大纲:目的介绍sql server 中执行计划的大致使用,当遇到查询性能瓶颈时,可以发挥用处,而且带有比较详细的学习文档和计划,阅读者可以按照我计划进行,从而达到对执行计划一个比较系统的学习。
-
什么是sql server 执行计划
-
sql server 执行计划的大致使用
-
学习计划
1.什么是sql server 执行计划
- 执行计划是查询优化器对我们提交的T-SQL查询请求的最有效方法的的执行结果,执行计划可以告诉我们查询是如何执行的,当数据库查询进行故障排查时,使用执行计划是最主要的方法。
- 执行计划的展现方式有三种,视图型,文本类型,xml类型。
2.sql server的大致使用 下面是一个小例子
选中需要查询数据,右键出现 Display Estimated Execution Plan,或者使用快捷键Ctrl + L,可以马上查看执行计划

结果:

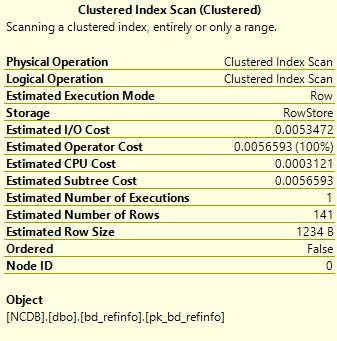
右键放在查询计划图标上面可以看到下面详细信息,命中的索引,I/O 消耗信息,CPU 消耗,查询结果行数,非常直观的可以看出各种参数
3.学习路线
学习执行计划中各种图标含义,图标学习地址:https://msdn.microsoft.com/zh-cn/library/ms191158(v=sql.120).aspx
加上微软官方的一些学习文档:https://msdn.microsoft.com/zh-cn/library/ms178071(v=sql.105).aspx
下面是我认为写的比较好的一些实战介绍:
http://www.cnblogs.com/biwork/archive/2013/04/11/3015655.html(详细介绍 执行计划)
http://www.cnblogs.com/fish-li/archive/2011/06/06/2073626.html(看懂SqlServer查询计划)
http://www.cnblogs.com/kissdodog/p/3160560.html(SQL Server执行计划的理解)
这仅仅是一个入门,如果有感兴趣的人,可以自己认真阅读链接文章。
前期准备:
create table Employee (
ID int not null primary key,
Name nvarchar(4),
Credit_Card_ID varbinary(max)); --- 小心这种数据类型。
go
说明:本表上的索引,都会在创建下一个索引前删除。
-------------------------------------------------------------------------------------------------------------------------------------------------------------
操作 1、
创建聚集索引
方法 1、
alter table table_name add constraint cons_name priamry key(columnName ASC|DESC,[.....]) with (drop_existing = on);
alter table Employee
add constraint PK_for_Employee primary key clustered (ID);
go
这个是一种特别的方法,因为在定义主键的时候,会自动添加索引,好在加的是聚集索引还是非聚集索引是我们人为可以控制的。
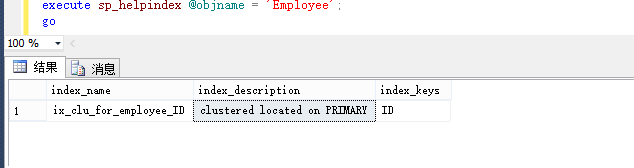
通过sp_helpindex 可以查看表中的索引
execute sp_helpindex @objname = 'Employee';
go

注意、
这个索引是无法删除的,不信! 你去删一下
drop index Employee.PK__Employee__3214EC277D95E615;
go

方法 2、
create clustered index ix_name on table_name(columnName ASC|DESC[,......]) with (drop_existing = on);方法
create clustered index ix_clu_for_employee_ID on Employee(ID);
go
查看创建的索引
操作 2、
创建复合索引
create index ix_com_Employee_IDName on Employee (ID,Name)with (drop_existing = on);
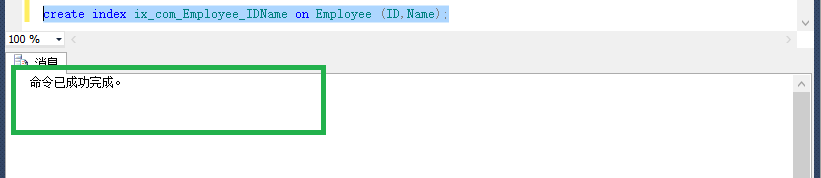
这样就算是创建一个复合索引了,不过脚下的路很长,我们看下一个复合索引的例句:
create index ix_com_Employee_IDCreditCardID on Employee(ID,Credit_Card_ID);
看到这句话,你先问一下自己它有没有错!
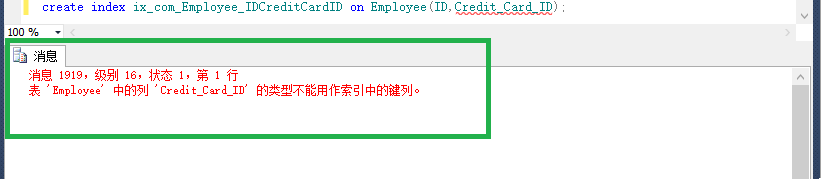
可以发现它错了,varbinary是不可以建索引的。
操作 3、
创建覆盖索引
create index index_name on table_Name (columnName ASC|DESC[,......]) include(column_Name_List)with (drop_existing = on);
create index ix_cov_Employee_ID_Name on Employee (ID) include(Name);
go
首先,覆盖索引它只是非聚集索引的一种特别形式,下文说的非聚集索引不包涵覆盖索引,当然这个约定只适用于这一段话,这样做的
目的是为了说明各中的区别。
首先:
1、非聚集索引不包涵数据,通过它找到的只是文件中数据行的引用(表是堆的情况下)或是聚集索引的引用,SQL Server
要通这个引用去找到相应的数据行。
2、正因为非聚集索引它没有数据,才引发第二次查找。
3、覆盖索引就是把数据加到非聚集索引上,这样就不需要第二次查找了。这是一种以空间换性能的方法。非聚集索引也是。
只是做的没有它这么出格。
操作 4、
创建唯一索引
create unique index index_name on table_name (column ASC|DESC[,.....])with (drop_existing = on);
正如我前面所说,在创建表上的索引前,我会删除表上的所有索引,这里为什么我要再说一下呢!因为我怕你忘了。二来这个例子用的到它。
目前表是一个空表,我给它加两行数据。
insert into Employee(ID,Name) values(1,'AAA'),(1,'BBB');

这下我们为表加唯一索引,它定义在ID这个列上
create unique index ix_uni_Employee_ID on Employee(ID);
go -- 可以想到因为ID有重复,所以它创建不了。

结论 1、 如果在列上有重复值,就不可以在这个列上定义,唯一索引。
下面我们把表清空: truncate table Employee;

接下来要做的就是先,创建唯一索引,再插入重复值。
create unique index ix_uni_Employee_ID on Employee(ID);
go
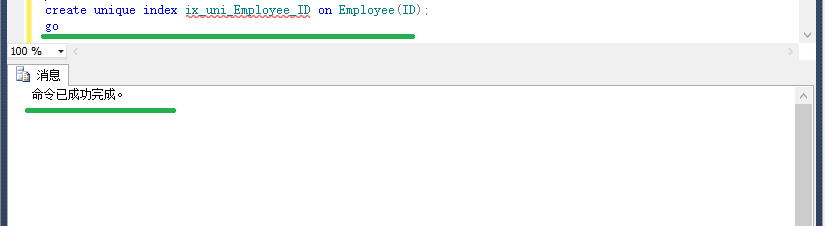
insert into Employee(ID,Name) values(1,'AAA'),(1,'BBB');
go

结论 2、
定义唯一索引后相应的列上不可以插入重复值。
操作 5、
筛选索引
create index index_name on table_name(columName) where boolExpression;
create index ix_Employee_ID on Employee(ID) where ID>100 and ID< 200;
go
只对热点数据加索引,如果大量的查询只对ID 由 100 ~ 200 的数据感兴趣,就可以这样做。
1、可以减小索引的大小
2、为据点数据提高查询的性能。
总结:
BTree 索引有聚集与非聚集之分。
就查看上到聚集索引性能比非聚集索引性能要好。
非聚集索引分 覆盖索引,唯一索引,复合索引(当然聚集索引也有复合的,复合二字,只是说明索引,引用了多列),一般非聚集索引
就查看上到非聚集索引中覆盖索引的性能比别的非聚集索引性能要好,它的性能和聚集索引差不多,可是
它也不是’银弹‘ 它会用更多的磁盘空间。
最后说一下这个
with (drop_existing = on|off),加上这个的意思是如果这个索引还在表上就drop 掉然后在create 一个新的。特别是在聚集索引上
用使用这个就可以不会引起非聚集索引的重建。
with (online = on|off) 创建索引时用户也可以访问表中的数据,
with(pad_index = on|off fillfactor = 80); fillfactor 用来设置填充百分比,pad_index 只是用来连接fillfactor 但是它又不难少,
这点无语了。
with(allow_row_locks = on|off | allow_page_locks = on |off); 是否允许页锁 or 行锁
with (data_compression = row | page ); 这样可以压缩索引大小
如果需要进行SQl Server下的SQL性能优化,需要准备以下内容:
一、SQL查询分析器设置:
1、开启实际执行计划跟踪。
2、每次执行需优化SQL前,带上清除缓存的设置SQL。
平常在进行SQL Server性能优化时,为了确保真实还原性能问题,我们需要关闭SQL Server自身的执行计划及缓存。可以通过以下设置清除缓存。
1 DBCC DROPCLEANBUFFERS --清除缓冲区 2 DBCC FREEPROCCACHE --删除计划高速缓存中的元素
3、开启查询IO读取统计、查询时间统计。
SET STATISTICS TIME ON --执行时间 SET STATISTICS IO ON --IO读取
开启设置后,执行SQL效果如下:
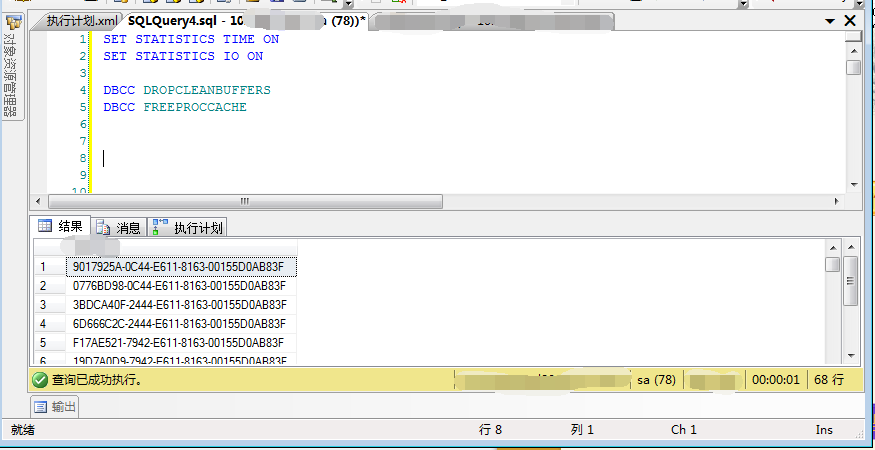
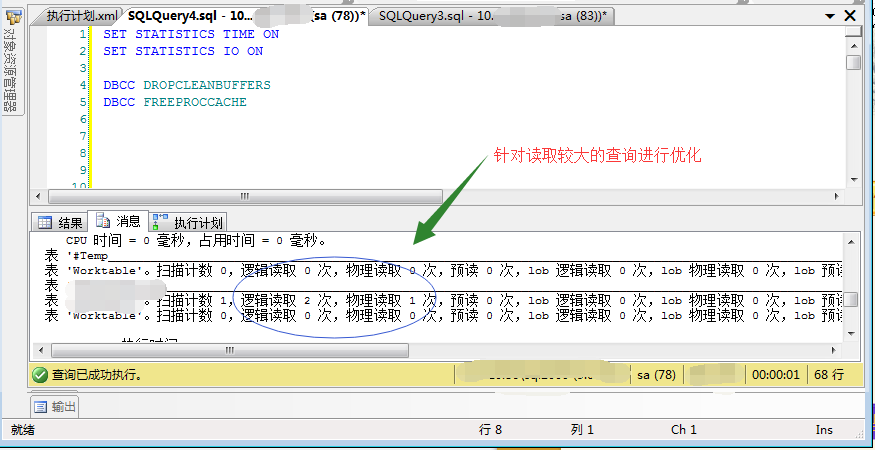
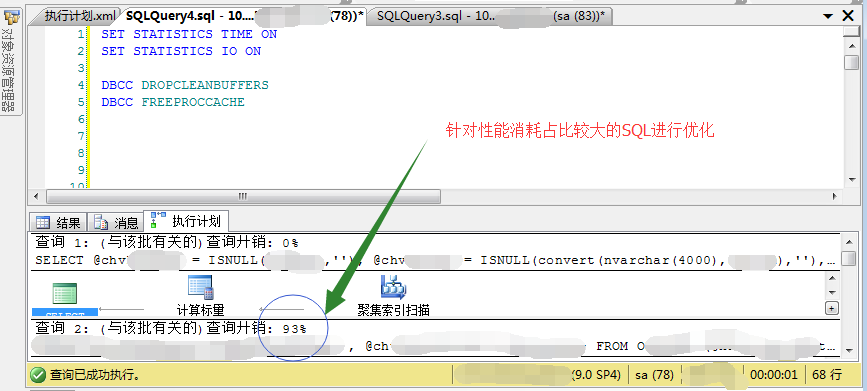
针对其中的每个图标节点,鼠标滑上去的时候,可以看到具体的执行信息。如下图:
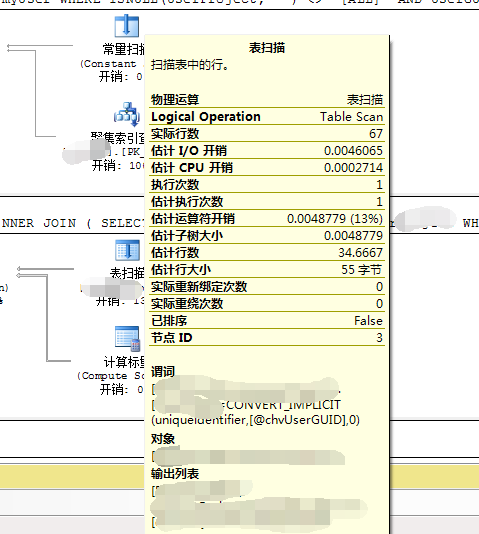
可以通过查看谓词、对象、输出列表,分析问题点或者创建优化索引等。
当然你也可以换一种查看方式,点击右键选择显示执行计划XML。
还有一点特别说明的是:当你SQL很长逻辑关系很复杂的时候,执行计划会是一个很大的网状关系图,你会发现在右下角有一个加号的按钮,点击后一个缩略图。通过缩略图你可以很方便的定位执行节点,用起来还比较好用。
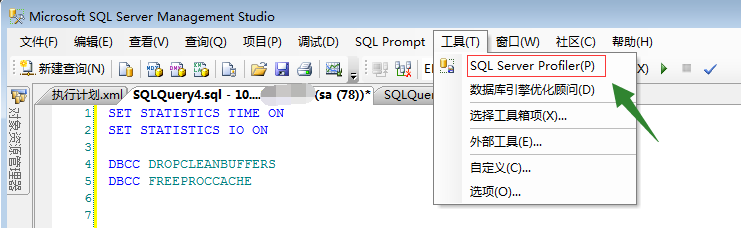
二、针对SQL Server Profile,SQL查询跟踪器进行分析。
1、打开方式:SQL Server查询分析器->工具,SQL Profile。打开方式截图:
2、连接&特殊设置:
打开后界面如下图:
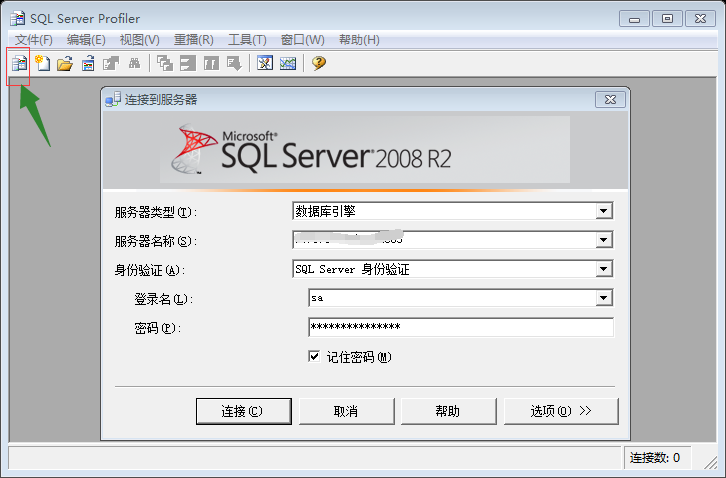
设置正确连接信息后,点击连接,弹出如下界面。按照图中操作步骤进行设置。
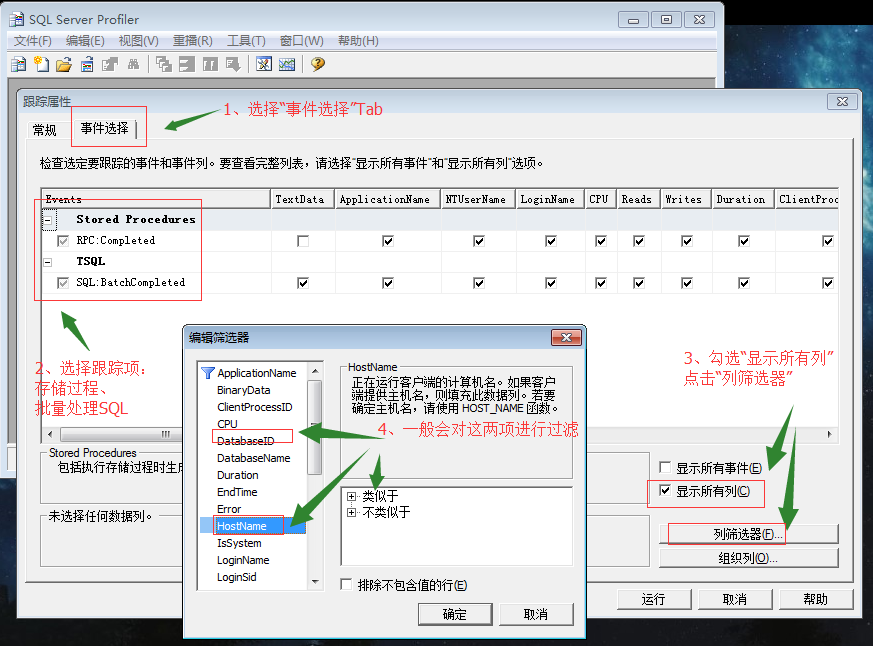
其中DatabaseId、HostName可以在查询分析器中进行查询,脚本如下:
1 SELECT DB_ID() 2 SELECT DB_NAME() 3 SELECT HOST_ID() 4 SELECT HOST_NAME()
实际上HostName就是你的本机计算机名。
最终设置完之后点击运行。正常跟踪的效果如图:
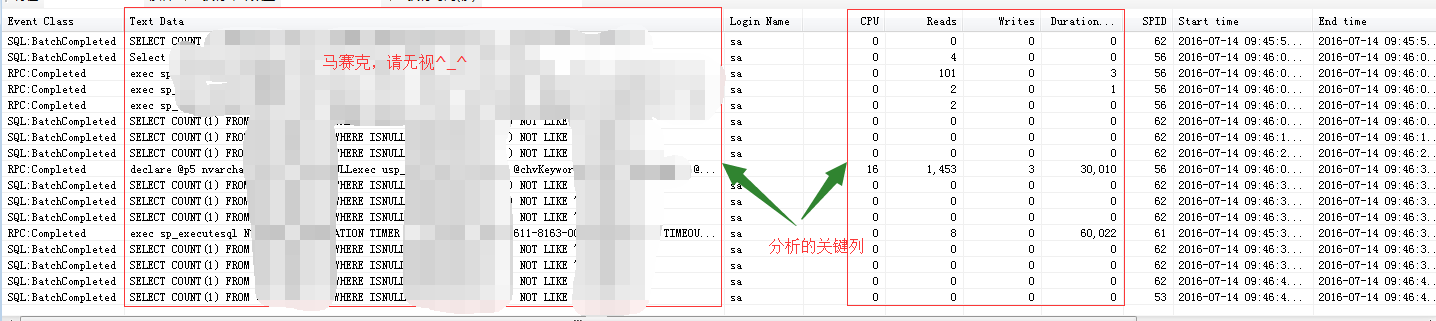
重点关注其中的Duration、Writes、Reads、CPU,分析对象是TextData,及执行的语句。其中Duration为毫秒数,1000即为1秒。
——————————————————————————————————————————
应用总结&建议:
上面应用配合方式是:
1、先通过SQL查询跟踪器,跟踪出你所以执行的SQL,然后定位其中Duration比较的SQL 或者超过性能标准的SQl(比如页面访问3s、5s、8s)、报表30s等。
2、将问题SQL在查询分析器中进行分析,主要通过执行计划及IO统计定位耗时占比高及IO读取大的地方,然后逐步的调整SQL逻辑关系(比如添加业务条件过滤缩小集合,建立索引、调整like匹配等),优化后再重新进行跟踪看看是否有效果,最终达到SQL的优化目的。
写到这里,基本上我常用的SQL性能优化的方式就已经讲完了,希望给大家能提供帮助。
绝对干货,转载请注明出处。原文地址