20199304 2019-2020-2 《网络攻防实践》 综合实践
论文题目:
Towards Evaluating the Robustness of Neural Networks
所属会议:S&P2017
作者:
Nicholas Carlini, David Wagner
University of California, Berkeley
1 实验目的
本次实践的目的是对神经网络防御性蒸馏展开攻击,证明防御性蒸馏不会显著提高神经网络的鲁棒性。通过复现论文源代码,体验攻防魅力。
1.0任务要求
四大顶会/顶级期刊论文重现与改进:
从四大安全会议挑选1篇论文,阅读并重现该论文的工作,如果能够改进可加分。具体要求如下:
-
从整体上介绍下论文的研究内容、论文的出处和作者、论文的研究方法、优缺点等。
-
具体介绍论文的研究工作。
-
通过分析该论文,请列出来与论文相关的值得研究的方向并详细介绍如何研究,给出研究思路
-
要求提供所读论文的电子版、综合实践报告、制作PPT讲解分析、录制视频、论文源代码(必须项)
-
评分根据工作量、内容分析的深刻程度、PPT和视频的质量、报告的质量等综合评定。
1.1概念
1.1.1蒸馏神经网络概念
蒸馏神经网络,是14年Hinton提出来的一个概念,其最本质的思想是来源于昆虫记里面的故事:
“蝴蝶以毛毛虫的形式吃树叶积攒能量逐渐成长,最后变换成蝴蝶这一终极形态来完成繁殖。”
虽然是同一个个体,但是在面对不同环境以及不同任务时,个体的形态却是非常不同。不同的形态是为了完成特异性的任务而产生的变化,从而使个体能够更好的适应新的环境。
比如毛毛虫的形态是为了更方便的吃树叶,积攒能量,但是为了增大活动范围提高繁殖几率,毛毛虫要变成蝴蝶来完成这样的繁殖任务。蒸馏神经网络,其本质上就是要完成一个从毛毛虫到蝴蝶的转变。
因为在使用神经网络时,训练时候的模型和实际应用的模型往往是相同的,就好像一直是一个毛毛虫,既做了吃树叶积累能量的事情,又去做繁殖这项任务,既臃肿又效率低下。
所以使用同样形态的模型,一方面会导致模型不能针对特定性的任务来快速学习,另一方面实际应用中如果也是用训练时非常庞大的模型会造成使用开销负担过重。
蒸馏神经网络想做的事情,本质上更接近于迁移学习(Transfer Learning ),当然也可从模型压缩(Model Compression)的角度取理解蒸馏神经网络。
Hinton的这篇论文严谨的数学思想推导并不复杂,但是主要是通过巧妙的实验设计来验证了蒸馏神经网络的可行性,所以本专题主要从蒸馏的思想以及实验的设计来介绍蒸馏神经网络。而本文主要介绍设计思想部分。
1.1.2蒸馏神经网络设计思想
在用神经网络训练大规模数据集时,为了处理复杂的数据分布:一种做法是建立复杂的神经网络模型,例如含有上百层的残差网络,这种复杂的网络往往含有多达几百万个参数;
另一种做法往往会混合多种模型,将几个大规模的神经网络在同一个数据集上训练好,然后综合(ensemble)多个模型,得到最终的分类结果。
但是这种复杂模型,一是在新的场景下重新训练成本过高,二是由于模型过于庞大而难以大规模部署(deployment)。
所以,最基本的想法就是将大模型学习出来的知识作为先验,将先验知识传递到小规模的神经网络中,之后实际应用中部署小规模的神经网络。这样做有三点依据:
- (1)大规模神经网络得到的类别预测包含了数据结构间的相似性;
- (2)有了先验的小规模神经网络只需要很少的新场景数据就能够收敛;
- (3)Softmax函数随着温度变量(temperature)的升高分布更均匀。
1.2 环境介绍
1.2.1实验语言
Python
Python是一种跨平台的计算机程序设计语言。 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越多被用于独立的、大型项目的开发。
作为一种解释型脚本语言,Python可以应用于以下领域:
- (1)Web 和 Internet开发
- (2)科学计算和统计
- (3)人工智能
- (4)桌面界面开发
- (5)软件开发
- (6)后端开发
- (7)网络爬虫等
1.2.2实验平台
PyCharm
PyCharm是一种Python IDE,带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制。此外,该IDE提供了一些高级功能,以用于支持Django框架下的专业Web开发。
PyCharm是由JetBrains打造的一款Python IDE,VS2010的重构插件Resharper就是出自JetBrains之手。
同时支持Google App Engine,PyCharm支持IronPython。这些功能在先进代码分析程序的支持下,使 PyCharm 成为 Python 专业开发人员和刚起步人员使用的有力工具。
PyCharm拥有一般IDE具备的功能,比如, 调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制
另外,PyCharm还提供了一些很好的功能用于Django开发,同时支持Google App Engine,IronPython。
2 实验内容及实验原理
本次实践所依据的论文是《Towards Evaluating the Robustness of Neural Networks》,本篇论文的原作者是Nicholas Carlini和David Wagner,他们在2017年IEEE安全与隐私研讨会上发表了此片论文论文。这是关于对抗样本 (Adversarial Example) 的 paper,主要贡献是提出了 Carlini & Wagner Attack 神经网络有目标攻击算法,打破了最近提出的神经网络防御性蒸馏(Defensive Distillation),证明防御性蒸馏不会显著提高神经网络的鲁棒性,论文的信息量还是比较大的。
2.1对抗样本 (Adversarial Example)
2.1.1Basic Idea
通过故意对数据集中输入样例添加难以察觉的摄动使模型以高置信度给出一个错误的输出。即只需要在一张图片上做微小的扰动,(神经网络) 分类器以很高的置信度将图片错误分类,甚至被分类成一个指定的标签(不是图片正确所属的标签)。

这类问题可以表述为一个约束最小化问题:
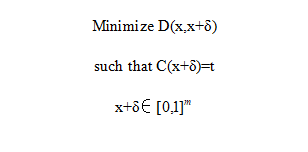
其中:
x∈R^m 是干净图片向量。
δ∈R^m 是被加入到图片的扰动。
D(.) 是距离度量。
t 是攻击的目标标签。
C(.) 是深度神经网络分类器。
[0,1]^m 用于限制扰动后值的范围。
对于距离度量而言,Lp 距离常常被写作||x−x′||p,其 p 范数被定义为:
||v||p=(∑i=1n|vi|p)1p
具体而言:
L0 距离度量的是 xi≠x′i 的坐标 i 的数量,其对应的是图像中被改变的像素的数量。
L2 距离度量的是 xi 和 x′i 之间的欧式距离,当许多像素发生小变化时,L2 依据可以保持较小。
L∞ 距离度量的是 xi 和 x′i 之间最大的绝对距离即||x−x′||∞=max(|x1−x′1|,...,|xn−x′n|),每个像素可以被改变到这个极限。
2.1.2 目标函数(Objective Function)
由于该目标函数一个高度非线性的函数,现有算法很难直接求解上述公式,往往通过将其表述为一个适当的优化公式来解决,而这个优化公式可以通过现有的优化算法来解决。论文定义了新的目标函数 f,使得 f(x+δ)≤0 当且仅当 C(x+δ)=t 成立,论文探索了公式的空间,并根据经验确定哪些公式可以导致最有效的攻击,提出了七个目标函数,公式如下(附上个人理解,所有的目标函数似乎都有大于等于 0 的约束):
f1(x′)=−lossF,t(x′)+1,对目标标签的损失函数进行优化,这个目标函数和 L-BFGS Attack 相类似。
f2(x′)=(maxi≠t(F(x′)i)−F(x′)t)+,对目标标签的置信度进行优化,希望其成为最后预测值。
f3(x′)=softplus(maxi≠t(F(x′)i)−F(x′)t)−log(2), 也是对目标标签的置信度进行优化,形式不同。
f4(x′)=(0.5−F(x′)t)+,也是对目标标签的置信度进行优化,希望其成为最大可能类。
f5(x′)=−log(2F(x′)t−2),同 f4。
f6(x′)=(maxi≠t(Z(x′)i)−Z(x′)t)+,对目标标签的 logit 值进行优化。同 f2.
f7(x′)=softplus(maxi≠t(Z(x′)i)−Z(x′)t)−log(2),也对目标标签的 logit 值进行优化,同 f3.
其中:
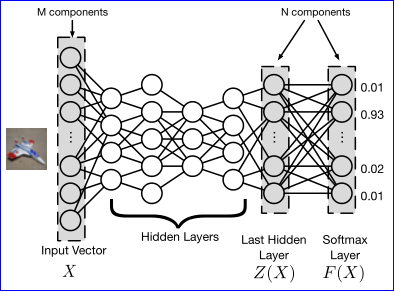
s 是正确的分类,(e)+ 是 max(e,0) 的缩写,suftplus(x)=log(1+exp(x)),lossF,s(x)是关于 x 的交叉熵损失,Z||.|| 是最后一个隐藏层的输出,即 logit 层,F||.|| 是经过 softmax 后的输出,如图示:
现在把原始问题表述为:

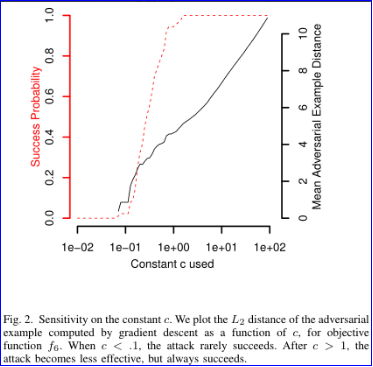
其中 c>0 是一个惩罚因子,用于权衡目标和约束的重要性,有点像正则化,论文通过二分查找法来选择合适的 c,下图是 c 的敏感度,可以看出在 L2 约束和 f6 目标函数的前提下,当 c<1,攻击成功率很低。在 c>1 之后,攻击效果提升不大,但成功率很高。
2.1.3Box constraints
为了确保生成有效的图片,对于像素点的扰动 δ 存在着约束 0≤xi+δi≤1,在优化问题中,这个被称为 “盒约束”。该论文研究了三种不同方法来解决这个问题:
第一个方法是 Projected gradient descent,在每次迭代中,执行一个单步标准梯度下降后,将所有坐标约束到 [0,1] 的范围内,这个方法的性能不佳,原因在于它将剪辑后的图片作为下一次迭代的输入。(这个方法的具体表述不是很清楚,需要看看源码)
第二个方法是 Clipped gradient descent,上述方法存在一个问题就是算法可能会卡在一个平坦的点上,即当像素增加了一个比允许的最大值大得多的分量的时候,再将其约束到 1,那么偏导数就会变成 0。所以这个方法将盒约束整合到目标函数中,即目标函数从 f(x+δ) 转化为 f(min(max(x+δ,0),1))。
第三个方式是 Change of variables,该方法引入一个新的变量 ω,将上述优化 δ 的问题转化为优化 ω,通过定义:

因为−1≤tanh(ωi)≤1,所以0≤xi+δi≤1 是成立的,这样的转化允许我们使用其他不支持盒约束的算法进行优化,论文尝试了三种求解方法:标准梯度下降法、动量梯度下降法以及 Adam 算法,并且发现这三种算法都得到相同质量的解,然而 Adam 算法的收敛速度最快。
2.1.4Evaluation of approach
由于这是有目标攻击:论文考虑了三种不同的策略来选择目标类,分别是:
Average Case: 在不正确的标签中随机均匀地选择目标类。
Best Case: 对所有不正确的类执行攻击,并报告最易攻击的目标类。
Worst Case: 对所有不正确的类执行攻击,并报告最难攻击的目标类。
下图图示为在不同目标类选择策略中,三个不同盒约束中,七个可能目标函数的前提下,L2 的平均距离、标准偏差 (where?) 和攻击成功概率。另外,当攻击成功率不是 100% 时,平均距离仅计算了攻击成功的部分。

从中可以发现看出 Projected gradient descent 在处理盒约束成功率是优于另外两种策略,而 Change of variables 往往能找到更小的扰动,对于目标函数而言,f6表现的比其他的好,扰动最小,成功率最高。为什么有些损失函数比其他函数更好?论文认为原因在于当 c=0 的时候,梯度下降法不会改变原始图像,但是如果 c 较大的时候往往会导致梯度下降的初始步骤过于贪婪,只沿着最容易降低 f 的方向移动,而忽略了 D 的损失,从而导致梯度下降找到次优解。论文认为 f1 和 f4 的表现相对较差,找不到一个合适的 c,因为 c 权衡了距离约束项和损失函数项的重要性,如果要找到一个固定的常数 c,那么这两项的值应该保持相对一致。对于 f4,论文做了一个实验就是将 x 和 x′ 进行线性组合构造 y=αx+(1−α)x′,α∈[0,1]′,事实发现从干净样本到对抗样本(α 从 0 到 1), Z(.)t的值基本是线性的,因此 F(.)t 应该是一个 logistic 函数,论文实验验证结果的皮尔斯相关系数 r>0.9 证明F(.)t服从该分布。那么,对于 f4(x′)=(0.5−F(x′)t)+,其图像应该为
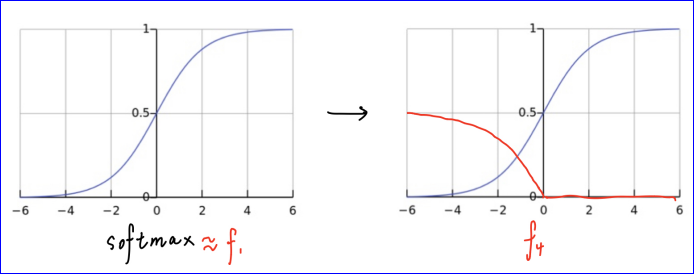
为了使梯度下降攻击在一开始发生变化,常数 c 必须足够大

或者当攻击快结束时,即 ϵ→0,有
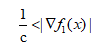
意味着 c 一定要比梯度的倒数更大。
以下为个人对论文的理解:对于 f1 而言,交叉熵损失函数长得很像 softmax,所以攻击开始的时候呢,它的梯度很小,意味着 c 非常的大,但是,当它逐渐增加的时候,梯度以指数的速度增加,这时候使得数值非常大且固定的 c 表现得过度贪婪,即过度优化 f1 而忽略了 D,最终导致优化效果不好,f4 同理。那么对于 f6,由于Z(.)t的值基本是线性的,所以 |∇f6| 是一个常数,所以可以很好的找到一个固定的 c,所以不难解释为什么 f6 表现的比其他的好。
2.1.5Discretization
对于有的图片,其像素数值是整数,则需要对攻击后的图像数据取整,即进行离散化,论文用的是贪心网格搜索。
2.2Three Attacks
最后论文对L2、L0、L∞三种约束提出了三种攻击方法。
2.2.1L2 Attack

f(x′) 这个函数用所有非目标标签的 logit 中最大值减去目标标签的 logit,意味着,如果 x′ 被识别到目标标签,那么 max{Z(x′)i:i≠t}−Z(x′)t 是负的,假如 κ=0,则f(x′)=0,意味着该函数将不会被惩罚,否则如果 x′ 被识别到非目标标签,该函数将会受到惩罚。通过改变 κ 值可以得到设想的置信度。
多起点梯度下降。梯度下降算法的主要问题是贪心搜索不能保证找到最优解,陷入局部极小值。为了弥补这一点,论文选择多个随机起点接近原始图像和运行梯度下降从每个点为固定次数的迭代。论文从半径为 r 的球上均匀地随机采样点,其中 r 是迄今为止发现的最接近的反例。从多个起点开始降低了梯度下降陷入一个糟糕的局部最小值的可能性。同时这也意味着 L2 attack 可以并行化,从而可以提高攻击的速度。
2.2.2L0 Attack
由于 L0 距离度量是不能微分的,所以不能用标准梯度下降方进行求解。所以,论文使用迭代算法,在每次迭代中,识别出一些对分类器输出没有太大影响的像素,然后修复这些像素,因此它们的值永远不会改变。固定像素集在每次迭代中增长,直到通过消除过程确定了像素的最小子集 (但可能不是最小子集),可以修改该子集以生成对抗性示例。在每次迭代中,使用 L2 attack 来识别哪些像素不重要。
具体来说,在每次迭代中,先调用 L2 attack,只修改允许集中的像素,得到一个对抗样本,然后计算目标函数的梯度g=∇f(x+δ),选择这样的像素 i=argminigi⋅δ,把它从允许集中剔除,原因是计算 gi⋅δi 可以让我们知道通过扰动损失函数减少了多少,直到 L2 attack 找不到对抗样本为止。
另一个细节就是 c 的选取,最初将 c 设为一个非常低的值 (例如,10−4)。然后用这个 c 值来产生对抗样本。如果失败了,则将 c 加倍,然后再试一次,直到成功为止。如果 c 超过一个固定的阈值 (例如,1010),则中止搜索。
整个算法与 JSMA 算法有些相似,JSMA 增加了一组允许更改的像素 (最初为空),并设置像素以使总损失最大化。相反,L0 attack 缩小了允许更改的像素集 (最初包含每个像素)。论文提到,在每次迭代中,其不是从初始图像开始梯度下降,而是从上一个迭代中找到的解决方案开始梯度下降,这相当于 “暖启动”,这极大地减少了每次迭代所需的梯度下降轮数,因为 k 像素保持啧啧XzXx不变的解决方案通常与 k+1 像素保持不变的解决方案非常相似。
2.2.3L∞ Attack
同样由于 L∞ 距离度量是不能微分的,所以不能用标准梯度下降方进行求解。论文一开始直接对下式进行优化:

但是实验结果表明 ||δ||∞ 项只对扰动最大的像素点进行惩罚,而对其他像素点没有影响。论文使用迭代攻击来解决这个问题,通过引入一个递减的阈值 τ,如果扰动 δi 大于该值则目标函数将会被惩罚,直到所有扰动都小于该阈值为止:
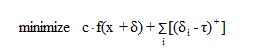
在每次迭代中使用 “暖启动” 来进行梯度下降,该算法的速度大约与L2 attack 算法一样快 (只有一个起始点的时候)。另外 c 值选取的策略和 L0 attack 一致。
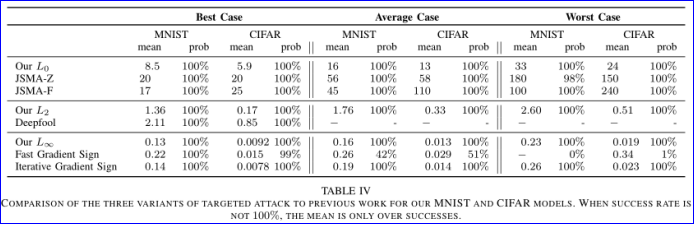
可以看到三种攻击方法的性能比前面做的还是有很大的提升。
2.3蒸馏神经网络(Evaluating Defensive Distillation)
蒸馏网络原来是神经网络压缩的一种方法,蒸馏网络的直觉是基于这样的一个事实,即在训练过程中 DNN 获得的知识不仅被编码为 DNN 学习的权重参数,而且还被编码为网络产生的概率向量。使用类别概率代替硬标签的好处是直观的,因为概率除了简单提供样本的正确类别外,还会编码有关每个类别的其他信息,可以从这个额外的熵推导出有关类的相对信息。
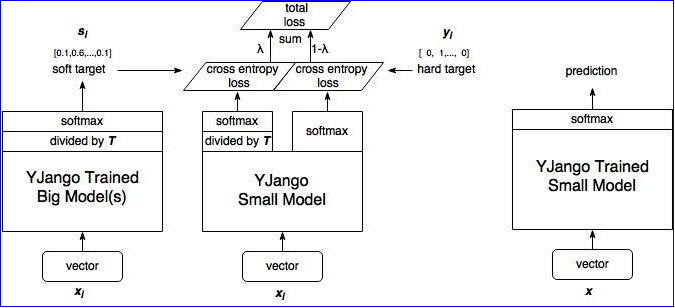
蒸馏网络的训练步骤:
训练大型模型:首先训练具有硬目标即正常标签 (单标签) 的大型模型。
计算软目标:使用训练有素的大型模型来计算软目标。 也就是说,大型模型 “软化” 后,将通过 softmax 的输出。
训练小模型,在小模型的基础上添加附加的软目标损失函数,并通过 λ 调整两个损失函数的比例。
进行预测时,以常规方式使用训练好的小模型(右图)。

训练防御性蒸馏网络步骤如下:
-
在硬标签的监督下训练教师模型。
-
训练完后,使用教师模型来计算得到软标签,具体而言:
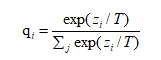
-
在软标签的监督下训练学生模型,这个学生模型与教师模型有着相同的形状。
-
进行预测的时候,学生模型以常规方式进行预测,即 T=1。
两种训练的主要区别我认为一个是学生模型的规模,另一个是 λ 的设置是否。
在软标签的计算中,参数 T 是一个超参数,T 越大,曲线越平滑,这意味着教师模型以较大的 T 来训练网络可以产生分布更加均匀的软标签,随后学生模型以同样的 T 进行学习,可以更加容易学习到类之间的相对信息。在最终预测中,重新设置 T=1,这有利于正确类别以高置信度胜出,而错误类别输出的置信度很低,此时 softmax 层本质上输出了一个硬标签。
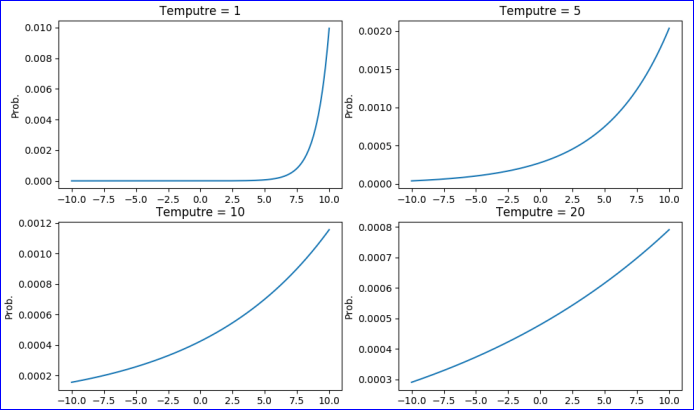
这篇论文提到,事实上,在大多数情况下错误类别输出的置信度太小,以至于 32 位浮点值四舍五入为 0。出于类似的原因,梯度非常小,当用 32 位浮点值表示时,梯度就变成了 0。这导致了依赖于以错误类别梯度进行攻击的算法(FGSM)和依赖梯度进行优化(L-BFGS)或迭代(JSMA-F)的攻击算法由于梯度消失而失效。(JSMA-Z)也会失效是因为改变目标分类所需要相对的差异在 T=1 很大,比如当 logit 从 -100 到 -90,输出仍然是原来的分类,而当 logit 从 10 到 0,输出却变成了另一个类别。
论文评估了本文提出的三种攻击在防御性蒸馏网络效果,如下图,可以看出成功率都为 100%。

另外在以往的工作中,提高蒸馏网络的温度 T 会降低攻击的成功率,而实验显示,L2 attack 成功率与 T 是不相关的,这意味着攻击方法是鲁棒的。

一个模型的对抗样本往往也能对另一个模型攻击成功,即使它们在不同的训练数据集上训练,即使它们使用完全不同的算法 (神经网络上的对抗样本攻击随机森林),这称为对抗样本攻击迁移性,论文分别在非蒸馏网络和防御性蒸馏网络中评估攻击的迁移性能。
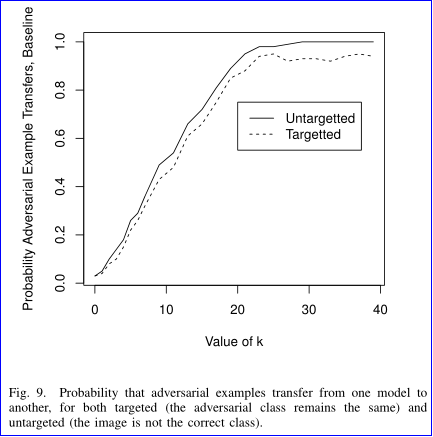
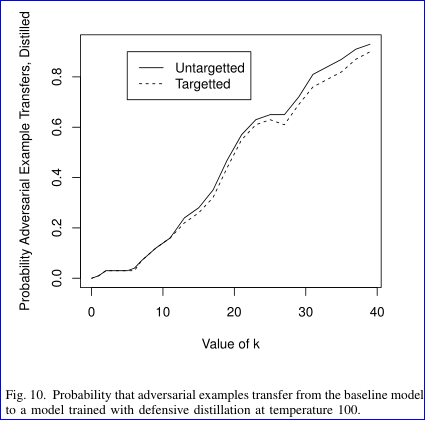
在 L2 attack 中,f(x′)=max(max{Z(x′)i:i≠t}−Z(x′)t,−κ),其中 κ 值用于控制对抗样本的强度, κ 值越大,对抗样本的置信度越高。从图中看出,高置信度的对抗样本迁移性越强。当然使用了防御性蒸馏的网络在一定程度上可以抵御对抗样本的迁移攻击。因此作者认为通过使更强的攻击算法和迁移攻击的成功率来评估神经网络防御的鲁棒性。
3 实验步骤
3.1环境安装
3.1.1github提示
在论文中,本文作者提到已经将程序源代码放在了github上。

上面打开上面的链接会有github链接:
https://github.com/carlini/nn_robust_attacks
在README.md文件中附有安装说明。
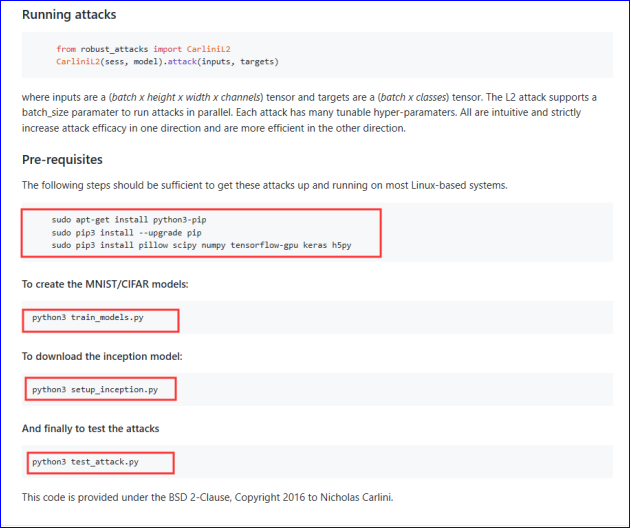
从README.md上,我们可以看到,作者用的是Linux系统,需要安装python3以及pillow 、scipy、 numpy 、tensorflow-gpu 、keras 、h5py等。
后续的实现就很简单了,运行train_models.py文件创建MNIST / CIFAR模型;运行setup_inception.py文件下载初始模型;最后运行test_attack.py文件测试攻击。
3.1.2Pycharm安装
PyCharm 的下载地址:
http://www.jetbrains.com/pycharm/download/#section=windows
进入该网站后,我们会看到如下界面:
professional 表示专业版,community 是社区版,推荐安装社区版,因为是免费使用的。
当下载好以后,点击安装,记得修改安装路径。
2、接下来是

我们可以根据自己的电脑选择32位还是64位。
3、如下
点击Install,然后就是静静的等待安装了。如果我们之前没有下载有Python解释器的话,在等待安装的时间我们得去下载python解释器,不然pycharm只是一副没有灵魂的驱壳
进入python官方网站://www.python.org/
点击Downloads,进入选择下载界面
如下所示,选择我们需要的python版本号,点击Download 。
6、添加环境变量
(1)右键我的电脑,点击属性,弹出如下界面

(2)点击高级系统设置,出现下图

(3)点击环境变量
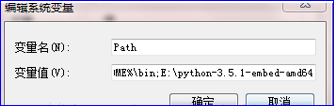
(4)找到系统变量里面的Path,编辑它,将python解释器所在路径粘贴到最后面,再加个分号。
7、pillow 、scipy、 numpy 、tensorflow-gpu 、keras 、h5py等可在Pycharm中进行安装。
(1)打开Pycharm,点击左侧的File,再点击菜单中的设置选项,如下图。
(2)在弹出的“设置”菜单栏中,找到自己的项目,如图中的“py_basic”,点击下面的“Project Interpreter”,在左侧显示的就是已安装的模块。点击图上的“+”,来添加模块。

(3)在图上侧的搜索框输入“numpy”等,左侧就会搜索到对应的模块,点击后,右侧显示模块的版本和详细信息。再点击最下边的“Install Package ”,等待下载安装即可。
(4)环境变量配置结束。
3.2代码运行
3.2.1运行前配置
(1)project interpreter设置
(2)选择project interpreter

3.2.2创建MNIST / CIFAR模型
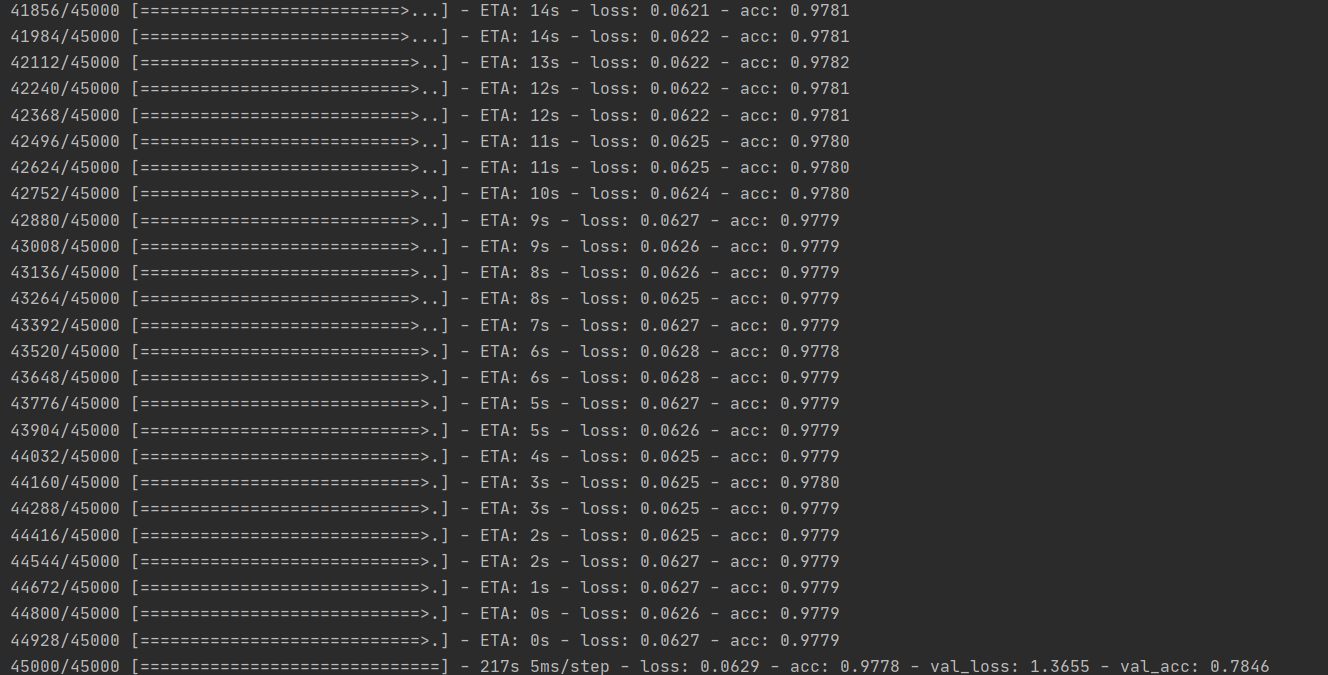
(1)打开train_models.py,右键运行。

(2)在进行三个多小时的“燃烧”CPU后,MNIST / CIFAR模型创建完毕。
3.2.3下载初始模型
(1)运行setup_inception.py。

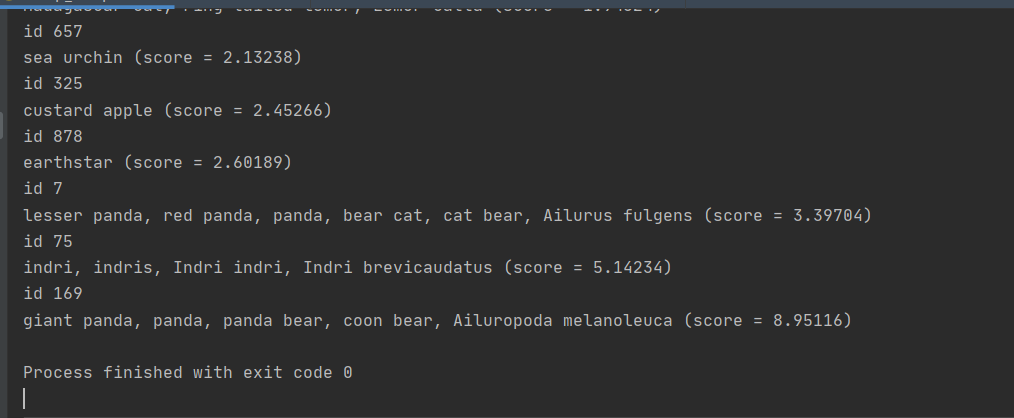
3.2.4测试攻击
(1)运行test_attack.py。

3.3失败教训
本来想在VM里的kali虚拟机来做,结果安装环境完,运行py文件后报错。
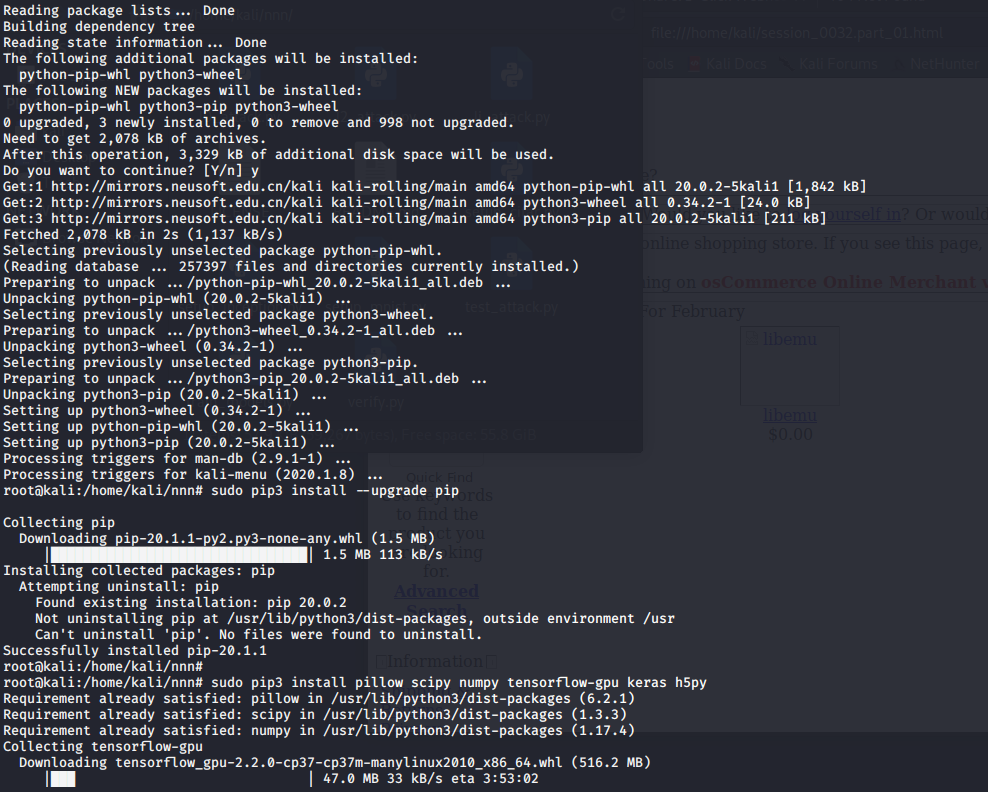
通过分析,感觉应该是环境版本问题,作者是2017年以前做的此程序,现在用的linux指令是直接安装的最新版numpy等。
嗯···在进行解决无果后,我突然想明白了:为啥非在kali上做,在window下装好环境也可以啊,所以我才使用了Pycharm,最终成功。
4 实验总结
本次综合实践我个人感觉最困难的地方在于找源代码和源代码复现。在选择论文方面我选择了从S&P里面挑选,因为里面的论文的PDF等容易寻找。再找了十几篇论文后,我选择了本篇论文,最直接的原因是我对本篇论文的内容挺感兴趣,其次是因为论文里面有源码链接。
论文复现方面主要麻烦的是环境配置工作,在初次失败分析后,通过分析我转变思路,最终成功进行复现。
通过对这篇论文的学习,我的感触很深,详细的阅读、复现了这篇论文之后,我发现,顶会论文名副其实,其研究的深度、广度,现实意义及论文结构,都对我接下来的论文书写工作指明了方向,最后,我觉得在今后的学习过程中,我们要多多思考,多角度的去理解一篇顶会论文。
参考资料
[1] Nicholas Carlini,David Wagner Towards Evaluating the Robustness of Neural Networks [D] 10.1109/SP(2017)
[2] ANDOR, D., ALBERTI, C., WEISS, D., SEVERYN, A., PRESTA, A.,GANCHEV, K., PETROV, S., AND COLLINS, M. Globally normalizedtransition-based neural networks. arXiv preprint arXiv:1603.06042 (2016).
[3] Hinton,Geoffrey, Oriol Vinyals, and Jeff Dean. "Distilling the knowledge in aneural network." arXiv preprint arXiv:1503.02531 (2015).
[4] Pan,Sinno Jialin, and Qiang Yang. "A survey on transfer learning." IEEE Transactionson knowledge and data engineering 22.10 (2010): 1345-1359.