朴素贝叶斯和情感分类
分类问题在人类和机器智能中广泛应用:邮件分类、作业打分等。这篇博客介绍了朴素贝叶斯方法及其在文本分类方面的应用。其中文本分类的例子采用情感分析,就是从文本中进行情感抽取,并判断作者对特定事物的态度是积极还是消极,例如影评和书评的分析。情感分析中最简单的任务是二分类任务,文字可以为我们提供很多提示信息。比如下面的句子:
- + ...zany characters and richly applied staire, and some great plot twists
- - It was pathetic . The worst part about it wat the bosing scenes..
- + ...awesome caramel sauce and sweet toasty almonds.I love this place!
- - ...awful pizza and ridiculously overpriced...
这四句话是从影评和餐厅评价中选出的,其中great、richly、awesome、pathetic和awful等文字为我们提供了非常有用的信息。
垃圾邮件检测是分类问题的另一个重要商业应用,利用二分类器判断一个邮件是否为垃圾邮件。文法特征和其他特征对这个分类问题很有用,比如当看到邮件中有“online pharmaceutical”或者”WITHOUT ANY COST"或是"Dear Winner"等关键字时,你可能就会很怀疑这封邮件是垃圾邮件。
关于文本,我们想了解的还有使用语言这一基本信息。比如社交媒体上的文本采用了很多不同种类的语言,而不同的语言对应的处理流程可能是不同的。因此判断语言类别是大部分自然语言处理任务的第一步。相关任务包括:文本作者判定,作者性别、年龄以及母语等的判定。
文本分类最原始的任务是给文本主题标签或者属性种类。一篇论文是关于流行病学还是胚胎学是信息抽取的重要环节。事实上,朴素贝叶斯是在主题类别分类(subject category classification)任务的研究中发明出来的算法。
分类的目标是针对一个目标,提取一些有用的特征,然后将该目标归入离散类别集合的某一个类别。应用手写规则是文本分类的一种方法,自然语言处理中有一些领域采用手写规则为基础的分类器得到了非常好的效果。
然而,规则是非常脆弱的,不仅仅是因为应用环境和数据总是在改变,甚至对于一些领域来说人类无法提出效果很好的规则。自然语言处理的大部分分类任务都采用了有监督的机器学习来替代手写规则,这也是博客其余部分的主要内容。在有监督的机器学习中,数据集中每一个输入项都标注好了正确的输出结果,模型的目标就是学会如何将一个新输入项映射到正确的输出。
形式化地来讲,有监督的机器学习接受输入(x)和固定的输出集合(Y=y_{1},y_{2},....,y_{M})然后返回一个预测类别(yin Y)。在文本分类中,我们一般使用(c)而不是(y)来表示输出变量,(d)而不是(x)表示输入变量。在有监督的情况下,我们的训练集有(N)个文档,每个文档都手工标注了类别:((d_{1},c_{1}),......,(d_{N},c_{N}))。我们的目标是训练一个分类器,可以将一个新文档(d)映射到对应的类别(cin C)。一个概率分类器(probabilistic classifier)会告诉我们输入数据属于某一类的概率为多大。有很多机器学习算法都可以用来构建分类器,这篇博客我们主要介绍朴素贝叶斯算法,下一篇博客我们将介绍逻辑回归算法。他们代表了两类分类器。生成式分类器(generative classifiers)为给定的输入计算一个最可能产生该输入的类别,比如朴素贝叶斯分类器。判别式分类器(discriminative classifiers)会学习输入数据中的什么特征对判断类别最有效。在《On Discriminative vs. Generative classifiers: A comparison of logistic regression and naive Bayes》一文中,作者对比了两类分类器,实验结果表明训练集增加时,尽管两种算法都会表现更好,但效果好的表现形式却是不同的。从反复实验中观察到,训练集增加后,判别式方法会达到更低的渐进误差,而生成式方法会更快的达到渐进误差,但这个误差比判别方法的渐进误差大。
朴素贝叶斯分类器
这部分我们将介绍多项式的朴素贝叶斯分类器(multinomial naive beyes clasifier),之所以这么命名是因为该分类器在特征之间如何交互上做了最简单的假设。
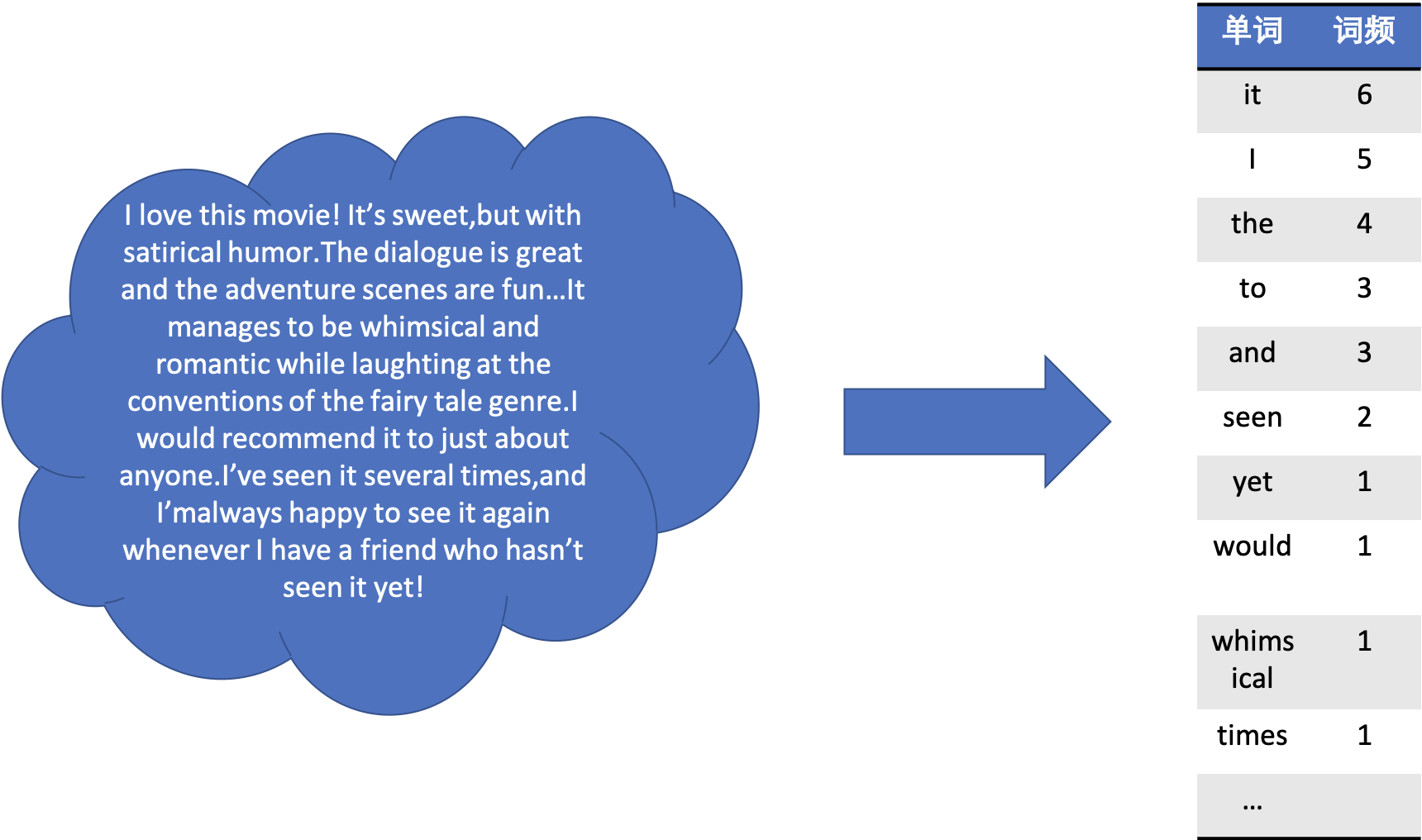
朴素贝叶斯的思想如下图所示,左边的云状图形表示我们需要处理的文本内容。我们采用词袋模型来表示文本,忽略文字之间的顺序,只保留词频信息,处理的结果如右边的表格所示。
朴素贝叶斯是一种概率分类器,对一个文档(d)来说,分类器会返回给调用者后验概率最大的类别(c)。
在Bayes的努力下,贝叶斯思想开始被大家所熟知,1964年Mosteller和Wallace将其应用到文本分类中。贝叶斯分类的思想是将贝叶斯法则应用到(1)式中,将其转化为一些有用的性质。贝叶斯法则如(2)所示,它给我们提供了一种将任何条件概率(P(x|y))转化为三种其他概率的方法。
将贝叶斯法则应用在(1)式子中,得到(3)式:
由于对每个类别来说,我们都需要计算(frac{P(d|c)P(c)}{P(d)}),然后取最大值对应的类别(c),分母(P(d))对每个类来说都是一样的,我们将其去掉以简化(3)式,得到(4)式:
根据(4)式可知,我们只需计算两个概率:先验概率(prior probability)(P(c))和似然(likelihood)(P(d|c)):
不失一般性地,我们可以用一系列特征来表示文档,如公式(6)所示:
公式(6)还是很难直接计算,需要做出一些假设。直接估计所有特征组合在一起的概率,需要大量的参数和难以获得的巨大训练集,因此朴素贝叶斯做出了如下两种假设:
- 第一种是词袋模型,我们假设位置是不重要的(当然位置也是比较重要的,此处的假设是由损失的),因此“love”出现在一句话的第一个字或者是第二十个字对分类结果的影响都是一样的。
- 第二种假设我们一般称为朴素贝叶斯假设,它假设特征之间独立,形式化的表现为公式(7):
综合以上内容,朴素贝叶斯分类器的思想可以表达为如下等式:
要讲朴素贝叶斯分类器应用在文本中,我们可以用单词的所有下标来遍历所有的单词以计算文档的类别。
像其他语言模型一样,朴素贝叶斯的计算空间也在log空间内,来避免算数下溢和提高计算速度。(9)式可以改写为如下形式:
通过log空间来计算特征,(10)将预测的类别表示成输入特征的线性函数。这类将输入表示为线性组合的分类器称为线性分类器,例如朴素贝叶斯和逻辑回归。