列表的用法和字符串不一样,不要搞混了!
思维导图:
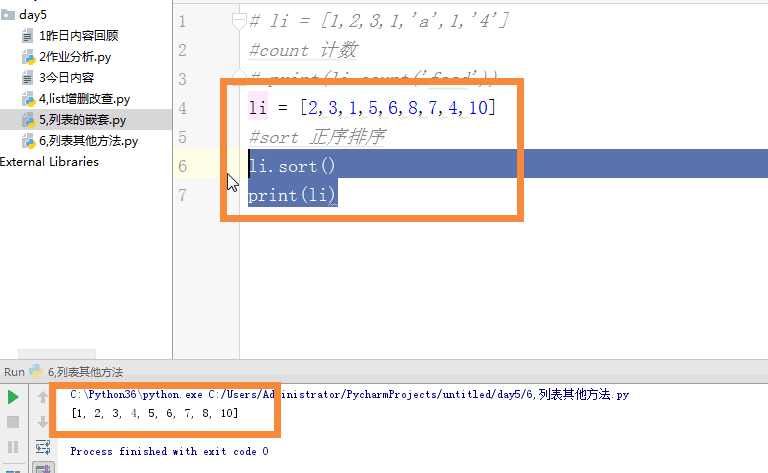
这里要纠错,sort默认参数是sort(reverse=False),这里是正序排序,如果把reverse=True,那么就得到的是反序。
例:
l = [2,3,6,1,7,8]
l.sort()
print(l) #得到的打印结果是:[1, 2, 3, 6, 7, 8]
l1 = l.sort(reverse=True)
print(l) #得到的结果是:[8, 7, 6, 3, 2, 1]

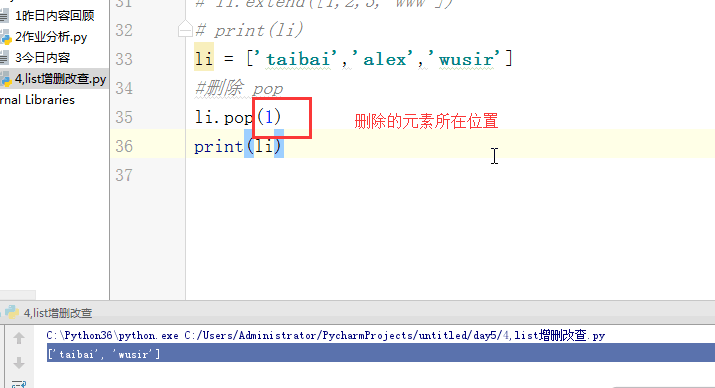
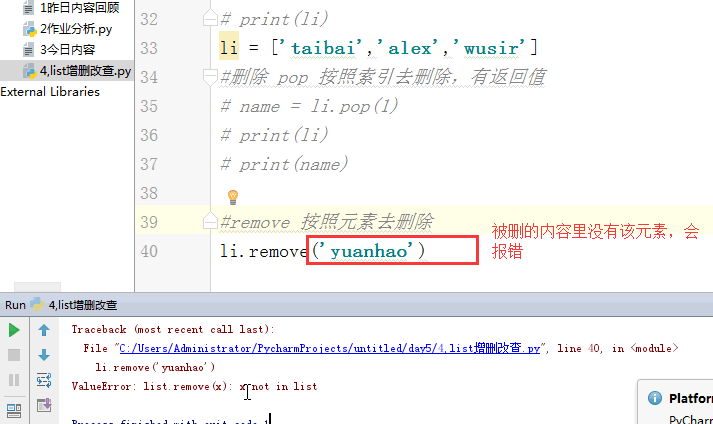
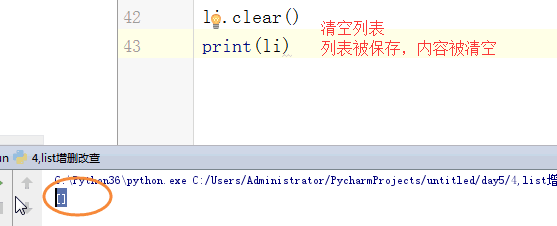
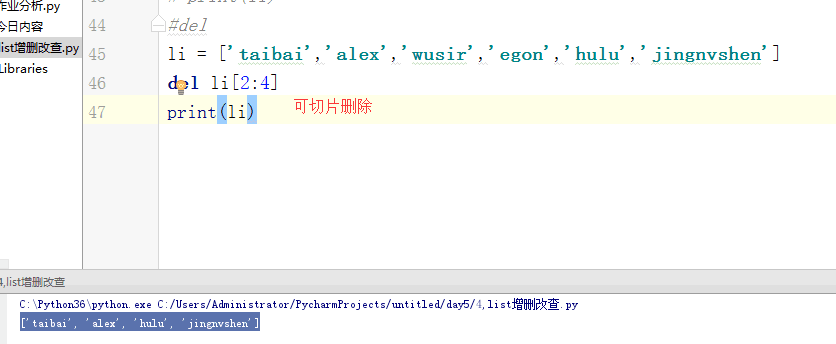
列表的增删改查:


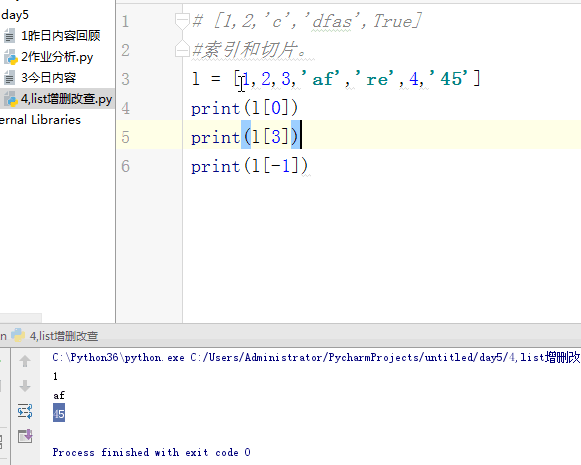
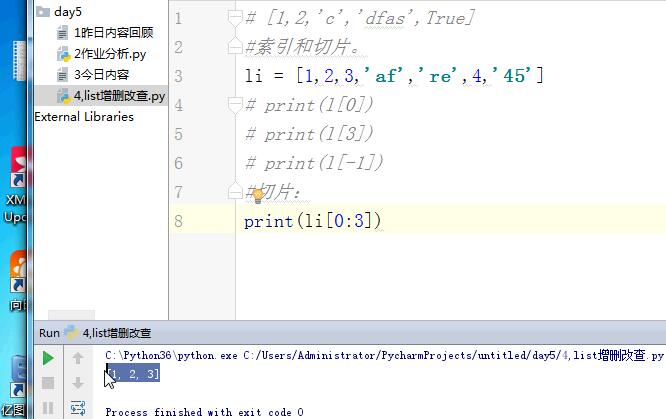
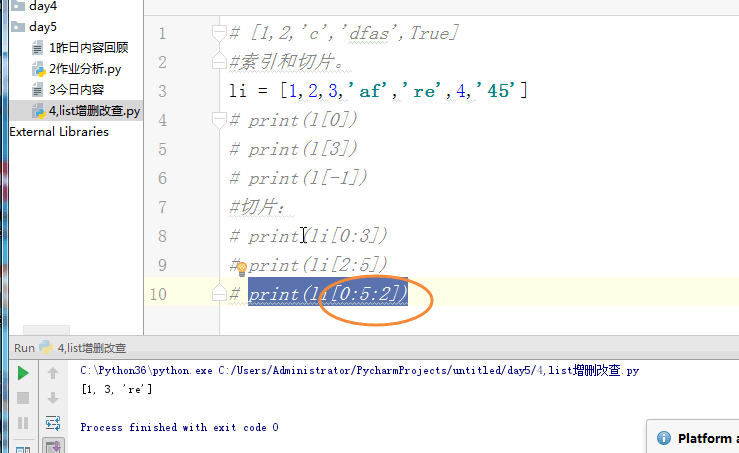
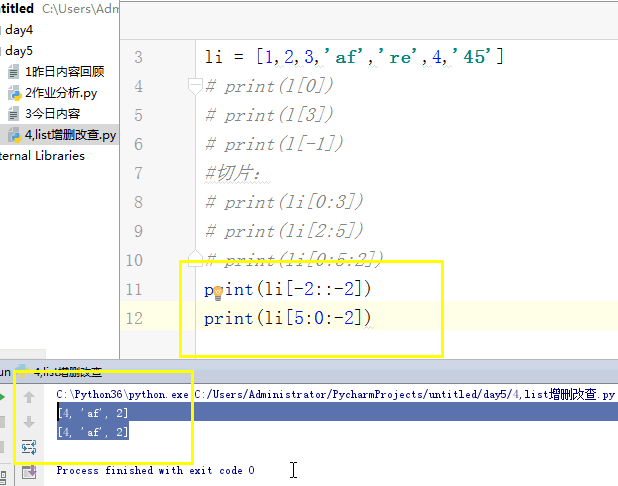
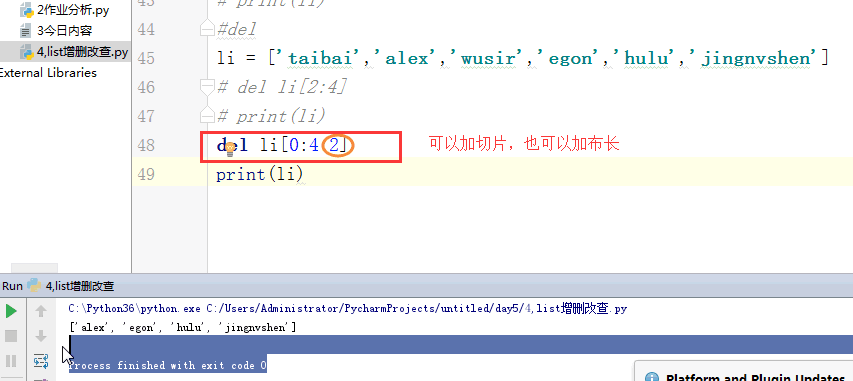
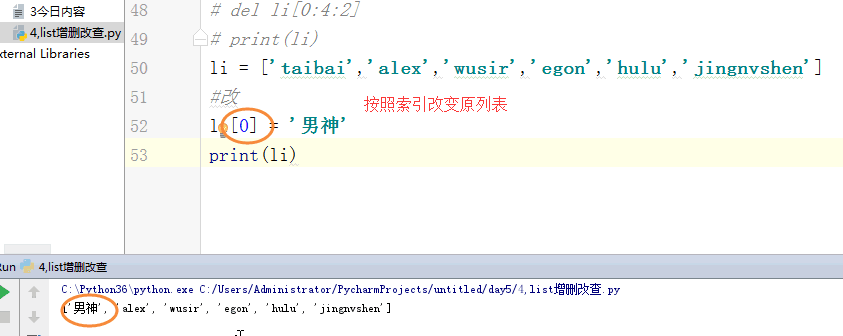
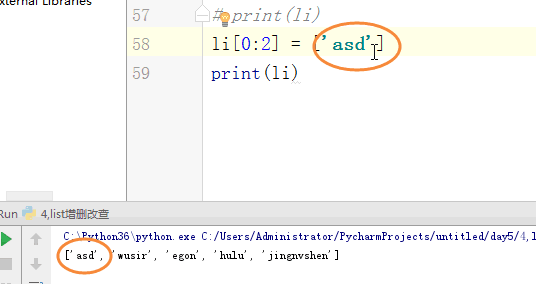
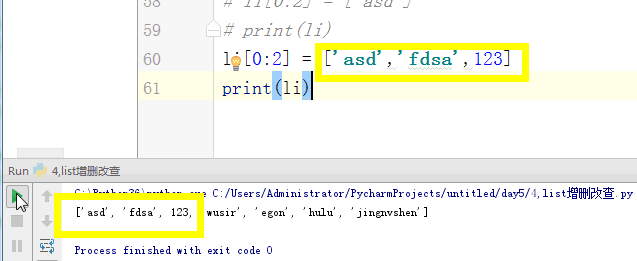
# [1,2,'c','dfas',True] #索引和切片。 # li = [1,2,3,'af','re',4,'45'] # print(l[0]) # print(l[3]) # print(l[-1]) #切片: # print(li[0:3]) # print(li[2:5]) # print(li[0:5:2]) # print(li[-2::-2]) # print(li[5:0:-2]) #苑昊 # li = ['taibai','alex','wusir'] #1增加 append 在最后增加一个元素 # print(li.append('yuanhao')) # li.append([1,2,3,'www']) # print(li) # while True: # username = input('请输入员工姓名:') # if username.lower() == 'q':break # li.append(username) # print(li) #insert 插入 # li = ['taibai','alex','wusir'] # li.insert(1,'日天') # print(li) #extend 迭代的添加 # li.extend('q') # li.extend('asdt') # li.extend([1,2,3,'www']) # print(li) li = ['taibai','alex','wusir','egon','hulu','jingnvshen'] #删除 pop 按照索引去删除,有返回值 name = li.pop(1) # print(li) # print(name) #remove 按照元素去删除 # li.remove('alex') # print(li) #clear 清空列表 # li.clear() # print(li) #del # li = ['taibai','alex','wusir','egon','hulu','jingnvshen'] # del li[2:4] # print(li) # del li[0:4:2] # print(li) li = ['taibai','alex','wusir','egon','hulu','jingnvshen'] #改 切片先删除,迭代着添加 # li[0] = '男神' # print(li) # li[0:3] = '都是男人' # print(li) li[:] = '都是男人' print(li) # li[0:2] = ['asd'] # print(li) # li[0:2] = ['asd','fdsa',123] # print(li) #查 # print(li[1:4]) # for i in li: # print(i) # li = ['taibai','taibai','wusir','egon','taibai','jingnvshen'] # del li # print(li)
列表的其他方法:
一行代码实现删除列表中重复的值:
from collections import OrderedDict 用我们collection模块中的有序字典来实现, x=OrderedDict.fromkeys(['a','b','c','a','b','c','c'])
"""
这里是fromkeys的源码
def fromkeys(cls, iterable, value=None):
'''OD.fromkeys(S[, v]) -> New ordered dictionary with keys from S.
If not specified, the value defaults to None.
'''
self = cls()
for key in iterable:
self[key] = value
return self
""" for i in x: print(i)
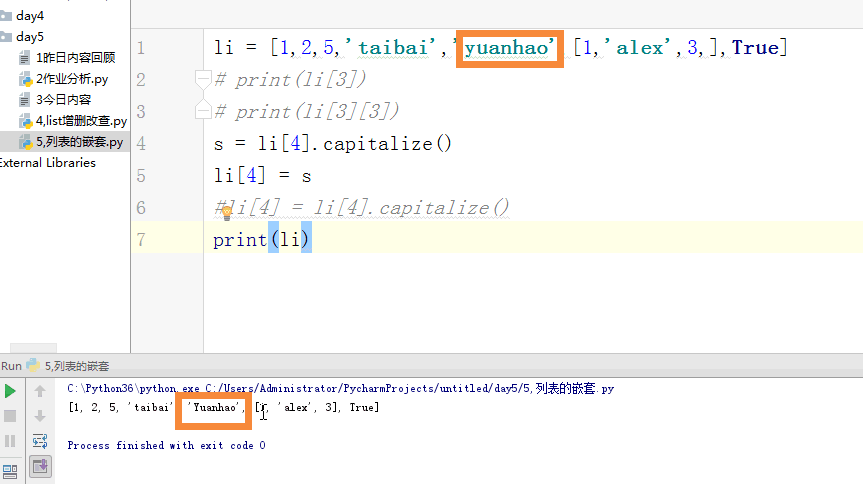
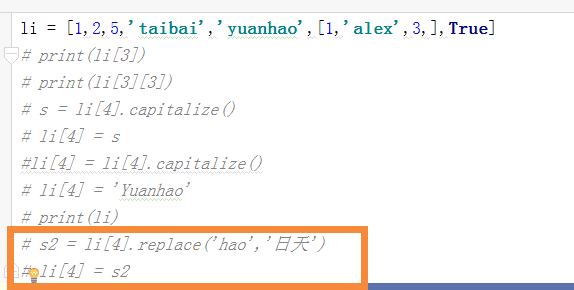
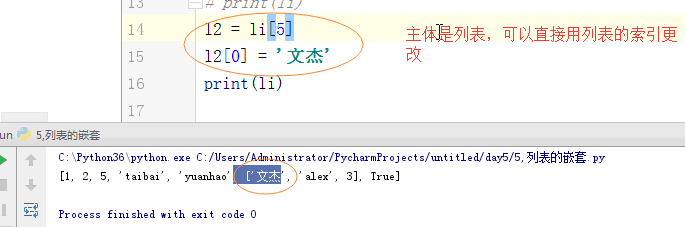
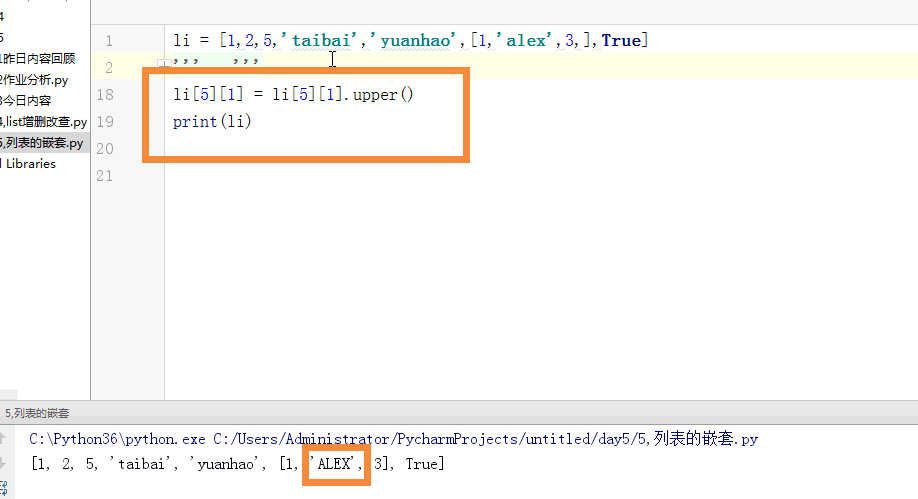
1 列表的嵌套: 2 li = [1,2,5,'taibai','yuanhao',[1,'alex',3,],True] 3 ''' 4 # print(li[3]) 5 # print(li[3][3]) 6 # s = li[4].capitalize() 7 # li[4] = s 8 #li[4] = li[4].capitalize() 9 # li[4] = 'Yuanhao' 10 # print(li) 11 # s2 = li[4].replace('hao','日天') 12 # li[4] = s2 13 # li[4] = li[4][0:4] + 'ritian' 14 # print(li) 15 # l2 = li[5] 16 # li[5][0] = '文杰' 17 # print(li) 18 ''' 19 li[5][1] = li[5][1].upper() 20 print(li) 21 22 23 24 # li = [1,2,3,1,'a',1,'4'] 25 #count 计数 26 # print(li.count('fasd')) 27 li = [2,3,1,5,6,8,9,7,4,10] 28 #sort 正序排序 29 # li.sort() 30 # print(li) 31 #li.sort(reverse=True) 倒叙排序 32 # reverse 反转 33 # li.reverse() 34 # print(li)
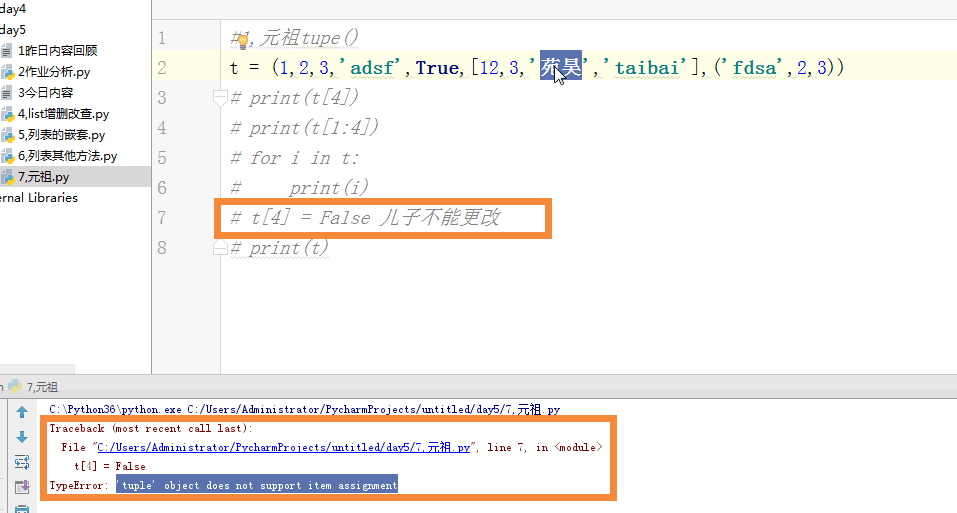
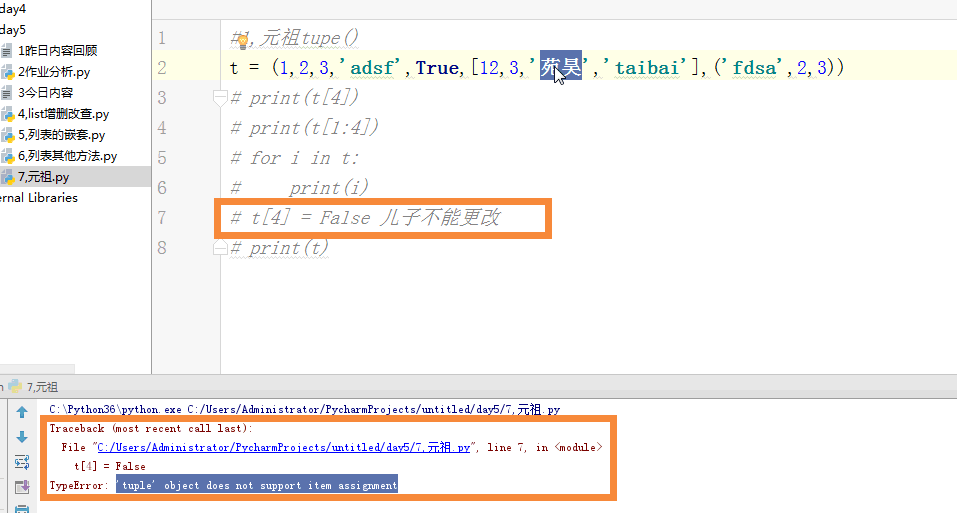
元祖:
元祖是可哈西不可变的数据类型
1 #1,元祖tupe() 2 # t = (1,2,3,'adsf',True,[12,3,'苑昊','taibai'],('fdsa',2,3)) 3 # print(t[4]) 4 # print(t[1:4]) 5 # for i in t: 6 # print(i) 7 # t[4] = False 儿子不能更改 8 # print(t) 9 # t[5][2] = '苑日天' 10 # print(t)
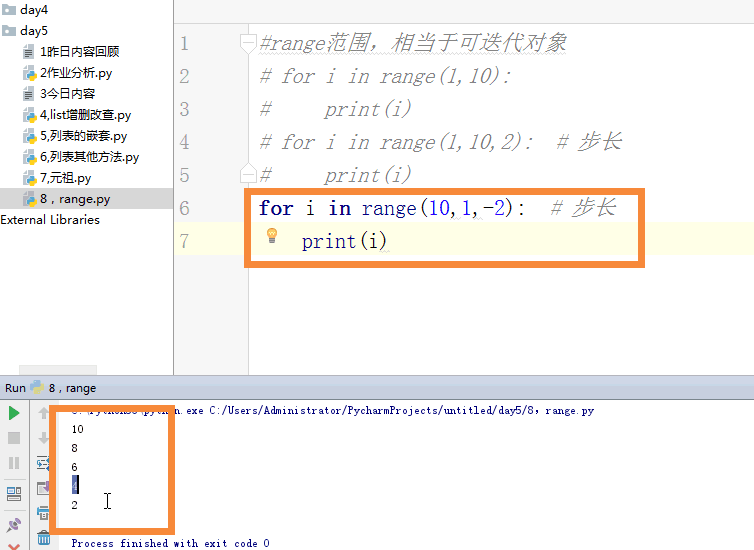
range:
1 #range范围,相当于可迭代对象 2 # for i in range(1,10): 3 # print(i) 4 # for i in range(1,10,2): # 步长 5 # print(i) 6 # for i in range(10,1,-2): # 步长 7 # print(i) 8 li = [1,2,'a',4,[1,2,'太白','alex'],2] 9 #range,len 10 # for i in range(0,len(li)): 11 # if i == 4: # type(li[i]) == list 12 # for j in li[i]: # [1,2,'太白','alex'] 13 # print(j) 14 # else:print(li[i]) 15 16 print(li.index('a',3,6)) 17 # for i in li: 18 # print(i)