头不顾腚
例题:
name = 'hello'
name1 = name[:3]
print(name1) #输出结果:hel 根据顾头不顾尾原则后面的l被丢弃
切片字符的拼接:
name = "meet,alex,wusir,wangsir,Eva_j"
a = name[0]
b = name[1]
print(a + b)
# 输出结果
# me
2. 步长:
格式:
默认是1 [起始位置:终止位置:步长]
步长就是你走路迈的步子
例题:
name = "meet,alex,wusir,wangsir,Eva_j"
print(name[0:10:2])
# 输出结果
# me,lx
# 个人见解
# 这里的2为步长,从0(m)开始到10(,)结束,m一定要取,然后开始数0(m)取走、1(e)、2(e)取走、1(t)、2(,)取走、1(a)、2(l)取走、1(e)、2(x)取走、1(,)
识记点:
- 切片如果终止位置超出了不报错
print(name[0:100])不报错 - 索引取值的时候超出了索引的范围会报错
print(name[100])报错原因:取不到100索引的值 - 字符串,列表,元组 -- 都是有索引(下标)
- 索引是准确的定位某个元素
- 从左向右 0,1,2,3
- 从右向左 -1,-2,-3,-4
- 支持索引的都支持切片 [索引]
3. 反转
格式:
区间[起始位置:终止位置:-1]
例题:
name = "meet,alex,wusir,wangsir,Eva_j"
print(name[::-1])
输出结果
j_avE,risgnaw,risuw,xela,teem
字符串操作方法:
识记:
字符串的类型以 . 来调用 才叫做字符串方法
upper (全部大写)
例题:
name = "meet"
name1 = name.upper()
print(name1)
# 输出结果
# MEET
lower (全部小写)
例题:
name = "MEET"
name1 = name.lower()
print(name1)
# 输出结果
# meet
练习题: 验证码
yzm = "o98K"
input_yzm = input("请输入验证码(o98K):")
if yzm.upper() == input_yzm.upper():
print("正确")
else:
print("错误")
id (获取内存地址)
例题:
name = 'alex'
print(id(name))
# 输出结果
# 4543793504
startswith (以什么开头)
例题:
name = "alex"
print(name.startswith('a'))
# 判断name变量是以a开的头的
endswith (以什么结尾)
例题:
name = "zhuxiaodidi"
print(name.endswith("i"))
# 判断name就是以i结尾
count (统计)
例题:
# name = "zhudidi"
# print(name.count("zhu"))
# 查询某个内容出现的次数
replace (替换) *********
格式:
str.replace('n','s') 前面是要被替换的内容 后面是新的
例题:
# name = "alexnbnsnsn"
# name1 = name.replace('n','s') # 替换 前面是老的,后面是新的
# name1 = name.replace('n','s',2) # 替换 前面是老的,后面是新的 2是替换的次数
# print(name1)
strip (除去头尾两边的空格/换行符) *********
例题:
# name = " alex "
# name1 = name.strip() # 可以写想要去掉的内容
# print(name1)
# if name == "alex":
# print(666)
# name = " alex "
# print(name.strip())
split (分割) *********
例题:
name = 'alex,wusir'
print(name.split(","))
# ['alex', 'wusir']
# 默认是以空格分割 ,也可以自己制定分割
# 分割后返回的内容是一个列表
分割后返回的内容是一个列表
1. 无参数的情况
a="my name is john"
b="my
name
isjohn"
c="my name isjohn"
a=a.split()
b=b.split()
c=c.split()
print(a)
print(b)
print(c)
输出:
['my', 'name', 'is', 'john']
['my', 'name', 'is', 'john']
['my', 'name', 'is', 'john']
---------------------
2. 有参数的情况
d="my,name,is,john"
e="my;name;is;john"
f="my-name-is-john"
d=d.split(",")
e=e.split(";")
f=f.split("-")
print(d)
print(e)
print(f)
输出:
['my', 'name', 'is', 'john']
['my', 'name', 'is', 'john']
['my', 'name', 'is', 'john']
---------------------
3. 当具有两个参数的情况
a="My,name,is,john,and,I,am,a,student"
b1=a.split(",",1)
b2=a.split(",",2)
b8=a.split(",",8)
b9=a.split(",",9)
print(b1)
print(b2)
print(b8)
print(b9)
输出:
['My', 'name,is,john,and,I,am,a,student']
['My', 'name', 'is,john,and,I,am,a,student']
['My', 'name', 'is', 'john', 'and', 'I', 'am', 'a', 'student']
['My', 'name', 'is', 'john', 'and', 'I', 'am', 'a', 'student']
---------------------
format (第三种字符串格式化)
三种方法:
- 按照位置顺序去填充的
- 按照索引位置去填充
- 关键字填充(指名道姓 填充)
例题:
# name = "alex{}wusir{}"
# name1 = name.format('结婚了',"要结婚了") # 按照位置顺序去填充的
# name = "alex{1}wusir{0}"
# name1 = name.format('结婚了',"要结婚了") # 按照索引位置去填充
# name = "alex{a}wusir{b}"
# name1 = name.format(a="结婚了",b="马上结婚") # 指名道姓 填充
# print(name1)
isdigit (判断是不是阿拉伯数字)
例题:
# name = "②"
# print(name.isdigit())
isdecimal (判断是不是十进制 -- 用它来判断是不是数字)
例题:
# name = "666"
# print(name.isdecimal())
isalpha (判断的是中文和字母)
例题:
# name = "alexs你好"
# print(name.isalpha())
isalnum (判断的是不是字母,中文和阿拉伯数字)
例题:
# name = "alex666"
# print(name.isalnum())