第八周(10.26-11.01):
|
学习计时:共xxx小时 读书: 代码: 作业: 博客:参考:之前每周发布的课堂笔记部分: 《深入理解计算机系统》第三节课课堂笔记(20135213)等等内容 +课本+闫佳歆博客内容 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
一、学习目标 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
复习前面Linux 命令,Linux 编程基础,教材前七章内容
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
二、学习资源 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
1. 教材 2.答案解析见http://group.cnblogs.com/topic/73060.html 考试中错的最多的会再考,关注一下排名前十的同学做错的题目
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
三、学习方法 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
1. 进度很重要:必须跟上每周的进度,阅读,练习,问答,项目。我会认真对待每一位同学,请你不要因为困难半途而废。 2. 问答很重要:遇到知识难点请多多提问,这是你的权利更是您对自己负责的义务。问答到博客园讨论小组:http://group.cnblogs.com/103791/
3. 实践很重要:解决书中习题,实践书中实例,完成每周项目,才算真的消化了这本好书。通过实验楼环境或自己安装的虚拟机在实践中进行学习
4. 实验报告很重要:详细记录你完成项目任务的思路,获得老师点评和帮助自己复习。学习完成后在博客园中(http://www.cnblogs.com/)把学习过程通过博客发表,博客标题“信息安全系统设计基础第八周期中总结”
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
四、学习任务 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
1. 复习Linux命令,特别是man -k, cheat, grep -nr xxx /usr/include 2. 复习vi, gcc, gdb,make的使用 3. 复习教材内容ch01 ch02 ch03 ch04 ch06 ch07 4. 复习前面的考题(答案解析见http://group.cnblogs.com/topic/73060.html) ,下次考试考每次考试错的最多的题目 5. 期中总结发一篇Blog: 知识点总结 自己的收获(不要假大空) 自己的不足(要具体,有改进措施) 课程建议和意见(要有理由)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
五、后续学习预告(可选): |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 第十章:系统级I/O | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
六、学习过程 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
一、常用命令总结clear清屏 man帮助man man打开帮助命令行 总结9点 重点一二章 哪个命令不会用直接man+命令 例如:man ls ls –l 显示所有文件信息 man -k:常用来搜索,结合管道使用。 组合 man –k sort | grep 3
多关键字查找man –k k1 | grep k2 | grep k3 最后的数字意味着帮助手册中的区段,man手册共有8个区段,最常用的是123,含义如下: 但是当单独用man语句的时候,想查看其中的单独某个区段内的解释时,用法是这样的: 即查找c语言中printf的用法。 重点知识:man –k sort 找到任何和sort相关的东西,快速排序 网络协议 cheat(欺骗、作弊)知道命令如何使用:cheat(列出这个命令的常用方法) 例如:cheat find
根目录cd/ pwd显示当前目录所在路径 find locate whereis which grep grep -nrgrep -nr XXX /usr/include (XXX为关键字) 这条语句可以用来查找关键字,全文搜索,并且可以直接查找文件内的内容。其中: 例如,如果想查找某个宏,我们已知宏保存在include文件夹中,所以可以使用下列语句: 二、常用工具vim按
请尝试不同的从普通模式进入插入模式的方法,在最后一行shiyanlou前面加上
进入普通模式,使用下列命令可以进行文本快速删除:
除此之外,你还可以在命令之前加上数字,表示一次删除多行,如:
交换上下行——ddp,快速交换光标所在行与它下面的行。 行间跳转
小技巧:你在完成依次跳转后,可以使用 vim的功能很强大,并且可以移植到很多种不同的程序中,但是我们现在使用的过程中真正用到的命令很少也很简单,更多的技巧参见:VIM相关命令单独记载 gcc常用选项 编译过程 -o后面是接的你给生成的文件指定的名字,如果不指定,则默认为a.out 在命令行上运行这个可执行目标文件需要输入它的名字: 其中./代表当前目录。 gdb注意:使用GCC编译时要加“-g”参数,然后才能够用gdb调试 GDB最基本的命令有: 四种断点: 另外的调试工具: cgdb,有单独的debug窗口,更方便查看 ddd,图形页面 Make和Makefile这是实现自动化编译的好方法。 Makefile的一般写法: 一个Makefile文件主要含有一系列的规则,每条规则包含以下内容:
格式为: 定义变量的两种方式: 使用变量的格式为: 三、正则表达式作用:
规则:
贪婪:尽可能多的匹配加了?后——非贪婪,尽可能少的匹配 四、静态库与动态库静态库(以linux为例)创建该库: 涉及到的参数所做动作: 创建它的可执行文件 相关参数含义: 动态库(linux)构造创建共享库: 参数解析: 把.c文件编译成为.o文件,放入新建的共享库中,并且命名。 链接程序 创建一个可执行目标文件p2,在运行时可以和动态库libverctor.so链接。 五、课本重要思想第一章 计算机系统漫游这一章介绍了一些基本的概念,是以后各章的总括,提到的内容都在之后的各章中拆开细讲,我认为这章最重要的就是一句话: 信息=位+上下文 计算机中的信息都是有二进制数字表达的,而因为这些二进制位所处的位置不同,是有符号数还是无符号数,是大端法还是小端法,由于具体的解释不同,造成的结果也不同。 之后的学习就是如何读写位,和上下文如何对应。 第二章 信息的表示和处理这章里我觉得最容易混淆的是小端法和大端法。常用小端法,巧记方式是“高对高,低对低”,但是同时要注意字节在存放的时候的高低与我们惯常认知中的高低位的关系,以及一串数据中几位代表一个字节: 一个字节是8位,也就是两位十六进制数。 然后是整数中,有符号数和无符号数的表示,补码表示,位运算和逻辑运算,溢出、截断和扩展; 浮点数中,二进制小数,最重要的是IEEE小数:
还有舍入方式:
第三章 程序的机器级表示这一章和之前学习过的汇编很像,需要注意的就是寻址方式和几个操作,mov,push,pop,leal,还有跳转指令、控制转移指令等等。 几个比较新的容易遗忘的知识点是: 翻译循环
寄存器使用惯例
帧栈结构这一部分最重要的参见函数调用帧栈的实践,可以参见孙小博同学的讲解中的调用部分,还有笔记本上的所写的帧栈调用过程。 其实这里最基本的是要知道,针对每一句汇编语句,它都干了些什么,寄存器里的值如何变化,栈帧如何变化,内存中的值如何变化,更要明白的是每一行的变化都代表着什么。 文件在:http://pan.baidu.com/s/1kT4ILON 第四章 处理器体系结构这章里学习的是一个相对简单的处理器Y86,指令集比起IA32省略了很多。学习中我觉得一个比较不容易掌握,做题时需要反复查阅的是: 指令的字节级编码
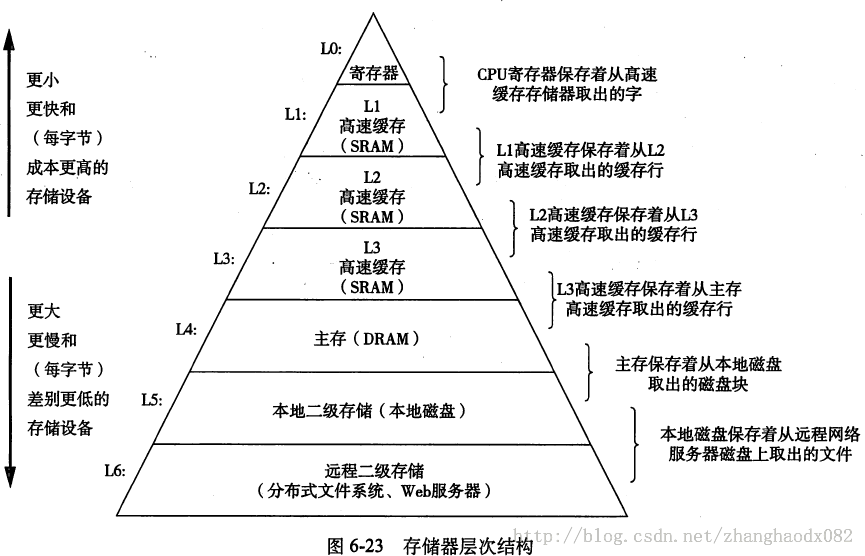
指令编码这一部分可以帮助我们理解机器码与汇编代码的对应关系,并且涉及到下一个我认为的难点: Y86的顺序实现这里的六个阶段和每个阶段进行的动作,得出的数据和对应的结果看起来似乎眼花缭乱,但是课本上已经给出了部分常用命令的具体过程,课后的作业题中也有过类似的作业,这要求我们的举一反三的能力。 至于HDL语言,在EDA课程中已经有过基础,看起来倒是比较轻松。 第六章存储器层次结构涉及到ROM,RAM,磁盘的几个计算,总线等等。概念理解起来比较简单,计算只需要套公式,注意不要漏算盘面或者柱面就好。 这一章我觉得最重要的是局部性。
还有存储器层次结构,这里最重要的思想是这句话:每层存储设备都是下一层的“缓存”。 这样就涉及到了缓存命中和不命中的情况,还有替换策略:
然后是高速缓存存储器。
“存储器山” 作用主要是引入缓存的概念。 关于考试见: 答案摘取 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
七、遇到的问题及解决 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
不足:对于系统并没有认识完全,而且操作也并不熟练。知道用man来寻求具体帮助,但是实际使用的时候并没有很顺手,有事更多的求助方向是百度。
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
八、其他 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
收获:基本认识了Linux的命令以及vim还有存储器相关的知识,对于电脑方面不再像以前拘泥于图形图像的点击方式操作。了解了部分的快捷键和对文件用命令行方式的操作方法。 |