以下为python pandas 库的dataframe pivot()函数的官方文档:
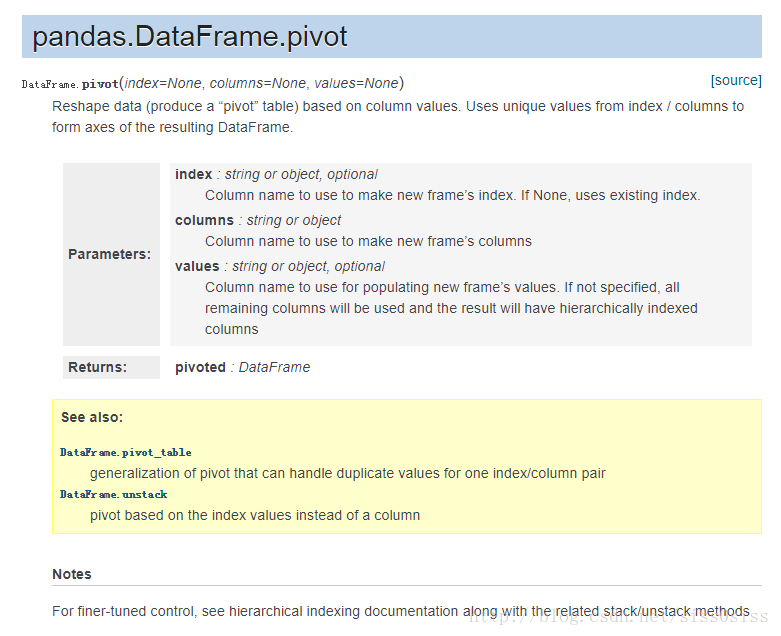
Reshape data (produce a “pivot” table) based on column values. Uses unique values from index / columns to form axes of the resulting DataFrame.
译:重塑数据(产生一个“pivot”表格)以列值为标准。使用来自索引/列的唯一的值(去除重复值)为轴形成dataframe结果。
For finer-tuned control, see hierarchical indexing documentation along with the related stack/unstack methods
译:为了精细调节控制,可以看和stack/unstack方法有关的分层索引文件.
============================================================================
在数据分析的时候要记得将pivot结果reset_index()。
示例:
import pandas as pd
df=pd.read_csv("user_label_part1.csv",sep=',',encoding='gbk')
df.head(10)
temp=df.pivot(index='user_log_acct',columns='item_third_cate_cd',values='label')
temp.to_csv("res.csv",sep=',',encoding='gbk')
df.head(3)
user_log_acct item_third_cate_cd label
0 AA 13691 1
1 BB 898 5
2 CC 898 2
temp.head(3)
item_third_cate_cd 870 878 880 898 1300 13117 13298 13690 13691
user_log_acct
AA NaN NaN NaN NaN NaN NaN NaN NaN 1.0
BB NaN NaN NaN 5.0 NaN NaN NaN NaN NaN
CC NaN NaN NaN 2.0 NaN NaN NaN NaN NaN
这样可以避免写 循环去将行转成列。