Hive llap服务安装说明及测试
1.简介说明
从Hive 2.0引入了LLAP(Live Long And Process),2.1进行了比较大的优化,可以说hive已经走向了内存计算,
目前hortonworks测试llap +tez比hive1.x快了25倍,禁不住诱惑来玩一下
2.LLAP安装
2.1依赖
Hive llap服务安装依赖先安装tez,和slider(现在也可以不用),所以安装llap前先安装并测试好tez和slider;
2.2配置
Ambari安装好之后,还需要额外的两个步骤来开启Hive LLAP:
1.在yarn中开启Hive LLAP的优先使用权
2.打开hive中的Interactive Query开发并配置相关参数
以下是hive-site.xml配置 <!--llap configuration--> <property> <name>hive.execution.engine</name> <value>tez</value> </property>
<!--目前llap只支持tez做为引擎--> <property> <name>hive.llap.execution.mode</name> <value>all</value> </property> <!-- 有这四个auto, none, all, map选项,表示是否在llap或者container里运行查询,all表示让所有的task都在llap进程内执行--> <property> <name>hive.execution.mode</name> <value>llap</value> </property> <!-- 两个选项[container, llap],表示查询运行在container或者llap--> <property> <name>hive.llap.daemon.service.hosts</name> <value>@llap_service</value> </property> <!-- llap_service是启动llap服务的时候--name指定的名字,可根据情况来设置--> <property> <name>hive.zookeeper.quorum</name> <value>hd21:2181,hd22:2181,hd23:2181</value> </property> <property> <name>hive.llap.daemon.memory.per.instance.mb</name> <value>25600</value> </property> <!-- LlapDaemon内存,需要在这里指定,hive --service --instances指定遇到过失败--> <property> <name>hive.llap.daemon.num.executors</name> <value>8</value> </property> <!-- LlapDaemon core数--> <!--如下是HiveServer2的参数,用来启用llap的并发查询--> <property> <name>hive.server2.tez.default.queues</name> <value>root.storm</value> </property> <property> <name>hive.server2.tez.initialize.default.sessions</name> <value>true</value> </property> <property> <description>Set to the number of concurrent queries to run on the queues that are configured by hive.server2.tez.default.queues. This setting launches long-running Tez AMs (sessions). </description> <name>hive.server2.tez.sessions.per.default.queue</name> <value>2</value> </property>
2.3特殊注意
先检查python版本,别低于2.5最好2.7.X吧,然后进入hive2.1.1主目录下的scripts/llap/bin目录下,
编辑runLlapDaemon.sh启动脚本,在CLASSPATH变量中加入`hadoop classpath`,即加入hadoop的环境路径,
避免出现找不到相关类库的而导致的启动失败,如下:
3.启动服务
hive --service llap --name llap_service --instances 5 --size 25g --loglevel INFO --cache 10g --executors 10 --iothreads 10 --slider-am-container-mb 1024 --args " -XX:+UseG1GC -XX:+ResizeTLAB -XX:+UseNUMA -XX:-ResizePLAB"
启动服务的选项如下:
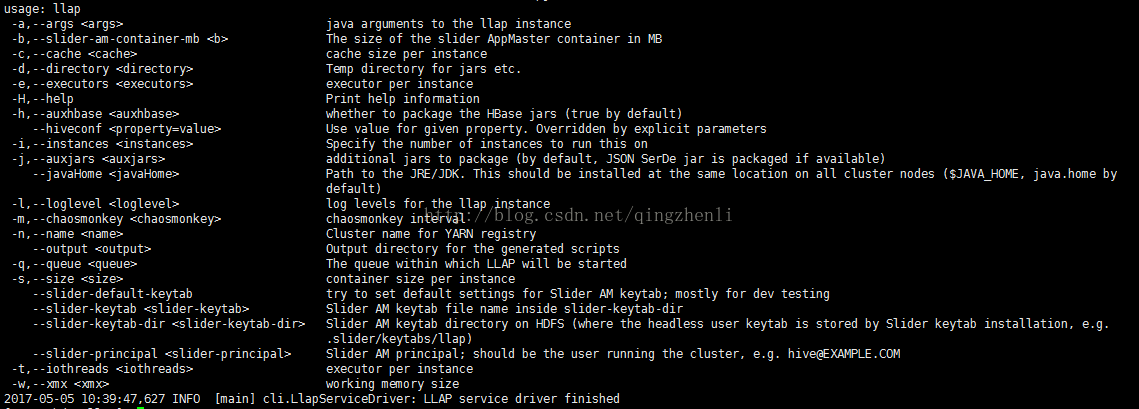
启动成功:

启动后会生成一个如下的文件夹:

进入可以看到有四个文件

其中run.sh这个启动shell就只是用slider来提交llap到yarn的脚本./run.sh即可启动到yarn中,启动后,可以看到yarn中的application如下:

RUNNING状态表示启动运行成功;
查看nodemanager节点可以看到有相应的daemon进程如下:

启动tez作业如下:
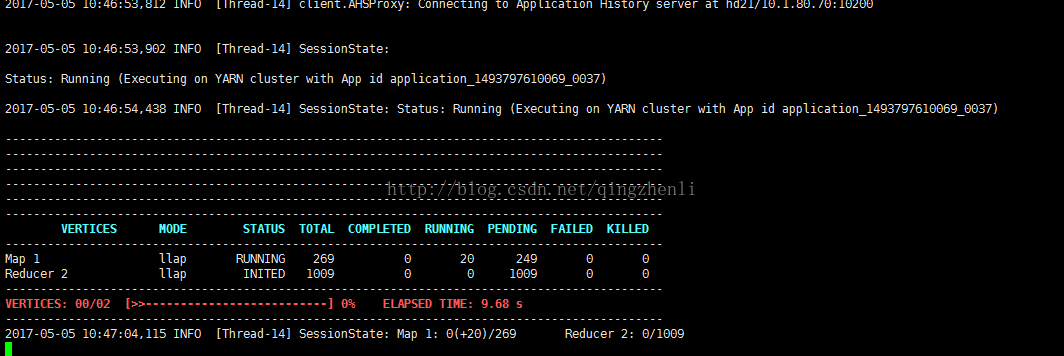
查看tez作业AM的资源情况可以看到tez的task都运行在llap中,只有am独立container运行;
从性能效率看,llap确实有了明显的提升,一个分区聚合数据和union相应另一个分区操作,数据100g,从资源时间消耗资源角度看资源减少了2倍,执行时间效率上提升了6倍,后面有空可以参照tpc-ds_v2.4.0做一些较全面的性能测试;
停止llap只用执行slider stop llap_service即可;