1.该项目的github地址:
https://github.com/514DNA/sudoku
2.各个模块耗费的时间:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
| Planning | 计划 | 0 | 0 |
| · Estimate | · 估计这个任务需要多少时间 | 0 | 0 |
| Development | 开发 | 1220 | 1530 |
| · Analysis | · 需求分析 (包括学习新技术) | 20 | 30 |
| · Design Spec | · 生成设计文档 | 0 | 0 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 0 | 0 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 0 | 0 |
| · Design | · 具体设计 | 120 | 240 |
| · Coding | · 具体编码 | 900 | 1200 |
| · Code Review | · 代码复审 | 60 | 0 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 60 |
| Reporting | 报告 | 80 | 125 |
| · Test Report | · 测试报告 | 60 | 60 |
| · Size Measurement | · 计算工作量 | 10 | 5 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 60 |
| 合计 | 1300 | 1655 |
3.解题思路描述:
需求1:由于左上,中间,右下三个大的九宫格彼此之间互不干扰,我们可以先确定这三个大的九宫格的数
初始是这种状态
1 2 3 0 0 0 0 0 0
4 5 6 0 0 0 0 0 0
7 8 9 0 0 0 0 0 0
0 0 0 1 2 3 0 0 0
0 0 0 4 5 6 0 0 0
0 0 0 7 8 9 0 0 0
0 0 0 0 0 0 1 2 3
0 0 0 0 0 0 4 5 6
0 0 0 0 0 0 7 8 9
无论这三个九宫格的数如何排列
在剩余的九宫格里面
每个数均有的64种填法
上(4)*右上(2)*左(4)*右(1)*左下(2)*下(1)
然后在64^9种组合空间中,找到一种符合数独规则的填法
里面有大量的剪枝+回溯,我之后会说
这种填法我们称为初始填法
这还没完,需求是左上角的数(学号后两位相加)% 9 + 1
我的学号是58,也就是说我的左上角的数必须是5
我们可以建立一种映射关系
5 1 2 3 4 6 7 8 9
即原来的1变成5,2变成1
为了充分利用这种关系
我们可以将后八个数进行一次全排列
一一与初始填法映射
即一次性算出40320种可能的解
之后我们算出初始状态的右下角的格子新的排列方式
即下一次右下角的九宫格是按照1 2 3 4 5 6 7 9 8的填法
如果右下角的九宫格是9 8 7 6 5 4 3 2 1
那么把右下角的格子恢复成1 2 3 4 5 6 7 8 9
然后算出初始状态的中间的格子新的排列方式
然后继续找到一个初始填法
找到40320种映射关系
输出,直到输出了N个数独终局。
这样可以快速找到大量不同的数独终局
只要初始状态左上角的格子不变,那么就永远不会组合出重复的数独终局
用这种方法可以生成9!*9!*8!,一共0.53京个不同的数独终局,超出100万个的需求的53亿倍。
需求2:解数独和生成数独不同,如果解数独靠生成数独方法,那么在庞大的解空间内找到一个合适的解会非常缓慢
所以我采取了另一种办法,就是人类解数独的方法
比如说给一个数独,我们一定会先找可以直接确定的数
比如说,在一个九宫格种,如果某个数字在其中的八个格中不是被其他数占了就是填进去会与该行或列冲突
那么,这个数字一定填在剩下的这个格中
同理,一行,一列中的数字也可以这么考虑
还有一种确定的方法,就是某一个空置小格中有八个数都不能填,那么这个格一定只能填另外一个数
如果上述几种方法均不能确定
那么我们就可以发挥计算机的长处了,那就是猜
选取一个填数的可能最小的格子,猜所有填数可能中最小的数
如果之后发现某一步无论怎么填都会不满足数独规则
那么就回退到上一次猜数的地方,然后把猜比当前猜的数稍微大一点的数
如果发现已经没有数可以猜了
那么就再倒退到上上次猜数的地方
以此类推
这样解数独的速度比暴力算法要快得多
关于需求2,我的思路是直接就想到按照人类解数独的思路写的,没有经历什么波折
重点说一下需求1
需求一我最开始的思路和需求2差不多,暴力搜索,然而这样的话生成10W就很慢了
然后我又去网上查,发现有一种不按格子填,按数字填的算法,就是先填1,再填2
这样下来比暴力搜索快一些,好歹能跑100W个数,但是需要好几十秒,后来我想了一下
为什么不一上来多确定几个数,让后面的可能性小一些
然后我想到了确定几个九宫格的数
我发现,如果两个九宫格处在同一行或者同一列,那么这一行另外的格子就有可能无解
而且第二个九宫格的确定也很不自由
后来我就想到了确定三个互不干扰的九宫格的思路
然后我又发现,确定完三个,后面六个九宫格仍然不需要暴力搜索
因为每个数形式都一样
六个格,每个格有四种可能的填法,而且相对行列关系都相同
所以每个数的64种填法也就应运而生
然后我需求一的算法就大致成型了。
4)设计实现过程。
我的代码只有个数独相关的大类,所有函数都封装在这个大类里面,这个类有这么几个函数
构建函数(创建一个数独类的时候把这个数独初始化一下)
析构函数(由于没有动态分配内存,所以析构函数暂时为空)
void data_to_back()和void back_to_data()
前者是把当前填的数放进备份区
后者是把备份区的数填入
void print_sudoku(int mode)
将当前数独中的数输出到文件中
如果mode是0,那么结尾输出两个回车
否则,结尾不输出任何字符
void print_sudoku_to_cmd()
将当前数独中的数输出到命令行中,主要用来测试
void clear_addr(int addr)
清空数独中第addr+1个数,同时恢复这个数所在的行,列,九宫格的标记
void arrange(int count)
对左上,中间,右下三个九宫格中的数找到下一种排列方式
void arrange()
默认上一个函数count为2时的重载
void loadin_super_squared()
把初始状态填入左上,中间,右下三个九宫格
void back_step()
后退一步(清空当前步骤填的数极相关信息)
int find_another_fit_array()
找到一个合适的填充上,右上,左,右,左下,右下这六个九宫格的填充方式
fill_sudoku()
将上面那个函授找到的数填入到数独中
read_soduku(FILE *fp)
从fp所指向的文件中读入数独
void solve_sudoku()
解决一个数独题
void create_sudoku(int n)
创建n个不同的数独
void create_random_sudoku()
创建一个随机数独
void solve_all_soduku(FILE *fp)
解决fp所指向的文件中的所有数独题
函数调用关系是这样的,solve_all_soduku(FILE *fp)调用solve_sudoku()
create_random_sudoku(),create_sudoku(int n),solve_sudoku()调用前面的基本函数。
create_sudoku(int n)和solve_sudoku()的表现形式就是上面思路部分需求一和需求二的解题思路
重点说一下我觉得比较精髓的一段代码
for (i = 0; i < 64; i++)
{
flag[i][0] = i / 16;
flag[i][1] = 2 + ((i >>3) &1) - ((i >>5)<<1);
flag[i][2] = (i & 0x7) >>1;
flag[i][3] = 3 - ((flag[i][1] &1) + (flag[i][2]&0xfffffffe));
flag[i][4] = (!(flag[i][2] &1)) + ((i &1)<<1);
flag[i][5] = 3 - ((flag[i][0] &1) + (flag[i][4] &0xfffffffe));
}
这个代码是用来给出一个数在初始状态之后的64种填充方式的一个模板
初始状态之后的任意一个空置的九宫格,对于任意的一个数,均只剩四个位置可以填了
我们把这四个位置中左上的格子称作0,右上的称作1,左下的称作2,右下的称作3
这种填充方式是通过自己在纸面上列举所有可能+找其中的规律填的,所以可读性比较差,后续我打算把这一段代码封装成一个宏
单步测试目前还没有写
我是通过测试各种极端数据来达到测试的目的的
比如说测试数独生成
参数输入一个1,一个3,一个100,一个1000000,如果都通过
那么参数再输入一个0,一个-1,一个1000001,一个000000,如果这些都能正常报错
那么参数再输入一个NULL,一个abc,一个123ab,一个蜥蜴,如果这些都能正常报错
我们之后就测试下面的一个需求
先测试文件读入的功能
如果传入一个不存在的文件能报错,传入一个存在的文件可以正常读取
那么之后就测试一下解数独的功能
如果给一个空数独可以正常解
一个号称世界上最难的数独可以解
一个已经填好的数独可以输出
一个空一个格子的数独可以填进去数
一个无解的数独真的可以输出无解
那么这个功能就测试完了
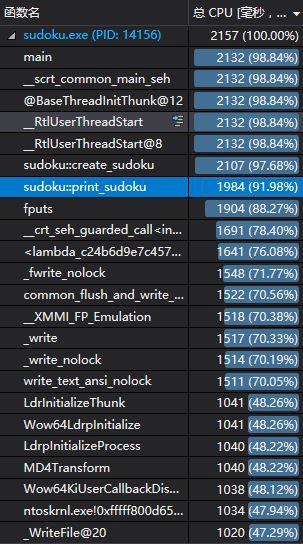
5)记录在改进程序性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS 2017的性能分析工具自动生成),并展示你程序中消耗最大的函数。
我最开始改进性能是算法层的
主要是第一个需求的算法已经是改进三遍算法的结果了
改进算法之后就是常数倍的改良了
使用位运算,合并能合并的循环体。。
到最后,生成100W个随机数独,真正的瓶颈
其实是IO部分
消耗最大的函数就是这个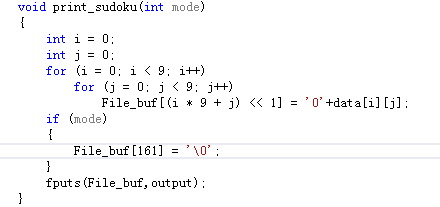
6)代码说明。展示出项目关键代码,并解释思路与注释说明。
解数独的项目代码太长,我之后文字说明
在此先放上我的创建N个数独终局的代码

创建终局,就是先加载左上,中间,右下三个九宫格的数字
然后找到一个合适的填充方式
然后把数据备份
之后就是算出40320种等价数独,并输出到文件中,如果40320大于剩余的任务量,即(N-i),那么完成任务时直接跳出
如果N>40320,那么就有机会更换初始状态,并进行下一次循环
直到输出N个数独
解数独的算法是前面说过的回溯+剪枝
主要说一下回溯是怎么实现的
我创建了两个81位的int形数组当做栈
第一个栈存储历史的进程,即每一步填数的位置
第二个栈存储猜数的节点,里面存猜数时候的步数
这样就很容易实现回溯+剪枝的功能