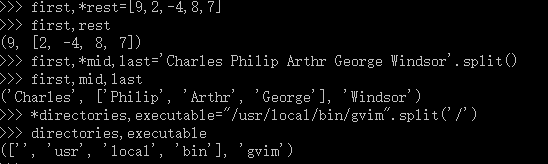
1. 元组
元组是个有序的序列,其中包含0个或多个对象引用。元组支持与字符串一样的分片与步距的语法,这使得从元组中提取数据项比较容易。元组也是固定的,不能替换或删除其中包含的任意数据项。如果需要修改有序序列,我们应该使用类别而非元组。如果要对元组进行修改,可以使用list()转换函数将其转换为列表,之后在产生的列表之上进行适当修改。
tuple数据类型可以作为一个函数进行调用,tuple()---不指定参数时将返回一个空元组,使用tuple作为参数时将返回该参数的浅拷贝,对其他任意参数,将尝试把给定的对象转换为tuple类型。该函数最多只能接受一个参数。元组也可以使用tuple()函数创建,空元组是使用空圆括号()创建的,包含一个或多个项的元组则可以使用逗号分隔进行创建。
元组只提供了两种方法:t.count(x),返回对象x在元组中出现的次数;t.index(x),返回对象在元组t中出现的最左边位置。
元组可以使用操作符+(连接)、*(赋值)与 [](分片),要可以使用in 与not in 来测试成员关系。
下面给出几个分片实例:

上面这些处理过程对字符串、列表以及人员其他序列类型都是一样的

要构成一个亿元组,逗号是必须的,这里red字符串地方我们必须同时使用逗号与圆括号。
1.1 命名的元组
命名的元组与普通元组一样,有相同的表现特征,其添加的功能就是可以根据名称引用元组中的项,就像根据索引位置一样,这一功能使我们可以创建数据项的聚集。
collections 模块提供了 namedtuple()函数,该函数用于创建自定义的元组数据类型,例如:

collections.namedtuple()的第一个参数是想要创建的自定义元组数据类型的名称,第二个参数是一个字符串,其中包含使用空格分割的名称,每个名称代表该元组数据类型的一项。该函数返回一个自定义的类(数据类型),用于创建命名的元组。因此,这一情况下,我们将sale与任何其他python类一样看待,并创建类型为sale的对象,如:

这里我们厂家了包含两个sale项的列表,也就是包含两个自定义元组。我们也可以使用索引位置来引用元组中的项----比如,第一个销售项的价格为sales[0][-1],但我们呢也可以使用名称进行引用,这样会更加清晰:

命名的元组提供的清晰与便利通常都是有用的,比如,下面另一个例子:

私有方法namedtuple._asdict()返回的是键-值对的映射,其中每个键都是元组元素的名称,值则是对应的值,我们使用映射拆分将映射转换为str.format()方法的键-值参数。
“{manufacturer} {model}”.format(**aircraft._asdict())
2. 列表
列表是包含0个或多个对象引用的有序序列,支持与字符串以及元组一样的分片与步距语法。与字符串以及元组不同的是,列表是可变的,因此,我们可以对列表中的项机芯删除或替换,插入、替换或删除列表中的分片。
list数据类型可以作为函数进行调用,list()--不带参数进行调用是将返回一个空列表;带一个list参数时,返回该参数的浅拷贝;对任意其他参数,则尝试将给定的对象转换为列表。该函数值接受一个参数的情况。列表也可以不使用list()函数创建,空列表可以使用空的方括号来创建,包含一个或多个项的列表则可以使用逗号分隔的数据项(包含在[]中)序列来创建。
列表提供的方法:

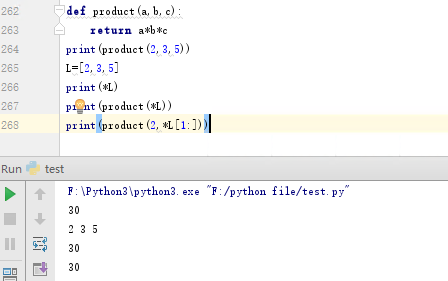
任意可迭代的(列表、元组等)数据类型都可以使用序列拆分操作符进行拆分,即:* 。用于赋值操作符左边的两个或多个变量时,其中的一个使用*进行引导,数据项将赋值给该变量,而所有剩下的数据项将赋值给带星号的变量,下面给出一些实例:
以这种方式使用序列拆分操作符时,表达式*rest以及类似的表达式称为带星号的表达式。
python还有一个相关的概念:带星号的参数。
对列表中的数据项,科研在其上进行迭代处理,使用的语法格式是 for item in L:。如果需要改列表中的数据项,那么使用的惯用方法如下:
for i in range(len(L)):
L[i] = process(L[i])
由于列表支持分片,因此在几种情况下,使用分片或某种列表方法可以完成同样的功能,如:给定列表woods=['Cedar','Yew','Fir'],我们可以以如下的两种方式扩展列表:
woods+=['Kauri','Larch'] | woods.extend(['Kauri','Larch'])
对上面两种方法,所得结果都是列表['Cedar','Yew','Fir','Kauri','Larch']。
使用list.append()方法,可以将单个数据项添加到列表尾部。使用list.insert()方法(或者赋值给一个长度为0的分片),可以将数据项插入到列表内的任何索引位置。比如,给定列表woods=['Cedar','Yew','Fir','Spruce'],我们可以在索引位置2处插入一个新的数据项(也就是作为该列表的第三项),下面两种方法均可以实现:
woods[2:2] = ['Pine'] | woods.insert(2,'Pine')
上面两种方法所得的结果都是列表['Cedar','Yew','Pine','Fir','Spruce'].
通过对特定索引位置处的对象进行赋值,可以对列表中的单个数据项进行替换,比如,woods[2]='Redwood'。通过将iterable赋值给分片,可以替换整个分片,比如,woods[1:3]=['Spruce','Sugi','Rimu'],并且分片月iterable并不必须是等长的。在所有这些情况下,都会删除分片的数据项,并插入iterable的数据项。如果iterable包含的项数比要替代的分片包含的项数少,那么这一操作会使类别变短;反之,则使得列表变成。如下例子:

对于复杂的列表,可以使用for...in 循环创建,如,假定需要生成给定时间范围内的闰年列表,可以使用如下语句:
leaps = []
for year in range(1900,1940):
if (year%4 == 0 and year %100 !=0) or (year % 400 ==0):
leaps.append(year)
两种表达式:
expression for item in iterable
expression for item in iterable if condition
3. 集合类型


3.1 集合

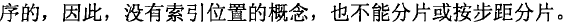

3.2 集合内涵

3.3 固定集合

4. 字典

