HTML操作是编程中很重要的一块,下面用Python3.x中的html.parser中的HTMLParser类来进行HTML的解析。
HTMLParser类定义及常用方法
-
标准库中的定义
class html.parser.HTMLParser(*, convert_charrefs=True)
- HTMLParser主要是用来解析HTML文件(包括HTML中无效的标记)
- 参数convert_charrefs表示是否将所有的字符引用自动转化为Unicode形式,Python3.5以后默认是True
- HTMLParser可以接收相应的HTML内容,并进行解析,遇到HTML的标签会自动调用相应的handler(处理方法)来处理,用户需要自己创建相应的子类来继承HTMLParser,并且复写相应的handler方法
- HTMLParser不会检查开始标签和结束标签是否是一对
-
常用方法
- HTMLParser.feed(data):接收一个字符串类型的HTML内容,并进行解析
HTMLParser.close():当遇到文件结束标签后进行的处理方法。如果子类要复写该方法,需要首先调用HTMLParser累的close()HTMLParser.reset():重置HTMLParser实例,该方法会丢掉未处理的html内容HTMLParser.getpos():返回当前行和相应的偏移量HTMLParser.handle_starttag(tag, attrs):对开始标签的处理方法。例如<div id="main">,参数tag指的是div,attrs指的是一个(name,Value)的列表HTMLParser.handle_endtag(tag):对结束标签的处理方法。例如</div>,参数tag指的是divHTMLParser.handle_data(data):对标签之间的数据的处理方法。<tag>test</tag>,data指的是“test”HTMLParser.handle_comment(data):对HTML中注释的处理方法。
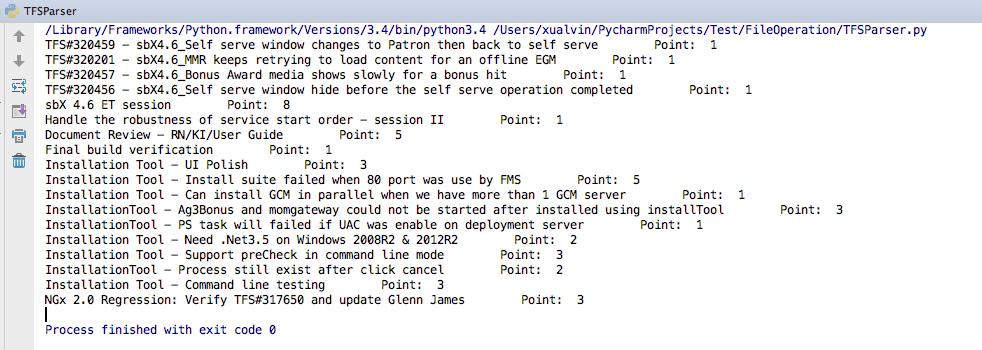
实例应用
- 待处理文件: http://files.cnblogs.com/files/AlwinXu/Scan_TFS.zip
- 代码
__author__ = 'xua'
import json
#For python 3.x
from html.parser import HTMLParser
#定义HTMLParser的子类,用以复写HTMLParser中的方法
class MyHTMLParser(HTMLParser):
#构造方法,定义data数组用来存储html中的数据
def __init__(self):
HTMLParser.__init__(self)
self.data = []
#覆盖starttag方法,可以进行一些打印操作
def handle_starttag(self, tag, attrs):
pass
#print("Start Tag: ",tag)
#for attr in attrs:
# print(attr)
#覆盖endtag方法
def handle_endtag(self, tag):
pass
#覆盖handle_data方法,用来处理获取的html数据,这里保存在data数组
def handle_data(self, data):
if data.count('
') == 0:
self.data.append(data)
#读取本地html文件.(当然也可以用urllib.request中的urlopen来打开网页数据并读取,这里不做介绍)
htmlFile = open(r"/Users/xualvin/Downloads/TFS.htm",'r')
content = htmlFile.read()
#创建子类实例
parser = MyHTMLParser()
#将html数据传给解析器进行解析
parser.feed(content)
#对解析后的数据进行相应操作并打印
for item in parser.data:
if item.startswith("{"columns""):
payloadDict = json.loads(item)
list = payloadDict["payload"]["rows"]
for backlog in list:
if backlog[1] == "Product Backlog Item" or backlog[1] == "Bug":
print(backlog[2]," Point: ",backlog[3])
- 输出结果