2018-12-31 16:51:09
Zookeeper 百度百科:
ZooKeeper是一个分布式应用程序的协调服务,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
ZooKeeper代码版本中,提供了分布式独享锁、选举、队列的接口
原理
其他
ZooKeeper: Because Coordinating Distributed Systems is a Zoo
ZooKeeper: A Distributed Coordination Service for Distributed Applications
Coordination services are notoriously(臭名昭著的) hard to get right. They are especially prone(易于) to errors such as race conditions and deadlock. The motivation behind ZooKeeper is to relieve distributed applications the responsibility of implementing coordination services from scratch.
ZooKeeper is simple. ZooKeeper allows distributed processes to coordinate with each other through a shared hierarchal namespace which is organized similarly to a standard file system. The name space consists of data registers - called znodes, in ZooKeeper parlance - and these are similar to files and directories. Unlike a typical file system, which is designed for storage, ZooKeeper data is kept in-memory, which means ZooKeeper can acheive high throughput and low latency numbers.(实现高吞吐量和低延迟数量)
The ZooKeeper implementation puts a premium on high performance, highly available, strictly ordered access. The performance aspects of ZooKeeper means it can be used in large, distributed systems. The reliability aspects keep it from being a single point of failure. The strict ordering means that sophisticated synchronization primitives can be implemented at the client.
ZooKeeper is replicated. Like the distributed processes it coordinates, ZooKeeper itself is intended to be replicated over a sets of hosts called an ensemble.
| ZooKeeper Service |
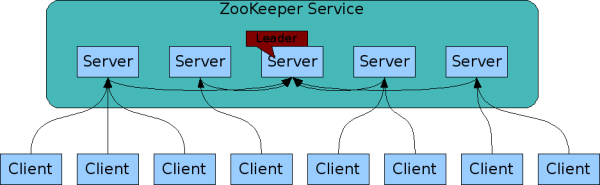 |
The servers that make up the ZooKeeper service must all know about each other. They maintain an in-memory image of state, along with a transaction logs and snapshots in a persistent store. As long as a majority of the servers are available, the ZooKeeper service will be available.
Clients connect to a single ZooKeeper server. The client maintains a TCP connection through which it sends requests, gets responses, gets watch events, and sends heart beats. If the TCP connection to the server breaks, the client will connect to a different server.
ZooKeeper is ordered. ZooKeeper stamps each update with a number that reflects the order of all ZooKeeper transactions. Subsequent operations can use the order to implement higher-level abstractions, such as synchronization primitives.
ZooKeeper is fast. It is especially fast in "read-dominant" workloads. ZooKeeper applications run on thousands of machines, and it performs best where reads are more common than writes, at ratios of around 10:1.
Nodes and ephemeral (短暂的,暂时的)nodes
Unlike is standard file systems, each node in a ZooKeeper namespace can have data associated with it as well as children. It is like having a file-system that allows a file to also be a directory. (ZooKeeper was designed to store coordination data: status information, configuration, location information, etc., so the data stored at each node is usually small, in the byte to kilobyte range.)
Znodes maintain a stat structure that includes version numbers for data changes, ACL changes, and timestamps, to allow cache validations and coordinated updates. Each time a znode's data changes, the version number increases. For instance, whenever a client retrieves(纠正) data it also receives the version of the data.
The data stored at each znode in a namespace is read and written atomically. Reads get all the data bytes associated with a znode and a write replaces all the data. Each node has an Access Control List (ACL) that restricts who can do what.
ZooKeeper also has the notion of ephemeral nodes. These znodes exists as long as the session that created the znode is active. When the session ends the znode is deleted.
Conditional updates and watches
ZooKeeper supports the concept of watches. Clients can set a watch on a znodes. A watch will be triggered(触发) and removed when the znode changes. When a watch is triggered the client receives a packet saying that the znode has changed. And if the connection between the client and one of the Zoo Keeper servers is broken, the client will receive a local notification.
| ZooKeeper Components |
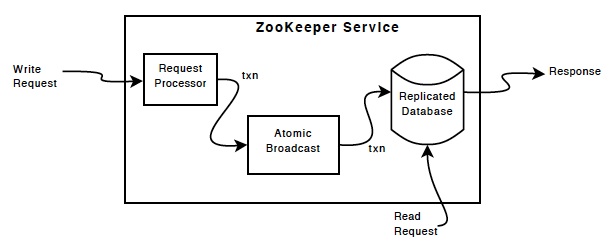 |
The replicated(复制) database is an in-memory database containing the entire data tree. Updates are logged to disk for recoverability, and writes are serialized(连载的) to disk before they are applied to the in-memory database.
Every ZooKeeper server services clients. Clients connect to exactly one server to submit irequests. Read requests are serviced from the local replica of each server database. Requests that change the state of the service, write requests, are processed by an agreement protocol.
As part of the agreement protocol all write requests from clients are forwarded to a single server, called the leader. The rest of the ZooKeeper servers, called followers, receive message proposals from the leader and agree upon message delivery. The messaging layer takes care of replacing leaders on failures and syncing followers with leaders.
ZooKeeper uses a custom atomic messaging protocol. Since the messaging layer is atomic, ZooKeeper can guarantee that the local replicas (复制)never diverge(偏离). When the leader receives a write request, it calculates what the state of the system is when the write is to be applied and transforms this into a transaction that captures this new state.
The ZooKeeper Project
ZooKeeper has been successfully used in many industrial applications. It is used at Yahoo! as the coordination and failure recovery service for Yahoo! Message Broker, which is a highly scalable publish-subscribe system managing thousands of topics for replication and data delivery. It is used by the Fetching Service for Yahoo! crawler, where it also manages failure recovery. A number of Yahoo! advertising systems also use ZooKeeper to implement reliable services.
ZooKeeper Getting Started Guide
Download
To get a ZooKeeper distribution, download a recent stable release from one of the Apache Download Mirrors.
Standalone Operation
Setting up a ZooKeeper server in standalone mode is straightforward(直接的). The server is contained in a single JAR file, so installation consists of creating a configuration.
Once you've downloaded a stable ZooKeeper release unpack it and cd to the root
To start ZooKeeper you need a configuration file. Here is a sample, create it in conf/zoo.cfg:
tickTime=2000
dataDir=/var/lib/zookeeper
clientPort=2181
This file can be called anything, but for the sake of this discussion call it conf/zoo.cfg. Change the value of dataDir to specify an existing (empty to start with) directory. Here are the meanings for each of the fields:
- tickTime(滚动时间)
-
the basic time unit in milliseconds (毫秒)used by ZooKeeper. It is used to do heartbeats and the minimum session timeout (超时)will be twice the tickTime.
- dataDir
-
the location to store the in-memory database snapshots and, unless specified otherwise(除此以外、否则), the transaction log of updates to the database.
- clientPort
-
the port to listen for client connections
Now that you created the configuration file, you can start ZooKeeper:
bin/zkServer.sh start
ZooKeeper logs messages using log4j -- more detail available in the Logging section of the Programmer's Guide. You will see log messages coming to the console (default) and/or a log file depending on the log4j configuration.
The steps outlined here run ZooKeeper in standalone mode. There is no replication, so if ZooKeeper process fails, the service will go down.
Managing ZooKeeper Storage
For long running production systems ZooKeeper storage must be managed externally(外部的) (dataDir and logs).
Connecting to ZooKeeper
$ bin/zkCli.sh -server 127.0.0.1:2181
This lets you perform simple, file-like operations.
Once you have connected, you should see something like:
Connecting to localhost:2181
log4j:WARN No appenders could be found for logger (org.apache.zookeeper.ZooKeeper).
log4j:WARN Please initialize the log4j system properly.
Welcome to ZooKeeper!
JLine support is enabled
[zkshell: 0]
From the shell, type help to get a listing of commands that can be executed from the client, as in:
[zkshell: 0] help
ZooKeeper host:port cmd args
get path [watch]
ls path [watch]
set path data [version]
delquota [-n|-b] path
quit
printwatches on|off
createpath data acl
stat path [watch]
listquota path
history
setAcl path acl
getAcl path
sync path
redo cmdno
addauth scheme auth
delete path [version]
setquota -n|-b val path
From here, you can try a few simple commands to get a feel for this simple command line interface. First, start by issuing the list command, as in ls, yielding:
[zkshell: 8] ls /
[zookeeper]
Next, create a new znode by running create /zk_test my_data. This creates a new znode and associates the string "my_data" with the node. You should see:
[zkshell: 9] create /zk_test my_data
Created /zk_test
Issue another ls / command to see what the directory looks like:
[zkshell: 11] ls /
[zookeeper, zk_test]
Notice that the zk_test directory has now been created.
Next, verify that the data was associated with the znode by running the get command, as in:
[zkshell: 12] get /zk_test
my_data
cZxid = 5
ctime = Fri Jun 05 13:57:06 PDT 2009
mZxid = 5
mtime = Fri Jun 05 13:57:06 PDT 2009
pZxid = 5
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0
dataLength = 7
numChildren = 0
We can change the data associated with zk_test by issuing the set command, as in:
[zkshell: 14] set /zk_test junk
cZxid = 5
ctime = Fri Jun 05 13:57:06 PDT 2009
mZxid = 6
mtime = Fri Jun 05 14:01:52 PDT 2009
pZxid = 5
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0
dataLength = 4
numChildren = 0
[zkshell: 15] get /zk_test
junk
cZxid = 5
ctime = Fri Jun 05 13:57:06 PDT 2009
mZxid = 6
mtime = Fri Jun 05 14:01:52 PDT 2009
pZxid = 5
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0
dataLength = 4
numChildren = 0
(Notice we did a get after setting the data and it did, indeed, change.
Finally, let's delete the node by issuing:
[zkshell: 16] delete /zk_test [zkshell: 17] ls / [zookeeper] [zkshell: 18]
That's it for now.
Running Replicated ZooKeeper
Running ZooKeeper in standalone mode is convenient for evaluation, some development, and testing. But in production, you should run ZooKeeper in replicated mode. A replicated group of servers in the same application is called a quorum(Zookeeper集群), and in replicated mode, all servers in the quorum have copies of the same configuration file.(Zookeeper集群中的每台服务器上的zookeeper配置文件都是一样的,实现一样的功能,为了同步)
For replicated mode, a minimum of three servers are required, and it is strongly recommended that you have an odd number of servers(奇数台服务器,为了选leader). If you only have two servers, then you are in a situation where if one of them fails, there are not enough machines to form a majority quorum. Two servers is inherently(本质上) less stable than a single server, because there are two single points of failure.
The required conf/zoo.cfg file for replicated mode is similar to the one used in standalone mode, but with a few differences. Here is an example:
tickTime=2000(滚动时间) dataDir=/var/lib/zookeeper clientPort=2181 initLimit=5(连接超时时间) syncLimit=2(同步时间) server.1=zoo1:2888:3888 server.2=zoo2:2888:3888 server.3=zoo3:2888:3888
The new entry, initLimit is timeouts ZooKeeper uses to limit the length of time the ZooKeeper servers in quorum have to connect to a leader. The entry syncLimit limits how far out of date a server can be from a leader.
With both of these timeouts, you specify the unit of time using tickTime. In this example, the timeout for initLimit is 5 ticks at 2000 milleseconds a tick, or 10 seconds.
(1毫秒=0.001秒,1000毫秒=1秒)
Finally, note the two port numbers after each server name: " 2888" and "3888". Peers use the former port to connect to other peers. Such a connection is necessary so that peers can communicate, for example, to agree upon the order of updates. More specifically, a ZooKeeper server uses this port to connect followers to the leader. When a new leader arises, a follower opens a TCP connection to the leader using this port. Because the default leader election also uses TCP, we currently require another port for leader election. This is the second port in the server entry.
If you want to test multiple servers on a single machine, specify the servername as localhost with unique quorum & leader election ports (i.e. 2888:3888, 2889:3889, 2890:3890 in the example above) for each server.X in that server's config file. Of course separate dataDirs and distinct clientPorts are also necessary (in the above replicated example, running on a single localhost, you would still have three config files).
Please be aware that setting up multiple servers on a single machine will not create any redundancy(多余). If something were to happen which caused the machine to die, all of the zookeeper servers would be offline. Full redundancy requires that each server have its own machine. It must be a completely separate physical server. Multiple virtual machines on the same physical host are still vulnerable to the complete failure of that host.
Other Optimizations
There are a couple of other configuration parameters that can greatly increase performance:
-
To get low latencies on updates it is important to have a dedicated (专用的)transaction log directory. By default transaction logs are put in the same directory as the data snapshots and myid file. The dataLogDir parameters indicates a different directory to use for the transaction logs.
- CSDN博客:转自 https://blog.csdn.net/qq_15300683/article/details/80375922
Zookeeper到底能做什么
Zookeeper是针对大型分布式系统的高可靠的协调系统。由这个定义我们知道zookeeper是个协调系统,作用的对象是分布式系统。
zookeeper的实际运用场景:
场景一:有一组服务器向客户端提供某种服务(例如:我前面做的分布式网站的服务端,就是由四台服务器组成的集群,向前端集群提供服务),我们希望客户端每次请求服务端都可以找到服务端集群中某一台服务器,这样服务端就可以向客户端提供客户端所需的服务。对于这种场景,我们的程序中一定有一份这组服务器的列表,每次客户端请求时候,都是从这份列表里读取这份服务器列表。那么这分列表显然不能存储在一台单节点的服务器上,否则这个节点挂掉了,整个集群都会发生故障,我们希望这份列表时高可用的。高可用的解决方案是:这份列表是分布式存储的,它是由存储这份列表的服务器共同管理的,如果存储列表里的某台服务器坏掉了,其他服务器马上可以替代坏掉的服务器,并且可以把坏掉的服务器从列表里删除掉,让故障服务器退出整个集群的运行,而这一切的操作又不会由故障的服务器来操作,而是集群里正常的服务器来完成。这是一种主动的分布式数据结构,能够在外部情况发生变化时候主动修改数据项状态的数据机构。Zookeeper框架提供了这种服务。这种服务名字就是:统一命名服务,它和javaEE里的JNDI服务很像。
场景二:分布式锁服务。当分布式系统操作数据,例如:读取数据、分析数据、最后修改数据。在分布式系统里这些操作可能会分散到集群里不同的节点上,那么这时候就存在数据操作过程中一致性的问题,如果不一致,我们将会得到一个错误的运算结果,在单一进程的程序里,一致性的问题很好解决,但是到了分布式系统就比较困难,因为分布式系统里不同服务器的运算都是在独立的进程里,运算的中间结果和过程还要通过网络进行传递,那么想做到数据操作一致性要困难的多。Zookeeper提供了一个锁服务解决了这样的问题,能让我们在做分布式数据运算时候,保证数据操作的一致性。
场景三:配置管理。在分布式系统里,我们会把一个服务应用分别部署到n台服务器上,这些服务器的配置文件是相同的(例如:我设计的分布式网站框架里,服务端就有4台服务器,4台服务器上的程序都是一样,配置文件都是一样),如果配置文件的配置选项发生变化,那么我们就得一个个去改这些配置文件,如果我们需要改的服务器比较少,这些操作还不是太麻烦,如果我们分布式的服务器特别多,比如某些大型互联网公司的hadoop集群有数千台服务器,那么更改配置选项就是一件麻烦而且危险的事情。这时候zookeeper就可以派上用场了,我们可以把zookeeper当成一个高可用的配置存储器,把这样的事情交给zookeeper进行管理,我们将集群的配置文件拷贝到zookeeper的文件系统的某个节点上,然后用zookeeper监控所有分布式系统里配置文件的状态,一旦发现有配置文件发生了变化,每台服务器都会收到zookeeper的通知,让每台服务器同步zookeeper里的配置文件,zookeeper服务也会保证同步操作原子性,确保每个服务器的配置文件都能被正确的更新。
场景四:为分布式系统提供故障修复的功能。集群管理是很困难的,在分布式系统里加入了zookeeper服务,能让我们很容易的对集群进行管理。集群管理最麻烦的事情就是节点故障管理,zookeeper可以让集群选出一个健康的节点作为master,master节点会知道当前集群的每台服务器的运行状况,一旦某个节点发生故障,master会把这个情况通知给集群其他服务器,从而重新分配不同节点的计算任务。Zookeeper不仅可以发现故障,也会对有故障的服务器进行甄别,看故障服务器是什么样的故障,如果该故障可以修复,zookeeper可以自动修复或者告诉系统管理员错误的原因让管理员迅速定位问题,修复节点的故障。大家也许还会有个疑问,master故障了,那怎么办了?zookeeper也考虑到了这点,zookeeper内部有一个“选举领导者的算法”,master可以动态选择,当master故障时候,zookeeper能马上选出新的master对集群进行管理。