Set集合的理解:
类似于一个罐子,程序可以一次把多个对象”丢进“Set集合,而Set集合通常不能记住元素的添加顺序。
Set集合不允许包含相同的元素,如果试图把两个相同的元素加入同一个Set集合中,则添加操作失败,add()方法返回false,且新元素不会被加入。

HashSet具有以下特点:
- 不能保证元素的排列顺序,顺序可能与添加顺序不同,顺序也有可能发生变化;
- HashSet不是同步的,如果多个线程同时访问一个HashSet,假设有两个或者两个以上的线程同时修改了HashSet集合时,则必须通过代码保证其同步。
- 集合元素值可以为Null.
HashSet集合判断两个元素相等的标准:是两个对象通过equals()方法比较相等,并且两个对象的HashCode()方法返回值也相等。


public static void main(String[] args) { Set books=new HashSet(); //分别向books集合中添加A,B,C对象 books.add(new A()); books.add(new A()); books.add(new B()); books.add(new B()); books.add(new C()); books.add(new C()); System.out.println(books); } } //对象A只重写equeals对象 class A{ @Override public boolean equals(Object obj) { return true; } } class B{ @Override public int hashCode() { return 1; } } class C{ @Override public boolean equals(Object obj) { return true; } @Override public int hashCode() { return 2; } }
注意:当把一个对象放入HashSet中时,如果要重写该对象对应的equals()方法,则也应该重写其HashCode方法,规则:
如果两个对象通过equals()方法比较返回true,这两个对象的HashCode值也应该相等。(不然会性能下降,违背了Set集合不能重复的规则)
(2) LinkedHashSet类
HashSet还有一个子类LinkedHashSet,LinkedHashSet集合也是根据元素的HashCode值来决定元素的存储位置,
但它同时使用链表维护元素的次序,这样使得元素看起来是以插入的顺序保存的,
也就是说:当遍历LinkedHashSet集合里的元素时,LinkedHashSet将会按元素的添加顺序来访问集合里的元素,
LinkedHashSet需要维护元素的插入顺序,因此性能略低于HashSet的性能,但在迭代访问Set里的全部元素时,将有很好的性能,因此它以链表来维护内部顺序。
public static void main(String[] args) { LinkedHashSet books=new LinkedHashSet(); books.add("疯狂Java讲义"); books.add("轻量级JavaEE企业应用实战"); System.out.println(books); //删除疯狂java讲义 books.remove("疯狂Java讲义"); //重新添加疯狂Java讲义 books.add("疯狂Java讲义"); System.out.println(books); }
运行效果:

输出LinkedHashSet集合元素时,元素的顺序总是与添加的顺序一致;
LinkedHashSet使用了链表记录集合元素的添加顺序,但LinkedHashSet依然是HashSet,因此,它依然不允许集合元素重复。
(3)TreeSet类
public static void main(String[] args) { SortedSet nums=new TreeSet(); //向集合中添加四个对象 nums.add(1); nums.add(2); nums.add(3); nums.add(4); //输出集合元素,看到元素已处于排序状态 nums.stream() .forEach(num-> System.out.println(num)); //输出集合中的第一个元素 System.out.println(nums.first()); //输出集合中的最后一个元素 System.out.println(nums.last()); //返回小于3的子集,不包含3 System.out.println(nums.headSet(3)); //返回大于3的子集如果Set中包含3,则子集中包含3 System.out.println(nums.tailSet(3)); //返回大于2小于3的集合 System.out.println(nums.subSet(2,3)); }
运行结果:

总结:看起来方法很多,其实,因为TreeSet中的元素是有序的,所以增加了访问第一个元素,最后一个元素,前一个元素,后一部分元素,并提供了截取中间一部分元素的TreeSet方法。
- TreeSet并不是根据元素插入的顺序进行排序的,而是根据元素实际值的大小排序的,
- 与HashSet集合采用hash算法来决定元素存储的位置不同,TreeSet采用的是红黑树的数据结构,来存储集合元素,
- TreeSet支持两种排序方法:自然排序和定制排序,在默认情况下采用自然排序。
1,自然排序
TreeSet会调用集合中的compareTo(Object obj) 方法来比较元素之间的大小关系,然后将集合元素安升序排序,,这种方式就是自然排序。
例如:
obj1.compareTo(obj2) 如果返回0,则两个相等
如果返回一个正整数,obj1大于obj2
如果返回一个负数,则obj1小于obj2
注意:
如果试图把一个对象添加到TreeSet时,则该对象的类必须实现ComParable接口,否则程序将会抛出异常。
public static void main(String[] args) { SortedSet nums=new TreeSet(); //向集合中添加四个对象 nums.add(new AB()); nums.add(new AB());//报出异常 } } class AB{}
解析:上面程序试图向treeSet集合添加;2个AB()对象,但是添加第一个对象时,TreeSet没有任何元素,所以不会出现任何问题,但是当添加第二个AB()对象时TreeSet就就会调用该对象的compareTo(Object obj)方法
与集合中的其他元素比较--——-——如果其对应的类没有实现ComParable接口,则会引发ClassCastException异常。 添加不同类型的对象也会引发异常。由于CompareTo()方法
综上所述,如果希望treeSet能正常,TreeSet只能添加同一种类型的对象。
原因:
当把一个对象加入TreeSet集合时,TreeSet调用该对象的compareTo()方法与容器中的其他对象比较大小,然后根据红黑树结构找到它的存储位置,,如果两个对象根据TreeSet比较相等,新对象将无法添加到TreeSet集合中。
判断两个对象是否相等的标准:
两个对象通过compareTo()比较是否返回 0——如果比较返回0,TreeSet会认为他们相等,否则不相等。
2,TreeSet定制排序
(1)由来:当元素自身不具备比较性时,或者具备的比较性不是所需要的。
这时就要让集合自身具备比较性,在初始化时,就有了比较方式。
(2)步骤:
1)实现comparator接口
2)复写compare方法
3)在创建TreeSet集合对象时,提供一个一个Comparator对象,
public static void main(String[] args) { //此处Lambda表达式的目标类型是代替Comparator接口 SortedSet nums=new TreeSet((o1,o2)->{ M m1=(M)o1; M m2=(M)o2; //根据M对象的age属性来决定大小,age越大,M对象反而越小 return m1.Age>m2.Age?-1 :m1.Age<m2.Age?1:0; }); nums.add(new M(5)); nums.add(new M(-3)); nums.add(new M(9)); System.out.println(nums); } } class M{ int Age; public M(int age) { Age = age; } @Override public String toString() { return "M{" + "Age=" + Age + '}'; } }
运行结果:
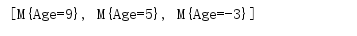
上面程序使用目标类型为Comparator的lambda表达式,他负责nums集合的排序,所以当吧M对象添加到nums集合中时,无须M类实现Comparator接口
因为此时TreeSet无须通过M对象本身来比较大小,而是使用关联的lambda表达式来负责集合元素的排序。