基于社交网络的推荐可以很好地模拟现实社会。在现实社会中,很多时候我们都是通过朋友获得推荐。
美国著名的第三方调查机构尼尔森调查了影响用户相信某个推荐的因素。调查结果该调查可以看到,好友的推荐对于增加用户对推荐结果的信任度非常重要。
尼尔森测试了同一个品牌的3种不同形式的广告。第一种广告和第二种广告都是图片广告,但两者的推荐理由不同。
第一种广告的推荐理由没有社会化信息,仅仅是表示该品牌受到了51 930个用户的关注,而第二种广告的推荐理由是用户的某些好友关注了这个广告。
第三种广告比较特别,它是在用户的好友关注该品牌时,就在用户的信息流中加入一条信息,告诉用户他的某个好友关注了一个品牌。
通过在线AB测试,尼尔森发现第三种广告的效果明显高于第二种,而第二种广告的效果明显高于第一种,从而证明了社会化推荐对于增加用户对广告的印象和购买意愿具有非常强烈的作用。同时,该实验也从侧面说明社交网络在推荐系统中可能具有重要的作用。
本章讨论:
1)如何利用社交网络数据给用户进行个性化推荐
2)利用社交网络给用户推荐好友
1、获取社交网络数据的途径
1)电子邮件
如果是公司邮箱,邮箱后缀信息,可以显示用户所属的公司
2)用户注册信息
有些网站需要用户在注册时填写一些诸如公司、学校等信息。有了这些信息后,我们就可以知道哪些用户曾经在同一家公司工作过,哪些用户曾经在同一个学校学习过。这也是一种隐性的社交网络数据。
3)用户的位置数据
在网页上最容易拿到的用户位置信息就是IP地址。对于手机等移动设备,我们可以拿到更详细的GPS数据。位置信息也是一种反映用户社交关系的数据。一般来说,在给定位置信息后,可以通过查表知道用户访问时的地址。这种地址在某些时候不太精确,只能精确到城市级别,但在有些时候可以精确到学校里的某栋宿舍楼或者某家公司。那么,我们也可以合理地假设同一栋宿舍楼或同一家公司的用户可能有好友关系。
4)论坛和讨论组
比如,豆瓣上有很多小组,每个小组都包含一些志同道合的人。如果两个用户同时加入了很多不同的小组,我们可以认为这两个用户很可能互相了解或者具有相似的兴趣。如果两个用户在讨论组中曾经就某一个帖子共同进行过讨论,那就更加说明他们之间的熟悉程度或兴趣相似度很高。
5) 即时聊天工具
和电子邮件系统一样,用户在即时聊天工具上也会有一个联系人列表,而且往往还会给联系人进行分组。通过这个列表和分组信息,我们就可以知道用户的社交网络关系,而通过统计用户之间聊天的频繁程度,可以度量出用户之间的熟悉程度。
6)社交网站
社交网站的另一个好处是自然地减轻了信息过载问题。在社交网站中,我们可以通过好友给自己过滤信息。比如,我们只关注那些和我们兴趣相似的好友,只阅读他们分享的信息,因此可以避免阅读很多和自己无关的信息。个性化推荐系统可以利用社交网站公开的用户社交网络和行为数据,辅助用户更好地完成信息过滤的任务,更好地找到和自己兴趣相似的好友,更快地找到自己感兴趣的内容。
社会图谱和兴趣图谱
Facebook和Twitter作为社交网站中的两个代表,它们其实代表了不同的社交网络结构。在Facebook里,人们的好友一般都是自己在现实社会中认识的人,比如亲戚、同学、同事等,而且Facebook中的好友关系是需要双方确认的。在Twitter里,人们的好友往往都是现实中自己不认识的,而只是出于对对方言论的兴趣而建立好友关系,好友关系也是单向的关注关系。以Facebook为代表的社交网络称为社交图谱(social graph),而以Twitter为代表的社交网络称为兴趣图谱(interest graph)。
但是,每个社会化网站都不是单纯的社交图谱或者兴趣图谱。一般认为,Facebook中的绝大多数用户联系基于社交图谱,而Twitter中的绝大多数用户联系基于兴趣图谱。但是,在Twitter或者微博中,我们也会关注现实中的亲朋好友,在Facebook中我们也会和一部分好友有同样的兴趣。
2、社交网络数据简介
问题抽象:
社交网络定义了用户之间的联系,因此可以用图定义社交网络。我们用图G(V,E,w)定义一个社交网络,其中V是顶点集合,每个顶点代表一个用户,E是边集合, w 定义了边的权重。业界有两种著名的社交网络。一种以Facebook为代表,它的朋友关系是需要双向确认的,因此在这种社交网络上可以用无向边连接有社交网络关系的用户。另一种以Twitter为代表,它的朋友关系是单向的,因此可以用有向边代表这种社交网络上的用户关系。
此外,对图G中的用户顶点u,定义out(u)为顶点u指向的顶点集合(如果套用微博中的术语,out(u)就是用户u关注的用户集合),定义in(u)为指向顶点u的顶点集合(也就是关注用户u的用户
集合)。那么,在Facebook这种无向社交网络中显然有out(u)=in(u)。
一般来说,有3种不同的社交网络数据:
双向确认的社交网络数据 在以Facebook和人人网为代表的社交网络中,用户A和B之间形成好友关系需要通过双方的确认。因此,这种社交网络一般可以通过无向图表示。
单向关注的社交网络数据 在以Twitter和新浪微博为代表的社交网络中,用户A可以关注用户B而不需要得到用户B的允许,因此这种社交网络中的用户关系是单向的,可以通过有向图表示。
基于社区的社交网络数据 还有一种社交网络数据,用户之间并没有明确的关系,但是这种数据包含了用户属于不同社区的数据。比如豆瓣小组,属于同一个小组可能代表了用户兴趣的相似性。或者在论文数据集中,同一篇文章的不同作者也存在着一定的社交关系。或者是在同一家公司工作的人,或是同一个学校毕业的人等。
社交网络数据中的长尾分布
和前面第2章提到的用户活跃度分布和物品流行度分布类似,社交网络中用户的入度(in degree)和出度(out degree)的分布也是满足长尾分布的。
用户的入度反映了用户的社会影响力。用户的入度近似长尾分布,这说明在一个社交网络中影响力大的用户总是占少数。
而出度代表了一个用户关注的用户数,该图说明在一个社交网络中,关注很多人的用户占少数,而绝大多数用户只关注很少的人。
3、基于社交网络的推荐
很多网站都利用Facebook的社交网络数据给用户提供社会化推荐。视频推荐网站Clicker利用用户在Facebook的好友信息给用户推荐好友喜欢的视频,并且用好友进行了推荐解释。
亚马逊网利用用户在Facebook的好友信息给用户推荐好友喜欢的商品,同时也使用好友进行了推荐解释。
社会化推荐之所以受到很多网站的重视,是缘于如下优点:
好友推荐可以增加推荐的信任度 好友往往是用户最信任的。用户往往不一定信任计算机的智能,但会信任好朋友的推荐。同样是给用户推荐《天龙八部》,前面提到的基于物品的协同过滤算法会说是因为用户之前看过《射雕英雄传》,而好友推荐会说是因为用户有8个好友都非常喜欢《天龙八部》。对比这两种解释,第二种解释一般能让用户更加心动,从而购买或者观看《天龙八部》。
社交网络可以解决冷启动问题 当一个新用户通过微博或者Facebook账号登录网站时,我们可以从社交网站中获取用户的好友列表,然后给用户推荐好友在网站上喜欢的物品。从而我们可以在没有用户行为记录时就给用户提供较高质量的推荐结果,部分解决了推荐系统的冷启动问题。
当然,社会化推荐也有一些缺点,。特别是在基于社交图谱数据的推荐系统中,因为用户的好友关系不是基于共同兴趣产生的,所以用户好友的兴趣往往和用户的兴趣并不一致。比如,我们和自己父母的兴趣往往就差别很大。
1)基于邻域的社会化推荐算法
如果给定一个社交网络和一份用户行为数据集。其中社交网络定义了用户之间的好友关系,而用户行为数据集定义了不同用户的历史行为和兴趣数据。
那么我们想到的最简单算法是给用户推荐好友喜欢的物品集合。即用户u对物品i的兴趣pui可以通过如下公式计算:

2)基于图的社会化推荐算法
前几章都提到了如何在推荐系统中使用图模型,比如用户物品二分图、用户-物品-标签图模型等。从前面几章的介绍可以看到,图模型的优点是可以将各种数据和关系都表示到图上去。
在社交网站中存在两种关系,一种是用户对物品的兴趣关系,一种是用户之间的社交网络关系。本节主要讨论如何将这两种关系建立到图模型中,从而实现对用户的个性化推荐。
用户的社交网络可以表示为社交网络图,用户对物品的行为可以表示为用户物品二分图,而这两种图可以结合成一个图。图6-7是一个结合了社交网络图和用户物品二分图的例子。
该图上有用户顶点(圆圈)和物品顶点(方块)两种顶点。如果用户u对物品i产生过行为,那么两个节点之间就有边相连。比如该图中用户A对物品a、e产生过行为。
如果用户u和用户v是好友,那么也会有一条边连接这两个用户,比如该图中用户A就和用户B、D是好友。
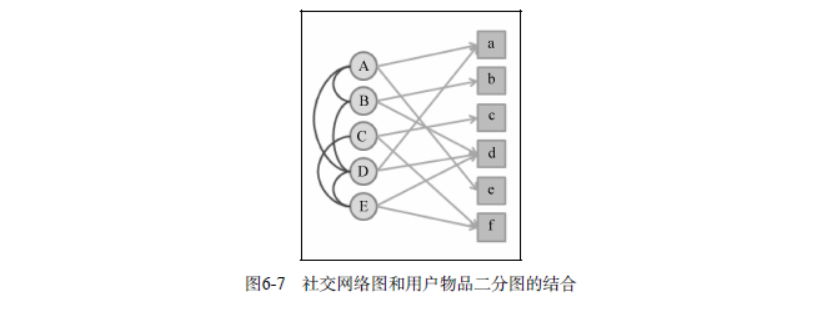
在定义完图中的顶点和边后,需要定义边的权重。其中用户和用户之间边的权重可以定义为用户之间相似度的α 倍(包括熟悉程度和兴趣相似度),而用户和物品之间的权重可以定义为用户对物品喜欢程度的β 倍。
α 和β 需要根据应用的需求确定。如果我们希望用户好友的行为对推荐结果产生比较大的影响,那么就可以选择比较大的α 。相反,如果我们希望用户的历史行为对推荐结果产生比较大的影响,就可以选择比较大的β 。
在定义完图中的顶点、边和边的权重后,我们就可以利用前面几章提到的PersonalRank图排序算法给每个用户生成推荐结果。
在社交网络中,除了常见的、用户和用户之间直接的社交网络关系,还有一种关系,即两个用户属于同一个社群。
他们将第一种社交网络关系称为friendship,而将第二种社交网络关系称为membership。如果要在前面提到的基于邻域的社会化推荐算法中考虑membership的社交关系,可以利用两个用户加入的社区重合度计算用户相似度,然后给用户推荐和他相似的用户喜欢的物品。但是,如果利用图模型,我们就很容易同时对friendship和membership建模。如图6-8所示,可以加入一种节点表示社群(最左边一列的节点),而如果用户属于某一社群,图中就有一条边联系用户对应的节点和社群对应的节点。在建立完图模型后,我们就可以通过前面提到的基于图的推荐算法(比如PersonalRank)给用户推荐物品。

3) 实际系统中的社会化推荐算法
前面提出的,基于邻域的社会化推荐算法看起来非常简单,但在实际系统中却是很难操作的,这主要是因为该算法需要拿到用户所有好友的历史行为数据,而这一操作在实际系统中是比大型网站中用户数目非常庞大,用户的历史行为记录也非常庞大,所以不太可能将用户的所有行为都缓存在内存中,只能在数据库前做一个热数据的缓存。而如果我们需要比较实时的数据,这个缓存中的数据就要比较频繁地更新,因而避免不了数据库的查询。我们知道,数据库查询一般是很慢的,特别是针对行为很多的用户更是如此。所以,如果一个算法再给一个用户做推荐时,需要他所有好友的历史行为数据,这在实际环境中是比较困难的。
如果回想一下ItemCF可以发现,ItemCF算法只需要当前用户的历史行为数据和物品的相关表就可以生成推荐结果。对于物品数不是特别多的网站,可以很容易地将物品相关表缓存在内存中,因此查询相关物品的代价很低,所以ItemCF算法很容易在实际环境下实现。
当然,我们可以从几个方面改进基于邻域的社会化推荐算法,让它能够具有比较快的响应时间。改进的方向有两种,一种是治标不治本的方法。简单地说,就是可以做两处截断。第一处截断就是在拿用户好友集合时并不拿出用户所有的好友,而是只拿出和用户相似度最高的N个好友。
而第二种解决方案需要重新设计数据库。通过前面的分析可以发现,社会化推荐中关键的操作就是拿到用户所有好友的行为数据,然后通过一定的聚合展示给用户。
这样做的问题, 以及微博容易挂的原因:
如果对照一下微博,我 们就可以发现微博中每个用户都有一个信息墙,这个墙上实时展示着用户关注的所有好友的动 态。因此,如果能够实现这个信息墙,就能够实现社会化推荐算法。Twitter的解决方案是给每 个用户维护一个消息队列(message queue),当一个用户发表一条微博时,所有关注他的用户的 消息队列中都会加入这条微博。这个实现的优点是用户获取信息墙时可以直接读消息队列,所 以终端用户的读操作很快。不过这个实现也有缺点,当一个用户发表了一条微博,就会触发很 多写操作,因为要更新所有关注他的用户的消息队列,特别是当一个人被很多人关注时,就会有 大量的写操作。Twitter通过大量的缓存解决了这一问题。具体的细节可以参考InfoQ对Twitter架构 的介绍①。
如果将Twitter的架构搬到社会化推荐系统中,我们就可以按照如下方式设计系统:
首先,为每个用户维护一个消息队列,用于存储他的推荐列表;
当一个用户喜欢一个物品时,就将(物品ID、用户ID和时间)这条记录写入关注该用户的推荐列表消息队列中;
当用户访问推荐系统时,读出他的推荐列表消息队列,对于这个消息队列中的每个物品,重新计算该物品的权重。计算权重时需要考虑物品在队列中出现的次数,物品对应的用户和当前用户的熟悉程度、物品的时间戳。同时,计算出每个物品被哪些好友喜欢过,用这些好友作为物品的推荐解释。
4) 社会化推荐系统和协同过滤推荐系统
社会化推荐系统的效果往往很难通过离线实验评测,因为社会化推荐的优势不在于增加预测准确度,而是在于通过用户的好友增加用户对推荐结果的信任度,从而让用户单击那些很冷门的推荐结果。此外,很多社交网站(特别是基于社交图谱的社交网站)中具有好友关系的用户并不一定有相似的兴趣。因此,利用好友关系有时并不能增加离线评测的准确率和召回率。因此,很多研究人员利用用户调查和在线实验的方式评测社会化推荐系统。
从数据可以看出,好友推荐结果的用户满意度明显高于基于协同过滤的亚马逊推荐系统。
不过作者也承认实验存在一些问题。其中两个主要的问题如下:
不是双盲实验,参试者知道什么结果来自基于协同过滤的推荐系统,什么结果来自好友的推荐;
参试者在实验室中的行为可能和他们平时的真实行为不同。
5) 信息流推荐
信息流推荐是社会化推荐领域的新兴话题,它主要针对Twitter和Facebook这两种社交网站。
在这两种社交网站中,每个用户都有一个信息墙,展示了用户好友最近的言论。这个信息墙无疑已经是个性化的,但是里面还是夹杂了很多垃圾信息。这主要是因为我们并不关心我们关注的好友的所有言论,而只关心他们的言论中和自己相关的部分。虽然我们在选择关注时已经考虑了关注对象和自己兴趣的相似度,但显然我们无法找到和自己兴趣完全一致的人。因此,信息流的个性化推荐要解决的问题就是如何进一步帮助用户从信息墙上挑选有用的信息。
目前最流行的信息流推荐算法是Facebook的EdgeRank,该算法综合考虑了信息流中每个会话的时间、长度与用户兴趣的相似度。EdgeRank算法比较神秘,没有相关的论文,不过TechCrunch曾经公开过它的主要思想①。
Facebook将其他用户对当前用户信息流中的会话产生过行为的行为称为edge,而一条会话的权重定义为:

其中:
u 指产生行为的用户和当前用户的相似度,这里的相似度主要是在社交网络图中的熟悉度;
w 指行为的权重,这里的行为包括创建、评论、like(喜欢)、打标签等,不同的行为有不同的权重。
d 指时间衰减参数,越早的行为对权重的影响越低。
从上面的描述中可以得出如下结论:如果一个会话被你熟悉的好友最近产生过重要的行为,它就会有比较高的权重。
不过,EdgeRank算法的个性化因素仅仅是好友的熟悉度,它并没有考虑帖子内容和用户兴趣的相似度。
所以EdgeRank仅仅考虑了“我”周围用户的社会化兴趣,而没有重视“我”个人的个性化兴趣。为此,GroupLens的研究人员Jilin Chen深入研究了信息流推荐中社会兴趣和个性化兴趣之间的关系。①他们的排名算法考虑了如下因素。
会话的长度 越长的会话包括越多的信息。
话题相关性 度量了会话中主要话题和用户兴趣之间的相关性。这里Jilin Chen用了简单的TF-IDF建立用户历史兴趣的关键词向量和当前会话的关键词向量,然后用这两个向量的相似度度量话题相关性。
用户熟悉程度 主要度量了会话中涉及的用户(比如会话的创建者、讨论者等)和当前用户的熟悉程度。对于如何度量用户的熟悉程度下一节将详细介绍。计算熟悉度的主要思想是考虑用户之间的共同好友数等。
为了验证算法的性能,Jilin Chen同样也设计了一个用户调查。首先,他通过问卷将用户分成两种类型。
第一种类型的用户使用Twitter的目的是寻找信息,也就是说他们将Twitter看做一种信息源和新闻媒体。而第二种用户使用Twitter的目的是了解好友的最新动态以及和好朋友聊天。然后,他让参试者对如下5种算法的推荐结果给出1~5分的评分,其中1分表示不喜欢,5分表示最喜欢。
Random 给用户随机推荐会话。
Length 给用户推荐比较长的会话。
Topic 给用户推荐和他兴趣相关的会话。
Tie 给用户推荐和他熟悉的好友参与的会话。
Topic+Tie 综合考虑会话和用户的兴趣相关度以及用户好友参与会话的程度。
通过收集用户反馈,Jilin Chen发现(如图6-11所示),对于所有用户不同算法的平均得分是:
Topic+Tie > Tie > Topic > Length > Random
而对于主要目的是寻找信息的用户,不同算法的得分是:
Topic+Tie ≥ Topic > Length > Tie > Random
对于主要目的是交友的用户,不同算法的得分是:
Topic+Tie > Tie > Topic > Length > Random
实验结果说明,综合考虑用户的社会兴趣和个人兴趣对于提高用户满意度是有帮助的。因此,当我们在一个社交网站中设计推荐系统时,
可以综合考虑这两个因素,找到最合适的融合参数融合用户的社会兴趣和个人兴趣,从而给用户提供最令他们满意的推荐结果。
4、给用户推荐好友
好友关系是社会化网站的重要组成部分,如果用户的好友很稀少,就不能体验到社会化的好处。因此好友推荐是社会化网站的重要应用之一。好友推荐系统的目的是根据用户现有的好友、用户的行为记录给用户推荐新的好友,从而增加整个社交网络的稠密程度和社交网站用户的活跃度。3个著名社交网站Twitter、LinkedIn和Facebook的好友推荐界面。由此可以说明,好友推荐模块已经成为社交网站的标准配置之一。
好友推荐算法在社交网络上被称为链接预测(link prediction)。关于链接预测算法研究的代表文章是Jon Kleinberg的“Link Prediction in Social Network”。
该文对各种用户好友关系的预测方法进行了系统地研究和对比。本章我们将介绍其中一些比较直观和简单的算法。
1)基于内容的匹配
我们可以给用户推荐和他们有相似内容属性的用户作为好友(如图6-15所示)。下面给出了常用的内容属性。
用户人口统计学属性,包括年龄、性别、职业、毕业学校和工作单位等。
用户的兴趣,包括用户喜欢的物品和发布过的言论等。
用户的位置信息,包括用户的住址、IP地址和邮编等。
利用内容信息计算用户的相似度和我们前面讨论的利用内容信息计算物品的相似度类似。
2) 基于共同兴趣的好友推荐
在Twitter和微博为代表的以兴趣图谱为主的社交网络中,用户往往不关心对于一个人是否在现实社会中认识,而只关心是否和他们有共同的兴趣爱好。因此,在这种网站中需要给用户推荐和他有共同兴趣的其他用户作为好友。
我们在第3章介绍基于用户的协同过滤算法(UserCF)时已经详细介绍了如何计算用户之间的兴趣相似度,其主要思想就是如果用户喜欢相同的物品,则说明他们具有相似的兴趣。在新浪微博中,可以将微博看做物品,如果两个用户曾经评论或者转发同样的微博,说明他们具有相似的兴趣。在Facebook中,因为有大量用户Like(喜欢)的数据,所以更容易用UserCF算法计算用户的兴趣相似度。
此外,也可以根据用户在社交网络中的发言提取用户的兴趣标签,来计算用户的兴趣相似度。关于如何分析用户发言的内容、提取文本的关键词、计算文本的相似度,可以参考第4章。
3) 基于社交网络图的好友推荐
在社交网站中,我们会获得用户之间现有的社交网络图,然后可以基于现有的社交网络给用户推荐新的好友,比如可以给用户推荐好友的好友。
最简单的好友推荐算法是给用户推荐好友的好友。在人人网,我们经常可以通过这个功能找到很多自己的老同学。在刚开始用人人网时,我们只能加入有限的好友,因为我们记住的好友有限。虽然我们只能记住几个同学,但那些同学又能记住几个不同的同学,在这种情况下,我们可以通过朋友的朋友找到更多我们认识的人。




前面讨论的这些相似度都是基于一些简单计算公式给出的。这些相似度的计算无论时间复杂度还是空间复杂度都不是很高,非常适合在线应用使用。
从表中结果可以看到,不同数据集上不同算法的性能并不相同。在实际系统中我们需要在自己的数据集上对比不同的算法,找到最适合自己数据集的好友推荐算法。
5) 基于用户调查的好友推荐算法对比
对于前面3节提出的几种不同的好友推荐算法,上一节提到的GroupLen的Jilin Chen也进行了研究。他通过用户调查对比了不同算法的用户满意度①,其中算法(这里我们使用了不同的命名)如下:
InterestBased 给用户推荐和他兴趣相似的其他用户作为好友。
SocialBased 基于社交网络给用户推荐他好友的好友作为好友。
Interest+Social 将InterestBased算法推荐的好友和SocialBased算法推荐的好友按照一定权重融合。
SONA SONA是IBM内部的推荐算法,该算法利用大量用户信息建立了IBM员工之间的社交网络。这些信息包括所在的部门、共同发表的文章、共同写的Wiki、IBM的内部社交网络信息、共同合作的专利等。
社交网络分析的研究已经有很悠久的历史了。其中关于社交网络最让人耳熟能详的结论就是六度原理。六度原理讲的是社会中任意两个人都可以通过不超过6个人的路径相互认识,如果转化为图的术语,就是社交网络图的直径为6。六度原理的正确六度原理在均匀随机图上已经得到了完美证明,对此感兴趣的读者可以参考Random Graph一书。很多对社交网络的研究都是基于随机图理论的,因此深入研究社交网络必须掌握随机图理论的相关知识。
社交网络研究中有两个最著名的问题。第一个是如何度量人的重要性,也就是社交网络顶点的中心度(centrality),第二个问题是如何度量社交网络中人和人之间的关系,也就是链接预测。这两个问题的研究都有着深刻的实际意义,因此得到了业界和学术界的广泛关注。