本文来自公众号“AI大道理”。
正所谓巧妇难为无米之炊。
对于语音识别任务来说,对于Kaldi来说,数据就是这个米。
在进行特征提取、模型训练之前,首先要做的就是数据准备。
以最简单的YesNo为例。
1 YesNo实例结构
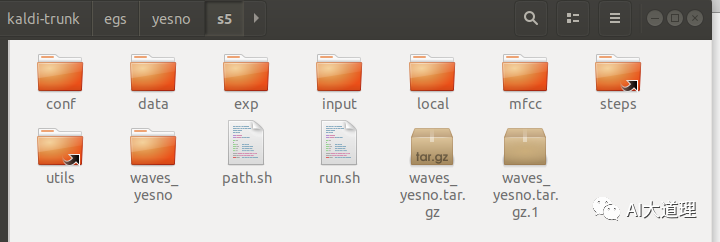
![]()
其中:
文件夹
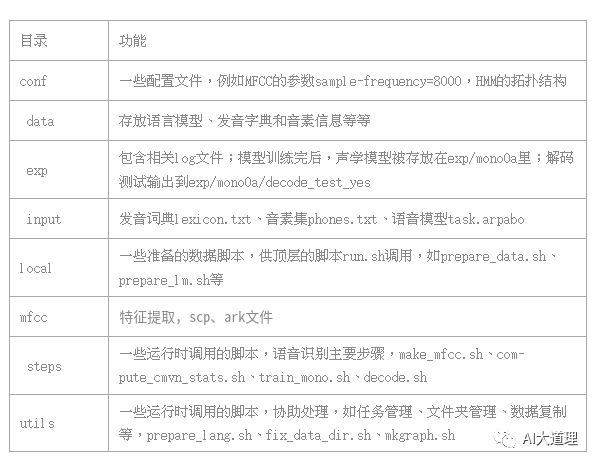
![]()
脚本
![]()
2 脚本解析
cmd.sh
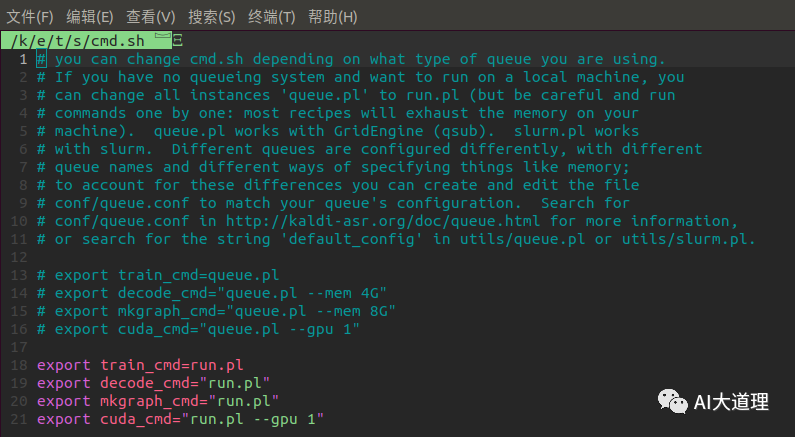
![]()
源码解读:
这里的queue.pl为kaldi调用的gridengine,是一种多cpu(gpu)的一种并行处理的方案。
如果是slurm其他并行任务分发软件配合,则是slurm.pl。
将原来的queue.pl改为run.pl ,表示是在单机运行。
这里的都是调用的utils/run.pl。
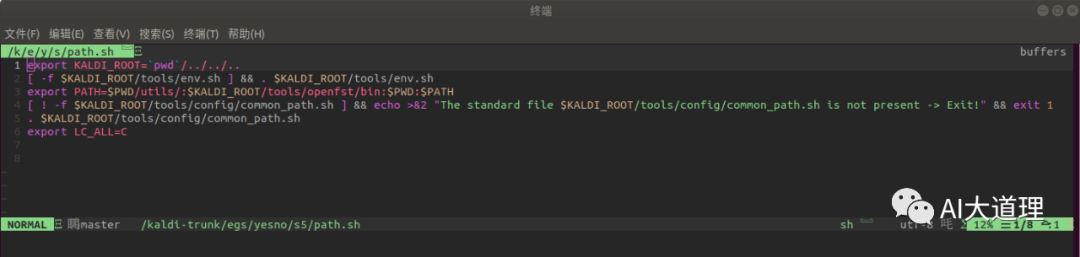
path.sh
![]()
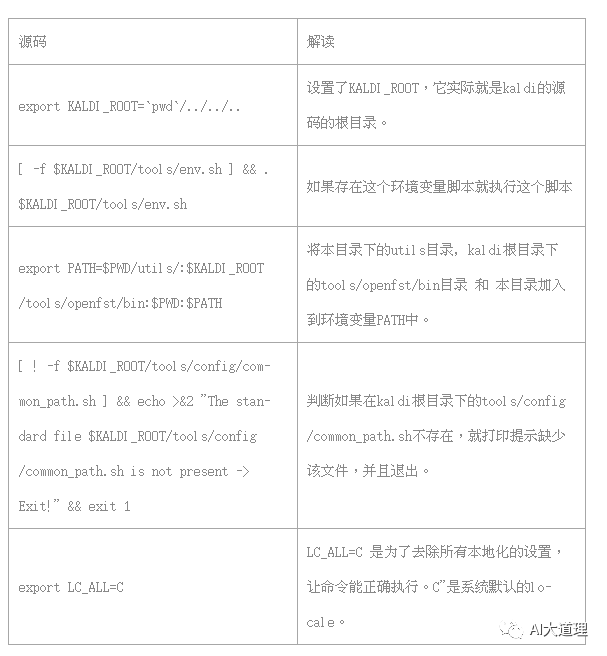
源码解读:
![]()
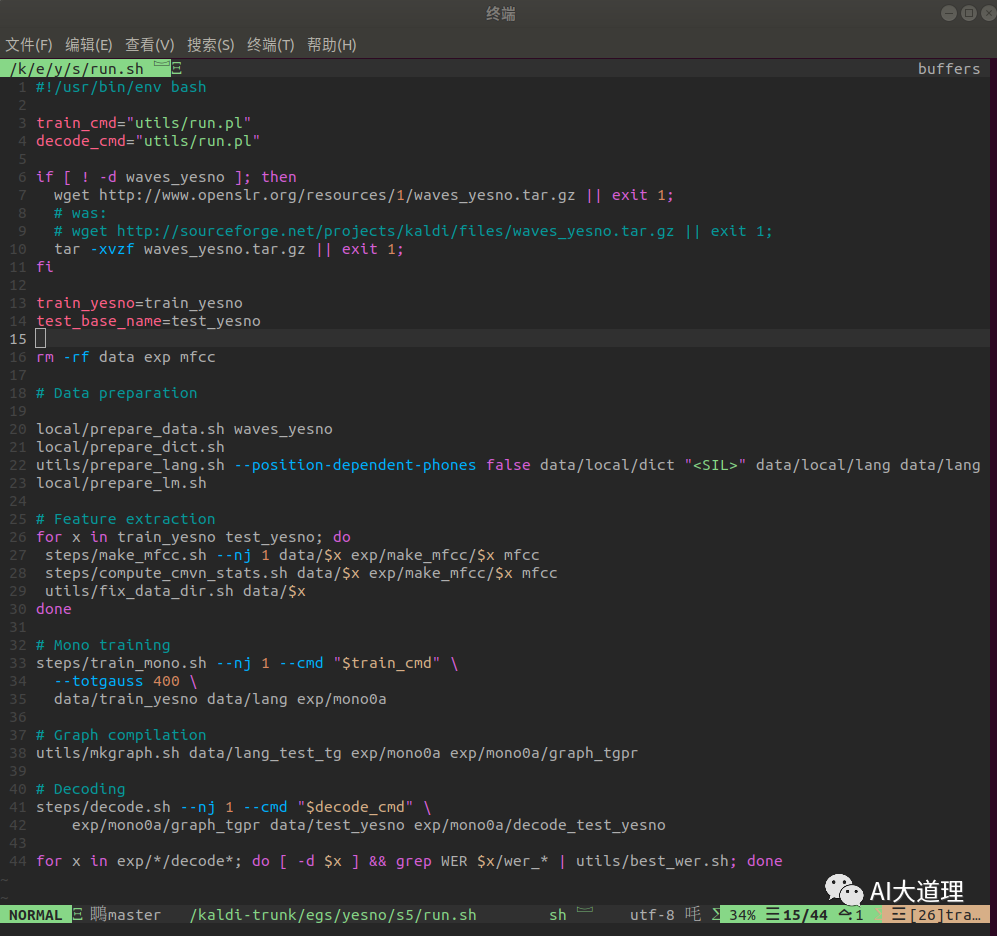
run.sh
![]()
run.sh 步骤:
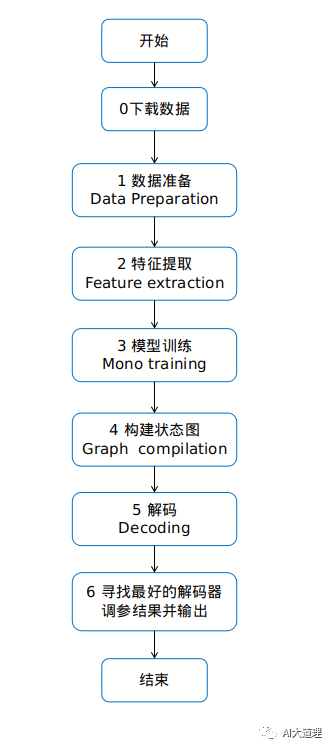
![]()
0 下载数据

![]()
源码解读:
if .....fi类似if....endif。
如果不存在 waves_yesno这个文件夹,then用wget 下载安装包,tar -xvzf 进行解压。
rm -rf data exp mfcc 删除这些文件夹如果存在的话,因为后面会再产生。
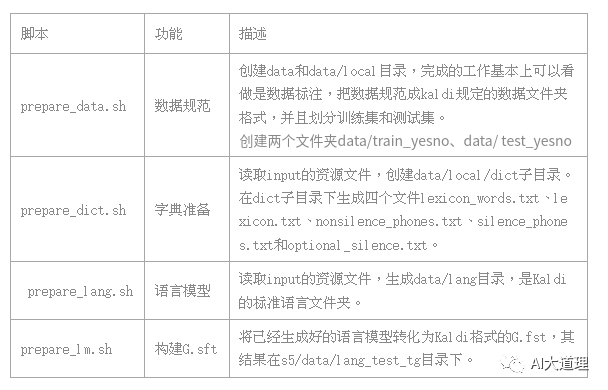
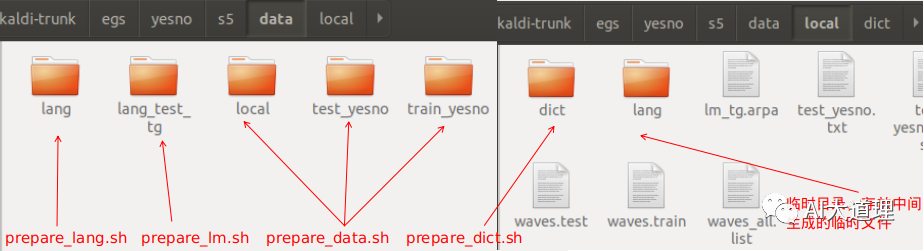
3 数据准备
步骤1 数据准备

![]()
![]()
![]()
4 数据规范
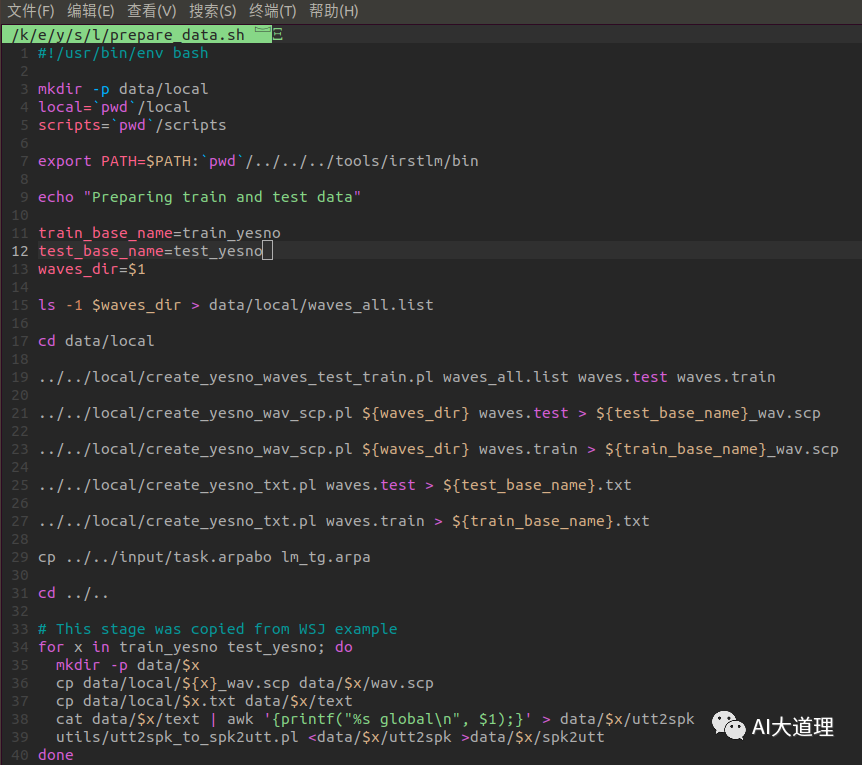
1.1 prepare_data.sh
功能:
下载完数据集后,将数据集划分为31个训练,30个测试。
在s5/下创建data文件夹,并创建data/train_yesno和data/test_yesno两个目录。
把划分好的音频文件放入train_yesno和test_yesno。
源码:
![]()
源码解析:

![]()
结果:
data目录下的数据准备完毕。
data下有三个目录,local、test_yesno和train_yesno。
Kaldi使用以下几个文件来表示数据:
1. Text 音频的文本记录。
每一个音频文件一行,一般用不带扩展名的文件名表示。
utt_id在wav.scp文件中与具体的文件映射。
2. wav.scp 将文件映射到唯一的utt_id。
第二个参数既可以是对应utt_id的音频文件路径,也可以是能够获得音频文件的指令。
3. utt2spk 对于每一个音频文件,标记是哪一个人发音的。
因为yesno数据集中只有一个发音者,用global来表示所有的utt_id文件内每一行的发音者。

![]()
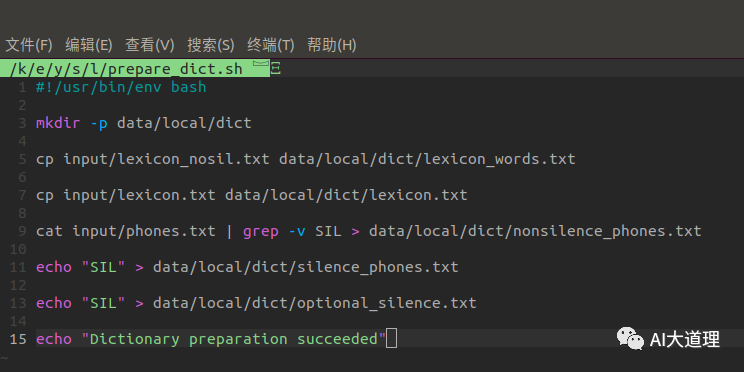
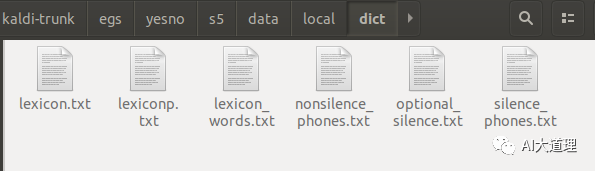
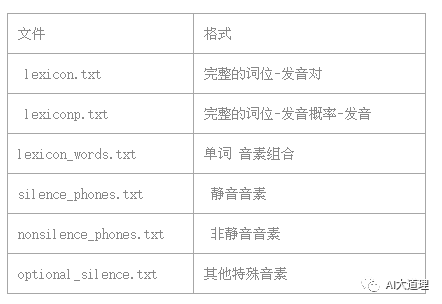
5 字典准备
1.2 prepare_dict.sh
功能:
在data/local目录下创建dict子目录。
在dict子目录下生成字典相关文件。
源码:
![]()
源码解析:

![]()
结果:
![]()

![]()
![]()
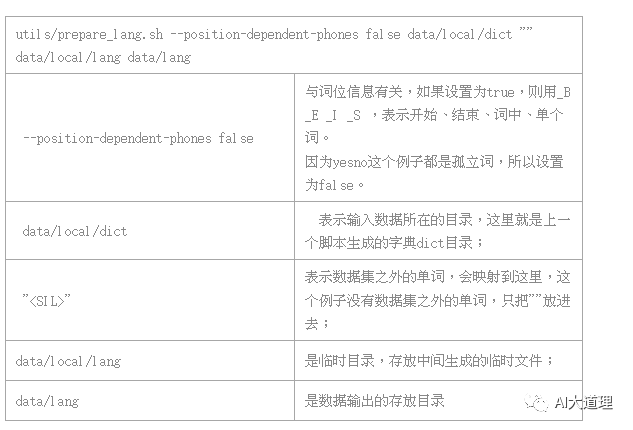
6 语言模型准备
1.3 prepare_lang.sh
功能:
读取input的资源文件,生成data/lang目录,是Kaldi的标准语言文件夹。
源码:

![]()
(源码567行,就不一一解析了)
命令行解析:
![]()
结果:
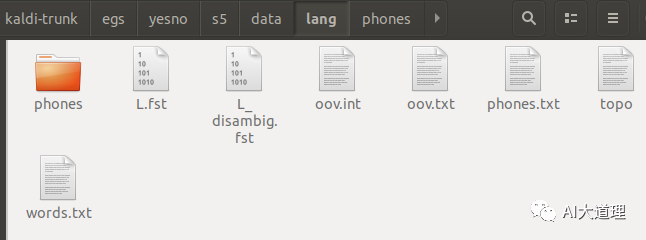
![]()

![]()
其中:
phone.txt:
存储了 音素与整数的映射

![]()
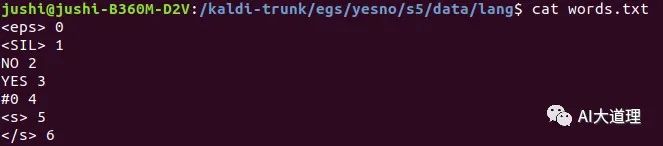
words.txt:
单词与整数的映射。
![]()
从这里就可以看出 数据准备阶段一开始数据结构与FST格式的不同。
L.fst:
这是一个 fst 格式的发音词典,输入是音素,而输出是词。
利用命令:fstprint --isymbols=words.txt L.fst L.txt
可以将将二进制 fst 转化为 text进行查看

![]()
利用命令: fstdraw --isymbols=words.txt L.fst | dot -Tps > L.ps
可以转化为L.ps进行查看

![]()
L_disambig.fst:
这也是一个 fst 格式的发音词典,只是在这个文件当中,添加了消除歧义的符号,比如#1,#2,以及自循环符号 #0。
利用命令:fstprint --isymbols=words.txt L_disambig.fst L_disambig.txt
可以将将二进制 fst 转化为 text进行查看

![]()
利用命令: fstdraw --isymbols=words.txt L_disambig.fst | dot -Tps > L_disambig.ps
可以转化为L_disambig.ps进行查看

![]()
oov.txt :
这个文件里面存储了一些符号,所有ooV词(词表之外的词,out of vocabulary)都会被映射为这个符号。
topo:
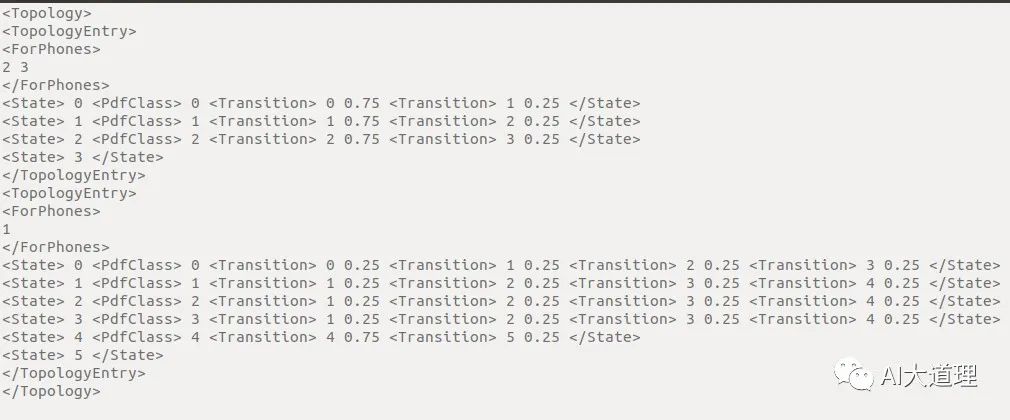
![]()
这个文件里面存储了我们后将要用到的HMM模型的拓扑模型,可以看到有两部分。
第一部分之间的数字是2,3,是发音的编号指的是YES,NO,这个可以从 phones.txt 找到。
下面一部分 的数字 1 指的是SIL。
YES,NO 有3种状态,SIL有五种状态。
它们各自状态之间的转移以及转移概率则是每一行 state probability 指定。
phones/*:
phones目录描述音素的相关属性。

![]()
7 构造G.fst
1.4 prepare_lm.sh
功能:
将已经生成好的语言模型转化为Kaldi格式的G.fst,其结果在s5/data/lang_test_tg目录下。
源码:
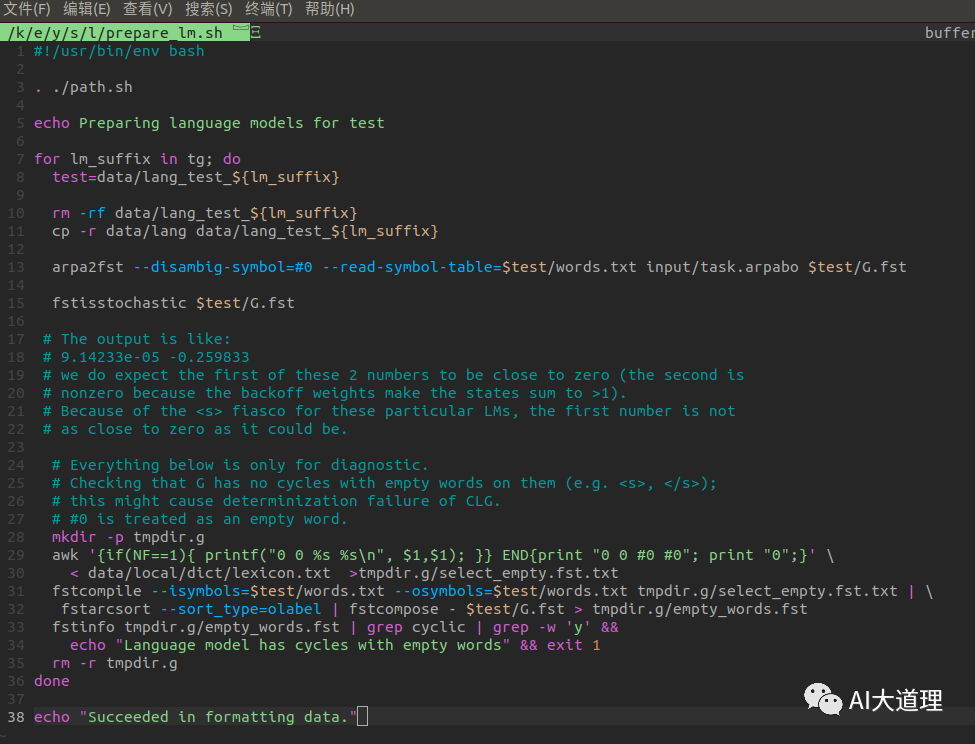
![]()
源码解析:
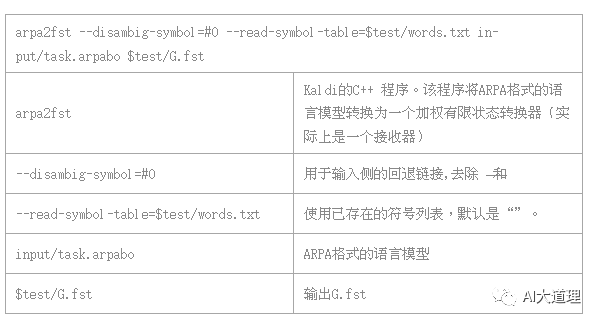
![]()
words.txt内容:

![]()
ARPA是常用的语言模型存储格式,由主要由模型文件头和模型文件体构成。
(词组前面的数字:概率,词组后面的数据,回退权值)
yesno的模型input/task.arpabo:

![]()
结果:
通过arpa2fst转换的G.fst 通过fstprint函数可以看到结果:

![]()
对于fst,其打印结果,一行一般有5列,一行对应一个弧。
第一列和第二列,表示这个弧的起始状态和终止状态。
第三列和第四列,表示输入和输出。
第五列是权重。
8 总结
至此数据准备阶段完成了。
进入data目录会看到下面的文件夹。
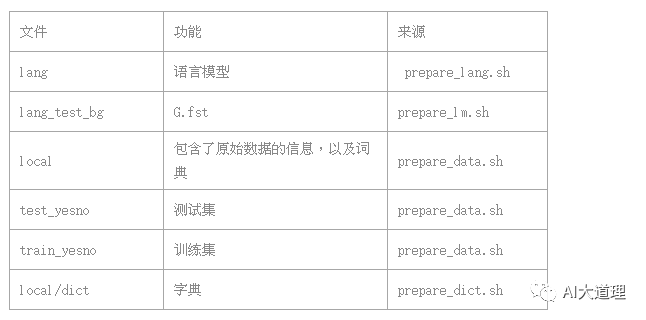
![]()
万事俱备只欠MFCC特征提取。

![]()
下期预告
AIBigKaldi(四)| Kaldi特征提取
往期精选
AI大语音(十四)——区分性训练
AI大语音(十三)——DNN-HMM
AI大语音(十二)——WFST解码器(下)
AI大语音(十一)——WFST解码器(上)
AI大语音(十)——N-gram语言模型
AI大语音(九)——基于GMM-HMM的连续语音识别系统
AI大语音(八)——GMM-HMM声学模型
AI大语音(七)——基于GMM的0-9语音识别系统
AI大语音(六)——混合高斯模型(GMM)
AI大语音(五)——隐马尔科夫模型(HMM)
AI大语音(四)——MFCC特征提取
AI大语音(三)——傅里叶变换家族
AI大语音(二)——语音预处理
AI大语音(一)——语音识别基础
——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————

![]()

![]()
—————————————————————