逻辑回归,名为回归,实际为分类
线性回归直接分析x与y的关系
LR分析y取某个值的概率和x的关系
分类:根据模型,对输入数据/样本,预测其归属的类别。
其中,最常见的就是二分类模型,例如逻辑回归。
逻辑回归模型,就是每个特征的回归系数,即wT。
性质:
◆线性分类器,若无特殊处理,无法解决非线性问题。
建模过程:
◆通过训练数据集,计算出“最合适”的系数向量。
◆“最合适”,可理解为错误概率最低的情况。
应用:
◆分类建模效果的Baseline之一。
类别A+非类别A
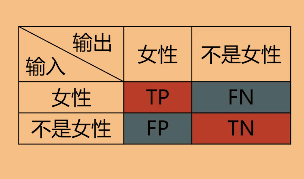
正确率(accuracy)
accuracy=(TP+TN)/(TP+TN+FP+FN)
精度(precision)
precision=TP/(TP+FP)
召回率(recall)
recall=TP/(TP+FN)
F1 score
F1=2pr/(p+r) # p=precision,r=recall
logistic回归(LR),是一种广义的线性回归分析模型。
常用于数据挖掘,疾病自动诊断,经济预测等领域。
优点:
计算代价相对较低,思路清晰易于理解和实现。
输出范围有限,数据在传递过程中不容易发散
输出范围为(0,1),所以可以用作输出层,输出表示概率
抑制两头,对中间细微变化敏感,对分类有利
缺点:
线性分类器(单一无法处理非线性),容易欠拟合,分类精度可能不高。
线性变换 :
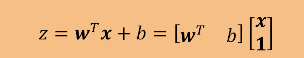
Sigmoid函数:
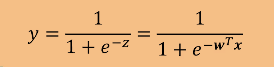
该函数可以把负无穷到正无穷的数映射到0-1的区间内
单位阶跃函数在0处不可导,计算麻烦,因此选用Sigmoid函数
极大似然估计
最大化每个样本属于真实标签的概率,则采用极大似然估计
Maximum likelihood:利用已知的样本结果,反推最有可能导致这样结果的参数值。
利用实验结果D={x1,x2…,Xw},得到某个参数值e,使样本出现的概率最大。
参考概率论
梯度
梯度是一个方向向量
表示某一函数在某点处沿着该方向(梯度的方向)变化最快
逻辑回归的一般过程
收集数据:采用任意方法收集数据
准备数据:由于需要进行距离计算,因此要求数据类型为数值型。另外,结构化数据格式则为最佳
分析数据:采用任意方法对数据进行分析
训练算法:大部分时间将用于训练,训练的目的是为了找到最佳的分类回归系数
测试算法:一旦训练步骤完成,分类将会很快
使用算法:首先,我们需要输入一些数据并将其转换成对应的结构化数值,接着,基于训练好的回归系数就可以对这些进行简单的回归计算,判定它们属于哪个类别;在这·之后,我们就可以在输出的类别上做一些其他分析工作
逻辑回归的关键
为了实现Logistic回归分类器,我们可以在每个特征上都乘以一个回归系数,然后把所有结果值相加,将这个总和带入Sigmoid函数中,进而得到一个范围在0~1之间的数字。任何大于0.5的数据被分为1类,小于0.5的被分为0类。所以吗,Logistic回归也可以被看成是一种概率估计。
确定了分类器的函数后。现在的问题变成了:最佳回归系数是多少?如何确定它们的大小?
为什么使用Sigmoid函数
在两个类的情况下。上述函数输出0或1,这样有助于更好的分类。拥有这种性质的函数有很多,但Sigmoid函数的优点太多。
关于更详细的解答参考点我查看
如何确定最佳回归系数
梯度上升法:要找到某函数的最大值,最好的方法就是沿着该函数的梯度方向探寻。(局部最优拓展到总体最优)
梯度下降法:求函数的最小值,类似于上升法,只是公式中的加号变为减号。
局部最优的迭代选择公式将一直执行,直到达到某个停止条件为止,比如迭代次数达到某个指定值或算法达到某个可允许的误差范围。
梯度上升法
伪代码:
每个回归系数初始化为1
重复R次:
计算整个数据集的梯度
使用alpha×gradient更新回归系数的向量
返回回归系数
随机梯度上升
伪代码
所有回归系数初始化为1
对数据集中每个样本
计算该样本的梯度
使用alpha×gradient更新回归系数值
返回回归系数值