1.模块的循环导入
#1.当变量定义在导入模块后面


#run.py import m1 m1.func1() #m1.py print('加载m1模块') from m2 import y x=1 #m2.py print('加载m2模块') from m1 import x y=2
运行run,py文件,根据导入模块的三个步骤,run.py文件先import导入m1模块,此时在run的名称空间中产生m1模块的名字,然后在执行m1模块(文件)中的代码,首先打印"加载m1模块",遇到语句from m2 import y,将m2模块的名字丢到m1的名称空间,然后执行m2中的内容,发现m2又调用了m1,但是此时内存中已经存在m1模块了,于是遵循模块的搜索路径原则:内存>内置>sys.path,在m2中导入的是内存中的m1模块,内存中的模块m1,由于还没有运行到x=2这个语句,所以名称空间中不存在x这个名字,于是程序就会报错,报错信息是:ImportError: cannot import name 'x'。
#2.把变量定义在导入模块之前
#run.py import m1 #m1.py print('加载m1模块') x=1 from m2 import y #m2.py print('加载m2模块') y=2 from m1 import x
运行run,py文件,根据导入模块的三个步骤,run.py文件先import导入m1模块,此时在run的名称空间中产生m1模块的名字,然后在执行m1模块(文件)中的代码,首先打印"加载m1模块",将变量x的名字以及值1的内存地址存在名称空间中遇到语句from m2 import y,将m2模块的名字丢到m1的名称空间,然后执行m2中的内容,发现m2又调用了m1,但是此时内存中已经存在m1模块了,于是遵循模块的搜索路径原则:内存>内置>sys.path,在m2中导入的是内存中的m1模块,然后将变量y与2的值的内存地址丢到m2中的名称空间。结果为:
加载m1模块
加载m2模块
#将导入模块的语句写在自定义函数中
#run.py import m1 m1.func1() #m1.py print('正在导入m1') def func1(): from m2 import y, func2 print('来自与m2的y: ', y) func2() x = 'm1' #m2.py print('正在导入m2') def func2(): from m1 import x print('来自m1的x: ', x) y = 'm2'
运行run,py文件,根据导入模块的三个步骤,run.py文件先import导入m1模块,此时在run的名称空间中产生m1模块的名字,然后在执行m1模块(文件)中的代码,首先打印"正在导入m1",将函数名func1丢进m1的名称空间中与函数func的内存地址对应,将x进m1的名称空间中,与'm1'的内存地址对应,然后run.py中调用m1中的func函数,导入m2模块,在m1的名称空间中产生m2模块的名字,然后在执行m2模块(文件)中的代码,打印"正在导入m1",将函数名func2丢进m2的名称空间中与函数func的内存地址对应,然后将变量y与'm2'的内存地址丢到m2中的名称空间,在m1的名称空间产生 y,func2,分别对应m2名称空间中'm2'的内存地址,func2函数的内存地址,打印"来自与m2的y,m2",执行m2中的func2函数,发现又有导入语句,但是此时m1以及在内存中被导入了,所以取内存中的m1模块,答应“来自m1的x,m1”。
结果为:
正在导入m1
正在导入m2
来自与m2的y: m2
来自m1的x: m1
总结:我们要避免类似第一种情况的模块循环导入,可以使用第二种和第三种的方式解决这模块的循环导入的问题。
2.包
包的定义:包就是一个含有__init__.py文件的文件夹
为何要用包:包中存的是不同的自定义模块,包的作用是对不同功能的自定义模块进行分类,方便模块设计者能快速的找到自定义模块,进行增加功能等操作。
注意:1. 在python3中,即使包下没有__init__.py文件,import 包仍然不会报错,而在python2中,包下一定要有该文件,否则import 包报错。
2. 创建包的目的不是为了运行,而是被导入使用,记住,包只是模块的一种形式而已,包的本质就是一种模块。
3.包以及包中所含的模块都是用来被导入的,而不是直接被执行,环境变量都是以执行文件的环境变量(sys.path)为准。
3.json & pickle
序列化:序列化就是将内存中的 数据类型转换成另外一种格式
即(以字典为例):
字典---------序列化--------->其他的格式--------------->存到硬盘
硬盘---------读取--------->其他的格式--------反序列化------->字典
为什么要序列化?
1.持久保存程序的运行状态
2.数据的跨平台使用
json 与pickle各自的优缺点
json :
优点:这种格式是一种通用的格式,所有编程语言都能识别。
缺点:不是识别所有python类型
强调:json格式不能识别单引号
pickle:
优点:能识别所有的python类型
缺点:只能被python这门编程语言识别
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:
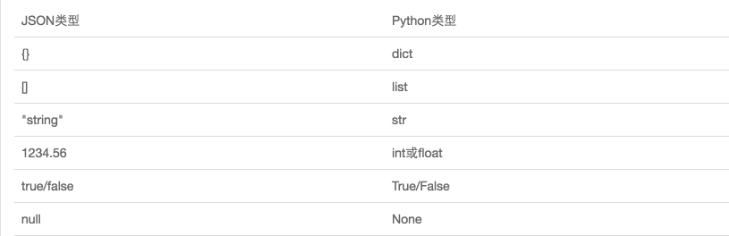
如何使用:
dump 和 load:
import json dic={'k1':10,'k2':'egon','k3':5.5,'k4':[1,2,3]} #序列化+持久化 with open('a.json','wt',encoding='utf8')as f: json.dump(dic,f) #反序列化 with open('a.json','rt',encoding='utf8')as f: json_dic=json.load(f) print(json_dic)
import pickle dic={'k1':10,'k2':'egon','k3':5.5,'k4':{1,2,3}} #序列化+持久化 with open('a.pkl','wb')as f: pickle.dump(dic,f) #反序列化 with open('a.pkl','rb')as f: pkl_dic=pickle.load(f) print(pkl_dic)
dumps 和 loads:
import json dic={'k1':True,'k2':10,'k3':'egon','k4':'你好啊',} dic_json=json.dumps(dic) # print(dic_json) with open('a.json',mode='wt',encoding='utf8') as f: f.write(dic_json) import json with open('a.json',mode='rt',encoding='utf8') as f: s_json=f.read() s=json.loads(s_json) print(s,type(s))
dic_pkl=pickle.dumps({1,2,3,4})
# print(dic_pkl)
with open('b.pkl',mode='wb') as f:
f.write(dic_pkl)
with open('b.pkl',mode='rb') as f:
s_pkl=f.read()
s=pickle.loads(s_pkl)
print(type(s))
4.time 与 datetime 模块
在Python中,通常有这几种方式来表示时间:
- 时间戳(timestamp):通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
- 格式化的时间字符串(Format String)
- 结构化的时间(struct_time):struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天,夏令时)
import time #--------------------------我们先以当前时间为准,让大家快速认识三种形式的时间 print(time.time()) # 时间戳:1487130156.419527 print(time.strftime("%Y-%m-%d %X")) #格式化的时间字符串:'2017-02-15 11:40:53' print(time.localtime()) #本地时区的struct_time print(time.gmtime()) #UTC时区的struct_time
%a Locale’s abbreviated weekday name. %A Locale’s full weekday name. %b Locale’s abbreviated month name. %B Locale’s full month name. %c Locale’s appropriate date and time representation. %d Day of the month as a decimal number [01,31]. %H Hour (24-hour clock) as a decimal number [00,23]. %I Hour (12-hour clock) as a decimal number [01,12]. %j Day of the year as a decimal number [001,366]. %m Month as a decimal number [01,12]. %M Minute as a decimal number [00,59]. %p Locale’s equivalent of either AM or PM. (1) %S Second as a decimal number [00,61]. (2) %U Week number of the year (Sunday as the first day of the week) as a decimal number [00,53]. All days in a new year preceding the first Sunday are considered to be in week 0. (3) %w Weekday as a decimal number [0(Sunday),6]. %W Week number of the year (Monday as the first day of the week) as a decimal number [00,53]. All days in a new year preceding the first Monday are considered to be in week 0. (3) %x Locale’s appropriate date representation. %X Locale’s appropriate time representation. %y Year without century as a decimal number [00,99]. %Y Year with century as a decimal number. %z Time zone offset indicating a positive or negative time difference from UTC/GMT of the form +HHMM or -HHMM, where H represents decimal hour digits and M represents decimal minute digits [-23:59, +23:59]. %Z Time zone name (no characters if no time zone exists). %% A literal '%' character. 格式化字符串的时间格式
其中计算机认识的时间只能是'时间戳'格式,而程序员可处理的或者说人类能看懂的时间有: '格式化的时间字符串','结构化的时间' ,于是有了下图的转换关系
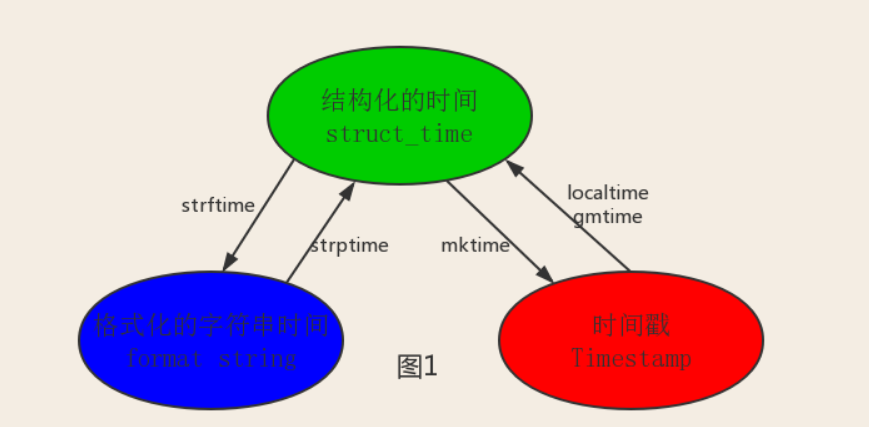
#--------------------------按图1转换时间 # localtime([secs]) # 将一个时间戳转换为当前时区的struct_time。secs参数未提供,则以当前时间为准。 time.localtime() time.localtime(1473525444.037215) # gmtime([secs]) 和localtime()方法类似,gmtime()方法是将一个时间戳转换为UTC时区(0时区)的struct_time。 # mktime(t) : 将一个struct_time转化为时间戳。 print(time.mktime(time.localtime()))#1473525749.0 # strftime(format[, t]) : 把一个代表时间的元组或者struct_time(如由time.localtime()和 # time.gmtime()返回)转化为格式化的时间字符串。如果t未指定,将传入time.localtime()。如果元组中任何一个 # 元素越界,ValueError的错误将会被抛出。 print(time.strftime("%Y-%m-%d %X", time.localtime()))#2016-09-11 00:49:56 # time.strptime(string[, format]) # 把一个格式化时间字符串转化为struct_time。实际上它和strftime()是逆操作。 print(time.strptime('2011-05-05 16:37:06', '%Y-%m-%d %X')) #time.struct_time(tm_year=2011, tm_mon=5, tm_mday=5, tm_hour=16, tm_min=37, tm_sec=6, # tm_wday=3, tm_yday=125, tm_isdst=-1) #在这个函数中,format默认为:"%a %b %d %H:%M:%S %Y"。
#时间加减 import datetime # print(datetime.datetime.now()) #返回 2016-08-19 12:47:03.941925 #print(datetime.date.fromtimestamp(time.time()) ) # 时间戳直接转成日期格式 2016-08-19 # print(datetime.datetime.now() ) # print(datetime.datetime.now() + datetime.timedelta(3)) #当前时间+3天 # print(datetime.datetime.now() + datetime.timedelta(-3)) #当前时间-3天 # print(datetime.datetime.now() + datetime.timedelta(hours=3)) #当前时间+3小时 # print(datetime.datetime.now() + datetime.timedelta(minutes=30)) #当前时间+30分 # # c_time = datetime.datetime.now() # print(c_time.replace(minute=3,hour=2)) #时间替换 datetime模块
5.random模块
import random print(random.random())#(0,1)----float 大于0且小于1之间的小数 print(random.randint(1,3)) #[1,3] 大于等于1且小于等于3之间的整数 print(random.randrange(1,3)) #[1,3) 大于等于1且小于3之间的整数 print(random.choice([1,'23',[4,5]]))#1或者23或者[4,5] print(random.sample([1,'23',[4,5]],2))#列表元素任意2个组合 print(random.uniform(1,3))#大于1小于3的小数,如1.927109612082716 item=[1,3,5,7,9] random.shuffle(item) #打乱item的顺序,相当于"洗牌" print(item)
import random def make_code(n): res='' for i in range(n): s1=chr(random.randint(65,90)) s2=str(random.randint(0,9)) res+=random.choice([s1,s2]) return res print(make_code(9)) 生成随机验证码