博文正文开头格式:(2分)
|
项目 |
内容 |
|
这个作业属于哪个课程 |
https://www.cnblogs.com/nwnu-daizh/ |
|
这个作业的要求在哪里 |
https://www.cnblogs.com/nwnu-daizh/p/11435127.html |
|
作业学习目标 |
|
本章内容:
* 集合接口
* 具体的集合
* 集合框架
* 算法
* 遗留的集合
9.1 集合接口
- Enumeration接口提供了一种用于访问任意容器中各个元素的抽象机制。
9.1.1 将集合的接口与实现分离
-
Java集合类库将接口(interface)与实现(implementation)分离。
-
队列接口指出可以在队列的尾部添加元素,在队列的头部删除元素,并且可以查找队列中元素的个数。当需要收集对象,并按照“先进先出”的规则检索对象时就应该使用队列。
-
队列通常有两种实现方式:一种是使用循环数组;另一种是使用链表。
每一个实现都可以通过一个实现了Queue接口的类表示。 - 如果需要一个循环数组队列,就可以使用ArrayDeque类。如果需要一个链表队列,就直接使用LinkedList类,这个类实现了Queue接口。
- 可以使用接口类型存放集合的引用。
- 循环数组要比链表更高效,因此多数人优先选择循环数组。然而,通常这样做也需要付出一定的代价。
- 循环数组是一个有界集合,即容量有限。如果程序中要收集的对象数量没有上限,就最好使用链表来实现。
- 在研究API文档时,会发现另外一组名字以Abstract开头的类,例如,AbstractQueue。这些类是为类库实现者设计的。如果想要实现自己的队列类,会发现扩展AbstractQueue类要比实现Queue接口中的所有方法轻松得多。
9.1.2 Java类库中的集合接口和迭代器接口
- 在Java类库中,集合类的基本接口是Collection接口,这个接口有两个基本方法:
public interface Collection<E> { boolean add(E element); Iterator<E> iterator(); ... }
iterator方法用于返回一个实现了Iterator接口的对象,可以使用这个迭代器对象依次访问集合中的元素。 - Iterator接口包含3个方法:
public interface Iterator<E> { E next(); boolean hasNext(); void remove(); } - 编译器简单地将“for each”循环翻译为带有迭代器的循环。
- “for each”循环可以与任何实现了Iterable接口的对象一起工作,这个接口只包含一个方法:
public interface Iterable<E> { Iterator<E> iterator(); } - Collection接口扩展了Iterable接口。因此,对于标准类库中的任何集合都可以使用“for each”循环。
- 元素被访问的顺序取决于集合类型,如果对ArrayList进行迭代,迭代器将从索引0开始,没迭代一次,索引值加1。然而,如果访问HashSet中的元素,每个元素将会按照某种随机的次序出现。虽然可以确定在迭代过程中能够遍历到集合中的所有元素,但却无法预知元素被访问的次序。
- Iterator接口的remove方法将会删除上次调用next方法时返回的元素。
- 对next方法和remove方法的调用具有互相依赖性。如果调用remove之前没有调用next将是不合法的。如果这样做,将会抛出一个IllegalStateException异常。
- 实现Collection接口的集合类需要提供很多的例行方法,为了能够让实现者更容易地实现这个接口,Java类库提供了一个类AbstractCollection,它将基础方法size和iterator抽象化了。
- java.util.Collection< E > 1.2
- Iterator< E > iterator()
返回一个用于访问集合中每个元素的迭代器。 - int size()
返回当前存储在几个中的元素个数。 - boolean isEmpty()
如果集合中没有元素,返回true。 - boolean contains(Object obj)
如果集合中包含了一个与obj相等的对象,返回true。 - boolean containsAll(Collection<?> other)
如果这个集合包含other集合中的所有元素,返回true。 - boolean add(Object element)
将一个元素添加到集合中,如果由于这个调用改变了集合,返回true。 - boolean addAll(Collection<? extends E> other)
将other集合中的所有元素添加到这个集合。如果由于这个调用改变了集合,返回true。 - boolean remove(Object obj)
从这个集合中删除等于obj的对象。如果有匹配的对象被删除,返回true。 - boolean removeAll(Collection<?> other)
从这个集合中删除other集合中存在的所有元素。如果由于这个调用改变了集合,返回true。 - void clear()
从这个集合中删除所有的元素。 - boolean retainAll(Collection<?> other)
从这个集合中删除所有与other集合中的元素不同的元素。如果由于这个调用改变了集合,返回true。 - Object[] toArray()
返回这个集合的对象数组。 - < T > T[] toArray(T[] arrayToFill)
返回这个集合的对象数组。如果arrayToFill足够大,就将集合中的元素填入这个数组中。剩余空间填充null;否则,分配一个新数组,其成员类型与arrayToFill的成员类型相同,其长度等于集合的大小,并添入集合元素。
- Iterator< E > iterator()
- java.util.Iterator< E > 1.2
- boolean hasNext()
如果存在可访问的元素,返回true。 - E next()
返回将要访问的下一个对象。如果已经到达了集合的尾部,将抛出一个NoSuchElementException。 - void remove()
删除上次访问的对象。这个方法必须紧跟在访问一个元素之后执行。如果上次访问之后,集合已经发生了变化,这个方法将抛出一个IllegalStateException。
- boolean hasNext()
9.2 具体的集合
- Java库中的具体集合
| 集合类型 | 描述 |
|---|---|
| ArrayList | 一种可以动态增长和缩减的索引序列 |
| LinkedList | 一种可以在任何位置进行高效地插入和删除操作的有序序列 |
| ArrayDeque | 一种用循环数组实现的双端队列 |
| HashSet | 一种没有重复元素的无序集合 |
| TreeSet | 一种有序集 |
| EnumSet | 一种包含枚举类型的集 |
| LinkedHashSet | 一种可以记住元素插入次序的集 |
| PriorityQueue | 一种允许高效删除最小元素的集合 |
| HashMap | 一种存储键/值关联的数据结构 |
| TreeMap | 一种键值有序排列的映射表 |
| EnumMap | 一种键值属于枚举类型的映射表 |
| LinkedHashMap | 一种可以记住键/值项添加次序的映射表 |
| WeakHashMap | 一种其值无用武之地后可以被垃圾回收器回收的映射表 |
| IdentityHashMap | 一种用==而不是用equals比较键值的映射表 |
除了以Map结尾的类之外,其他类都实现了Collection接口。而以Map结尾的类实现了Map接口。
9.2.1 链表
-
数组和数组列表都有一个重大的缺陷,就是从数组的中间位置删除一个元素要付出很大的代码,其原因是数组中处于被删除元素之后的所有元素都要向数组的前端移动。在数组中间的位置上插入一个元素也是如此。
-
在Java程序设计语言中,所有链表实际上都是双向链接的(doubly linked)。
-
链表与泛型集合之间有一个重要的区别。链表是一个有序集合(ordered collection),每个对象的位置十分重要。LinkedList.add方法将对象添加到链表的尾部。但是,尝尝需要将元素添加到链表的中间。由于迭代器是描述集合中位置的,所以这种依赖于位置的add方法将由迭代器负责。只有对自然有序的集合使用迭代器添加元素才有实际意义。因此,在Iterator接口中就没有add方法。相反地,集合类库提供了子接口ListIterator,其中包含了add方法。
- LinkedList的listIterator方法返回一个实现了ListIterator接口的迭代器对象。
- Add方法在迭代器位置之前添加一个新对象。
- set方法用一个新元素取代调用next或previus方法返回的上一个元素。
- 链表只负责耿总对列表的结构性修改,例如,添加元素、删除元素。set操作不被视为结构性修改。
- 链表不支持快速地随机访问。尽管如此,LinkedList类还是提供了一个用来访问某个特定元素的get方法:
LinkedList<String> list = ...; String obj = list.get(n);
绝对不应该使用这种让人误解的随机访问方法来遍历链表。下面这段代码的效率极低:for (int i = 0; i<list.size();i++) do something with list.get(i); - get方法做了微小的优化;如果索引大于size()/2就从列表尾端开始搜索元素。
- 列表迭代器接口还有一个方法,可以告之当前位置的索引。实际上,从概念上讲,由于Java迭代器指向两个元素之间的位置,所以可以同时产生两个索引:nextIndex方法返回下一次调用next方法时返回元素的整数索引;previousIndex方法返回下一次调用previous方法时返回元素的整数索引。当然,这个索引只比nextIndex返回的索引值小1。这两个方法的效率非常高,这是因为迭代器保持着当前位置的计数值。最后需要说一下,如果一个整数索引n,list.listIterator(n)将返回一个迭代器,这个迭代器指向索引为n的元素前面的位置。也就是说,调用next与调用list.get(n)会产生同一个元素,知识获得这个迭代器的效率比较低。
- 为什么要优先使用链表呢?使用链表的唯一理由是尽可能地减少在列表中间插入或删除元素所付出的代价。如果列表只有少数几个元素,就完全可以使用ArrayList。
- 避免使用以整数索引表示链表中位置的所有方法。如果需要对几个进行随机访问,就使用数组或ArrayList,而不要使用链表。
- java.util.List< E > 1.2
- ListIterator< E > listIterator()
返回一个列表迭代器,以便用来访问列表中的元素。 - ListIterator< E > listIterator(int index)
返回一个列表迭代器,以便用来访问列表中的元素,这个元素是第一次调用next返回的给定索引的元素。 - void add(int i,E element)
在给定位置添加一个元素。 - void addAll(int i,Collection<? extends E> elements)
将某个集合中的所有元素添加到给定位置。 - E remove(int i)
删除给定位置的元素并返回这个元素。 - E get(int i)
获取给定位置的元素。 - E set(int i,E element)
用新元素取代给定位置的元素,并返回原来那个元素。 - int indexOf(Object element)
返回与给定元素相等的元素在列表中第一次出现的位置,如果没有这样的元素将返回-1。 - int lastIndexOf(Object element)
返回与给定元素相等的元素在列表中最后一次出现的位置,如果没有这样的元素将返回-1。
- ListIterator< E > listIterator()
- java.util.ListIterator 1.2
- void add(E newElement)
在当前位置前添加一个元素。 - void set(E newElement)
用新元素取代next或previous上次访问的元素。如果在next或previous上次调用之后列表结构被修改了,将抛出一个IllegalStateException异常。 - boolean hasPrevious()
当反向迭代列表是,还有可供访问的元素,返回true。 - E previous()
返回前一个对象。如果已经到达了列表的头部,就抛出一个NoSuchElementException异常。 - int nextIndex()
返回下一次调用next方法时将返回的元素索引。 - int previousIndex()
返回下一次调用previous方法时返回的元素索引。
- void add(E newElement)
- java.util.LinkedList< E > 1.2
- LinkedList()
构造一个空链表。 - LinkedList<collection<? extends="" e=""> elements>
构造一个链表,并将集合中所有的元素添加到这个链表中。 - void addFirst(E element)
- void addLast(E element)
将某个元素添加到列表的头部或尾部。 - E getFirst()
- E getLast()
返回列表头部或尾部的元素。 - E removeFirst()
- E removeLast()
删除并返回列表头部或尾部的元素。
- LinkedList()
9.2.2 数组列表
-
List接口用于描述一个有序集合,并且集合中每个元素的位置十分重要。有两种访问元素的协议:一种是用迭代器。另一种是用get和set方法随机地访问每个元素。后者不适用于链表,但对数组却很有用。集合类库提供了一种大家熟悉的ArrayList类,这个类也实现了List接口。ArrayList封装了一个动态再分配的对象数组。
-
在需要动态数组时,可能会使用Vector类。为什么要用ArrayList取代Vector呢?原因很简单:Vector类的所有方法都是同步的。可以由两个线程安全地访问一个Vector对象。但是,如果由一个线程访问Vector,代码要在同步操作上耗费大量的时间。这种情况还是很常见的。而ArrayList方法不是同步的,因此,建议在不需要同步时使用ArrayLits,而不要使用Vector。
9.2.3 散列集
-
可以快速地查找所需要的对象的常见的数据结构就是散列表(hash table)。散列表为每个对象计算一个整数,称为散列码(hash code)。散列码是由对象的实例域产生的一个整数。更准确的说,具有不用数据域的对象将产生不同的散列码。
-
如果自定义类,就要负责实现这个类的hashCode方法。注意,自己实现的hashCode方法应该与equals方法兼容,即如果a.equals(b)俄日true,a与b必须具有相同的散列码。
-
在Java中,散列表用链表数组实现。每个列表被称为桶(bucket)。要想查找表中对象的位置,就要先计算它的散列码,然后与桶的总数取余,所得到的结果就是保存这个元素的桶的索引。如果在这个桶中没有其他元素,此时将元素直接插入到桶中就可以了。当然,有时候会遇到桶被占满的情况,这也是不可避免的。这种现象被称为散列冲突(hash colision)。这时,需要用新对象与桶中的所有对象进行比较,查看这个对象是否已经存在。如果散列码是合理且随机分布的,桶的数目也足够大,需要比较的次数就会很少。
- 如果想更多地控制散列表的运行性能,就要指定一个初始的桶数。桶数是指用于收集具有相同散列值的桶的数目。如果要插入到散列表中的元素太多,就会增加冲突的可能性,降低运行性能。
- 如果大致知道最终会有多少个元素要插入到散列表中,就可以设置桶数。通常,将桶数设置为预计元素个数的75%~150%。有些研究人员认为:尽管还没有确凿的证据,但最好将桶数设置为一个素数,以防键的集聚。标准类库使用的桶数是2的幂,默认值为16(为表大小提供的任何值都将被自动地转换为2的下一个幂)。
- 如果散列表太满,就需要再散列(rehashed)。如果要对散列表再散列,就需要创建一个桶数更多的表,并将所有元素插入到这个新表中,然后丢弃原来的表。装填因子(load factor)决定何时对散列表进行再散列。例如,如果装填因子为0.75(默认值),而表中超过75%的位置已经填入元素,这个表就会用双倍的桶数自动地进行再散列。对于大多数应用程序来说,填装因子为0.75是比较合理的。
- 散列表可以用于实现几个重要的数据结构。其中最简单的是set类型。set是没有重复元素的元素集合。set的add方法首先在集中查找要添加的对象,如果不存在,就将这个对象添加进去。
- Java集合类库提供了一个HashSet类,它实现了基于散列表的集。可以用add方法添加元素。contains方法已经被重新定义,用来快速地查看是否某个元素已经出现在集中。它只在某个桶中查找元素,而不必查看集合中的所有元素。
- 散列集迭代器将以此访问所有的桶。由于散列将元素分散在表的各个位置上,所以访问它们的顺序几乎是随机的。只有不关心集合中元素的顺序时才应该使用HashSet。
- java.util.HashSet< E > 1.2
- HashSet()
构造一个空散列表。 - HashSet(Collection<? extends E> elements)
构造一个散列表,并将集合中的所有元素添加到这个散列集中。 - HashSet(int initialCapacity)
构造一个空的具有指定容量(桶数)的散列集。 - HashSet(int initialCapacity,float loadFactor)
构造一个具有指定容量和装填因子(一个0.0~1.0之间的数值,确定散列表填充的百分比,当大于这个百分比时,散列表进行再散列)的空散列集。
- HashSet()
- java.lang.Object 1.0
- int hashCode()
返回这个对象的散列码。散列码可以是任何整数,包括正数或负数。equals和hashCode的定义必须兼容,即如果x.equals(y)为true,x.hashCode()必须等于y.hashCode()。
- int hashCode()
9.2.4 树集
-
树集是一个有序集合(sorted collection)。可以以任意顺序将元素插入到集合中。在对集合进行遍历时,每个值将自动地按照排序后的顺序呈现。
-
排序是用树结构完成的(当前实现使用的是红黑树(red-black tree))每次将一个元素添加到树中时,都被放置在正确的排序位置上。因此,迭代器总是以排好序的顺序访问每个元素。
-
将一个元素添加到树中要比添加到散列表中慢,但是,与将元素添加到数组或链表的正确位置上相比还是快很多的。如果树中包含n个元素,查找新元素的正确位置平均需要log2n次比较。
- 将一个元素添加到TreeSet中要比添加到HashSet中慢。
- 将元素添加到散列集和树集
文档 单词总数 不同的单词个数 HashSet TreeSet Alice in Wonderland 28195 5909 5秒 7秒 The Count of Monte Cirsto 466300 37545 75秒 98秒 - java.util.TreeSet 1.2
- TreeSet()
构造一个空树集。 - TreeSet(Collection<? exxtends E> elements)
构造一个树集,并将集合中的所有元素添加到树集中。
- TreeSet()
9.2.5 对象的比较
- TreeSet如何知道希望元素怎样排列呢?在默认情况下,树集假定插入的元素实现了Comparable接口。这个接口定义了一个方法:
public interface Comparable<T> { int compreTo(T other); } -
使用Comparable接口定义排列排序显然有其局限性。对于一个给定的类,只能够实现这个接口一次。可以通过将Comparator对象传递给TreeSet构造器来告诉树集使用不用的比较方法。Comparator接口声明了一个带有两个显式参数的compare方法:
public interface Comparator<T> { int compare(T a,T b); } -
从Java SE 6起,TreeSet类实现了NavigableSet接口。这个接口增加了几个便于定位元素以及反向遍历的方法。
- java.lang.Comparale 1.2
- int compareTo(T other)
将这个对象(this)与另一个对象(other)进行比较,如果this位于other之前则返回负值;如果两个对象在排列顺序中处于相同的位置则返回0;如果this位于other之后则返回正值。
- int compareTo(T other)
- java.util.Comparator 1.2
- int compare(T a,T b)
将两个对象进行比较,如果a位于b之前则返回负值;如果两个对象在排列顺序中处于相同的位置则返回0;如果a位于b之后则返回正值。
- int compare(T a,T b)
- java.util.SortedSet 1.2
- Comparator<? super E> comparator()
返回用于对元素进行排序的比较器。如果元素用Comparable接口的compareTo方法进行比较则返回null。 - E first()
- E last()
返回有序集中的最小元素或最大元素。
- Comparator<? super E> comparator()
- java.util.NavigableSet 6
- E higher(E value)
- E lower(E value)
返回大于value的最小元素或小于value的最大元素,如果没有这样的元素则返回null。 - E ceiling(E value)
- E floor(E value)
返回大于等于value的最小元素或小于等于value的最大元素,如果没有这样的元素则返回null。 - E pollLast
删除并返回这个集中的最大元素或做小元素,这个集为空时返回null。 - Iterator descendingIterator()
返回一个按照递减顺序遍历集中元素的迭代器。
- java.util.TreeSet 1.2
- TreeSet()
构造一个用于排列Comparable对象的树集。 - TreeSet(Comparator<? super E> c)
构造一个树集,并使用指定的比较器对其中的元素进行排序。 - TreeSet(SortedSet<? extends E> elements)
构造一个树集,将有序集中的所有元素添加到这个树集中,并使用与给定集相同的元素比较器。
- TreeSet()
9.2.6 队列与双端队列
-
队列可以让人们有效地在尾部添加一个元素,在头部删除一个元素。有两个端头的队列,即双端队列,可以让人们有效地再头部和尾部同事添加或删除元素。不支持在队列中间添加元素。在Java SE 6中引入了Deque接口,并由ArrayDeque和LinkedList类实现。这两个类都提供了双端队列,并且在必要时可以增加队列的长度。
-
java.util.Queue 5.0
- boolean add(E element)
- boolean offer(E element)
如果队列没有满,将给定的元素添加到这个双端队列的尾部并返回true。如果队列满了,第一个方法将抛出一个IllegalStatelException,而第二个方法返回false。 - E remove()
- E poll()
加入队列不空,删除并返回这个队列头部的元素。如果队列是空的,第一个方法抛出NoSuchElmentException,而第二个方法返回null。 - E element()
- E peek()
如果队列不空,返回这个队列头部的元素,但不删除。如果队列空,第一个方法将抛出一个NoSuchElementException,而第二个方法返回null。
-
java.util.Deque< E > 6
- void addFirst(E element)
- void addLast(E element)
- boolean offerFirst(E element)
- boolean offerLast(E element)
将给定的对象添加到双端队列的头部或尾部。如果队列满了,前面两个方法将抛出一个IllegalStateException,而后面两个方法返回false。 - E removeFirst()
- E removeLast()
- E pollFirst()
- E pollLast()
如果队列不空,删除并返回队列头部的元素。如果队列为空,前面两个方法将抛出一个NoSuchElementException,而后面两个方法返回null。 - E getFirst()
- E getLast()
- E peekFirst()
- E peekLast()
如果队列非空,返回队列头部的元素,但不删除。如果队列空,前面两个方法将抛出一个NoSuchElementException,而后面两个方法返回null。
-
java.util.ArrayDeque< E > 6
- ArrayDeque()
- ArrayDeque(int initialCapacity)
用初始容量16或给定的初始容量构造一个无限双端队列。
9.2.7 优先级队列
-
优先级队列(priority queue)中的元素可以按照任意的顺序插入,却总是按照排序的顺序进行检索。也就是说,无论何时调用remove方法,总会获得当前优先级队列中最小的元素。然而,优先级队列并没有对所有的元素进行排序。如果用迭代的方式处理这些元素,并不需要对它们进行排序。优先级队列使用了一个优雅且高效地数据结构,称为堆(heap)。堆是一个可以自我调整的二叉树,对树执行添加(add)和删除(remore)操作,可以让最小的元素移动到根,而不必花费时间对元素进行排序。
-
与TreeSet一样,一个优先级队列既可以保存实现了Comparable接口的类对象,也可以保存在构造器中提供比较器的对象。
-
java.util.PriorityQueue 5.0
- PriorityQueue()
- PriorityQueue(int initialCapacity)
构造一个用于存放Comparable对象的优先级队列。 - PriorityQueue(int initialCapacity,Comparator<? super E> c)
构造一个优先级队列,并用指定的比较器对元素进行排序。
9.2.8 映射表
-
映射表用来存放键/值对。如果提供了键,就能够查找到值。
-
Java类库为映射表提供了两个通用的实现:HashMap和TreeMap。这两个类都实现了Map接口。
-
散列映射表对键进行散列,树映射表用键的整体顺序对元素进行排序,并将其组织成搜索树。散列或比较函数只能作用于键。与键关联的值不能进行散列或比较。
- 应该选择散列映射表还是树映射表呢?与集一样,散列稍微快一些,如果不需要按照排列顺序访问键,就最好选择散列。
- 键必须是唯一的。不能对同一个键存放两个值。如果对同一个键两次调用put方法,第二个值就会取代第一个值。实际上,put将返回用这个键参数存储的上一个值。
- remove方法用于从映射表中删除给定键对应的元素。size方法用于返回映射表中的元素数。
- 集合框架并没有将映射表本身视为一个集合(其他的数据结果框架则将映射表视为对(pairs)的集合,或者视为用键作为索引的值的集合)。然而,可以获得映射表的视图,这是一组实现了Collection接口对象,或者它的子接口的视图。
- keySet既不是HashSet,也不是TreeSet,而是实现了Set接口的某个其他类的对象。Set接口扩展了Collection接口。因此,可以与使用任何集合一样使用keySey。
- 如果调用迭代器的remove方法,实际上就从映射表中删除了键以及对应的值。但是,不能将元素添加到键集的视图中。如果只添加键而不添加值是毫无意义的。如果视图调用add方法,将会抛出一个UnsupportedOperationException异常。条目集视图也有同样的限制,不过,从概念上讲,添加新的键/值对是有意义的。
- java.util.Map< K,V > 1.2
- V get(Object key)
获取与键对应的值;返回与键对应的对象,如果在映射表中没有这个对象则返回null。键可以为null。 - V put(K key,V value)
将键与对应的值关系插入到映射表中。如果这个键已经存在,新的对象将取代与这个键对应的就对象。这个方法将返回键对应的旧值。如果这个键以前没有出现过则返回null。键可以为null,但值不能为null。 - void putAll(Map<? extends K,?extends V> entries)
将给定映射表中的所有条目添加到这个映射表中。 - boolean containsKey(Object key)
如果在映射表中已经有这个键,返回true。 - boolean containsValue(Objecy value)
如果应设变中已经有这个值,返回true。 - Set< Map.Entry< K,V >> entrySet()
返回Map.Entry对象的集视图,即映射表中的键/值对。可以从这个集中删除元素,同时也从映射表中删除了它们。但是,不能添加任何元素。 - Set< K > keySet()
返回映射表中所有键的集视图。可以从这个集中删除元素,同时也从映射表中删除了它们。但是,不能添加任何元素。 - Collection< V > values()
返回映射表中所有值的集合视图。可以从这个集中删除元素,同时也从映射表中删除了它们。但是,不能添加任何元素。
- V get(Object key)
- java.util.Map.Entry< K,V > 1.2
- K getKey()
- V getValue()
返回这个条目的键或值。 - V getValue(V newValue)
设置在映射表中与新值对应的值,并返回旧值。
- java.util.HashMap< K,V > 1.2
- HashMap()
- HashMap(int initialCapacity)
- HashMap(int initialCapacity,float loadFactor)
用给定的容量和装填因子构造一个空散列映射表(装填因子是一个0.0~1.0之间的数值。这个数值决定散列表填充的百分比。一旦到了这个比例,就要将其再散列到更大的表中)。默认的装填因子是0.75。
- java.util.TreeMap< K,V > 1.2
- TreeMap(Comparator<? super K> c)
构造一个树映射表,并使用一个指定的比较器对键进行排序。 - TreeMap<map<? extends="" k,?="" v=""> entries>
构造一个树映射表,并将某个映射表中的所有条目添加到树映射表中。 - TreeMap(SortedMap<? extends K,? extends V> entries)
构造一个树映射表,将某个有序映射表中的所有条目添加到树映射表中,并使用与给定的有序映射表相同的比较器。
- TreeMap(Comparator<? super K> c)
- java.util.SortedMap< K,V > 1.2
- Comparator<? super K> comparator()
返回对键进行排序的比较器。如果键是用Comparable接口的compareTo方法进行比较的,返回null。 - K firstKey()
- K lastKey()
返回映射表中最小元素和最大元素。
- Comparator<? super K> comparator()
9.2.9 专用集合映射表类
-
弱散列映射表
设计WeakHashMap类是为了解决一个有趣的问题。如果有一个值,对应的键已经不在使用了,将会出现什么情况呢?假定对某个键的最后一次引用已经消亡,不会有任何途径引用这个值的对象了。但是,由于在程序中的任何部分没有再出现这个键,所以,这个键/值对无法从映射表中删除。为什么垃圾回收期不能够删除它呢?难道删除无用的对象不是垃圾回收器的工作吗?
垃圾回收器耿总活动的对象。只要映射表对象是活动的,其中的所有桶也是活动的,它们不能被回收。因此,需要由程序负责从长期存活的映射表中删除那些无用的值。或者使用WeakHashMap完成这件事情。当对键的唯一引用来自散列表条目时,这一数据结构将与垃圾回收器协同工作一起删除键/值对。
WeakHashMap使用弱引用(weak references)保存键。WeakReference对象将引用保存到另外一个对象中,在这里,就是散列表键。对于这种类型的对象,垃圾回收器用一种特有的方式进行处理。通常,如果垃圾回收器发现某个特定的对象已经没有他人引用了,就将其回收。然而,如果某个对象只能有WeakReference引用,垃圾回收器仍然回收它,但要将引用这个对象的弱引用放入队列中。WeakHashMap将周期性地检查队列,以便找出新添加的弱引用。一个弱引用进入队列意味着这个键不再被他人使用,并且已经被收集起来。于是,WeakHashMap将删除对应的条目。 -
链接散列集和链接映射集
Java SE 1.4增加了两个类:LInkedHashSet和LinkedHashMap,用来记住插入元素想的顺序。这样就可以避免在散列表中的项从表面上看是随机排列的。当条目插入到表中时,就会并入到双向链表中。
链接散列映射表将用访问顺序,而不是插入顺序,对映射表条目进行迭代。每次调用get或put,受到影响的条目将从当前的位置删除,并放到条目链表的尾部(只有条目在链表中的位置会受影响,而散列表中的桶不会受影响。一个条目总位于与键散列码对应的桶中)。
访问顺序对于实现高速缓存的“最近最少使用”原色十分重要。 -
枚举集与映射集
EnumSet是一个枚举类型元素集的高效实现。由于枚举类型只有有限个实例,所以EnumSet内部用位序列实现。如果对应的值在集中,则对应的位被置为1。
EnumSet类没有公共的构造器。可以使用静态工厂方构造这个集。
可以使用Set接口的常用方法来修改EnumSet。
EnumMap是一个键类型为枚举类型的映射表。它可以直接且高效地用一个值数组实现。在使用时,需要在构造器中指定键类型。 - 标识散列映射表
Java SE 1.4还为另外一个特殊目的增加了另一个类IdentityHashMap。在这个类中,键的散列值不是用hashCode函数计算的,而是用System,identityHashCode方法计算的。这是Object.hashCode方法根据对象的内存地址来计算散列码时所使用的方法。而且,在对两个对象进行比较时,IdentityHashMap类使用==,而不使用equals。
也就是说,不同的键对象,即使内容相同,也被视为是不同的对象。在实现对象遍历算法(如对象序列化)时,这个类非常有用,可以用来跟踪每个对象的遍历状况。 -
java.util.WeakHashMap< K,V > 1.2
- WeakHashMap()
- WeakHashMao(int initialCapacity)
- WeakHashMap(int initialCapacity,float loadFactor)
用给定的容量和填充因子构造一个空的散列映射表。
-
java.util.LinkedHashSet 1.4
- LinkedHashSet()
- LinkedHashSet(int initialCapacity)
- LinkedHashSet(int initialCapacity,float loadFactor)
用给定的容量和填充因子构造一个空链接散列集。
-
java.util.LinkedHashMap< K,V > 1.4
- LinkedHashMap()
- LinkedHashMap(int initialCapacity)
- LinkedHashMap(int initialCapacity,float loadFactor)
- LinkedHashMap(int initialCapacity,float loadFactor,boolean accessOrder)
用给定的容量、填充因子和顺组构造一个空的链接散列映射表。 - protected boolean removeEldestEntry(Map.Entry< K,V > eldest)
如果想删除eldest元素,并同时返回true,就应该覆盖这个方法。eldest参数是预期要删除的条目。这个方法将在条目添加到映射表中之后调用。其默认的实现将返回false。即在默认情况下,旧元素没有被删除。然而,可以重新定义这个方法,以便有选择地返回true。
-
java.util.EnumSet< E extends Enum< E >> 5.0
- static < E extends Enum< E >> EnumSet< E > allOf(Class< E > enumType)
返回一个包含给定枚举类型的所有值的集。 - static < E extends Enum< E >> EnumSet< E > noneOf(Class< E > enumType)
返回一个空集,并有足够的保存给定的枚举类型所有的值。 - static < E extends Enum< E > > EnumSet< E > range(E from,E to)
返回一个包含from~to之间的所有值(包括两个边界的元素)的集。 - static < E extends Enum< E > > EnumSet< E > of(E value)
- static < E extends Enum< E > > EnumSet< E > off(E value,E… value)
返回包括给定值的集。
- static < E extends Enum< E >> EnumSet< E > allOf(Class< E > enumType)
-
java.util.EnumMap< K extends Enum< K >,V > 5.0
- EnumMap(Class< K > keyType)
构造一个键为给定类型的空映射集。
- EnumMap(Class< K > keyType)
-
java.util.IdentityHashMap< K,V > 1.4
- IdentityHashMap()
- IdentityHashMap(int expectedMaxSize)
构造一个空的标识散列映射集,其容量是大于1.5*expectedMaxSize的2的最小次幂(expectedMaxSize的默认值是21)。
-
java.lang.System 1.0
- static int identityHashCode(Object obj) 1.1
返回Object.hashCode计算出来的相同散列码(根据对象的内存地址产生),即使obj所属的类已经重新定义了hashCode方法也是如此。
- static int identityHashCode(Object obj) 1.1
9.3 集合框架
-
框架(framework)是一个类的集,它奠定了创建高级功能的基础。框架包含很多超类,这些超类拥有非常有用的功能、策略和机制。框架使用者创建的子类可以扩展超类的功能,而不必重新创建这些基本的机制。
-
Java集合类库构成了集合类的框架,它为集合的实现者定义了大量的接口和抽象类,并且对其中的某些机制给予了描述。如果想要实现用于多种集合类型的泛型算法,或者是想增加新的集合类型,了解一些框架的知识是很有帮助的。
-
集合有两个基本的接口:Collection和Map。可以使用下列方法向集合中插入元素:
boolean add(E element)但是,由于映射表保存的是键/值对,所以可以使用put方法进行插入。
V put(K key,V value)要想从集合中读取某个元素,就需要使用迭代器访问它们。然而,也可以用get方法从映射表读取值:
V get(K key) - List是一个有序集合(ordered collection)。元素可以添加到容器中某个特定的位置。将对象放置在某个位置上可以采用两种方式:使用整数索引或使用列表迭代器。List接口定义了几个用于随机访问的方法:
void add(int index,E element) E get(int index) void remove(int index) -
List接口在提供这些随机访问方法时,并不管它们对某种特定的实现是否高效。为了避免执行成本较高的随机访问操作,Java SE 1.4引入了一个标记接口RandomAccess。这个接口没有任何方法,但可以用来检测一个特定的集合是否支持高效的随机访问:
if (c instanceof RandomAccess) { use random access algorithm } else { use sequential access algorithm }ArrayList类和Vector类都实现了RandomAccess接口。
-
ListIterator接口定义了一个方法,用于将一个元素添加到迭代器所处位置的前面:
void add(E element)要想获取和删除给定位置的元素,值需要调用Iterator接口中的next方法和remove方法即可。
- Set接口与Collection接口是一样的,只是其方法的行为有着更加严谨的定义。集的add方法拒绝添加重复的元素。集的equals方法定义两个集相等的条件是他们包含相同的元素但顺序不必相同。hashCode方法定义应该保证具有相同元素的集将会得到相同的散列码。
- 既然方法签名是相同的,为什么还要建立一个独立的接口呢?从概念上讲,并不是所有集合都是集。建立set接口后,可以让程序员编写仅接受集的方法。
- SortedSet和SortedMap接口暴露了用于排序的比较器对象,并且定义的方法可以获得集合的子集视图。
- Java SE 6引入了接口NavigableSet和NavigableMap,其中包含了几个用于在有序集和映射表中查找和遍历的方法(从理论上讲,这几个方法已经包含在SortedSet和SortedMap的接口中)。TreeSet和TreeMap类实现了这几个接口。
- 集合接口有大量的方法,这些方法可以通过更基本的方法加以实现。抽象类提供了许多这样的例行实现:
AbstractCollection
AbstractList
AbstractSequentialList
AbstractSet
AbstractQueue
AbstractMap
如果实现了自己的集合类,就可能要扩展上面某个类,以便可以选择例行操作的实现。 - Java类库支持下面几种具体类:
LinkedList
ArrayList
ArrayDeque
HashSet
TreeSet
PriorityQueue
HashMap
TreeMap
还有许多Java第一版“遗留”下来的容器,在集合框架出现就有了,它们是:
Vector
Stack
Hashtable
Properties
这些类已经被集成到集合框架中。
9.3.1 视图与包装器
-
通过使用视图(views)可以获得其他的实现了集合接口和映射表接口的对象。映射表类的keySet方法就是一个这样的实例。初看起来,好像这个方法创建了一个新集,并将映射表中的所有键都填进去,然后返回这个集。但是,情况并非如此。取而代之的是:keySet方法返回一个实现Set接口的类对象,这个类的方法对原映射表进行操作。这种集合称为视图。
-
轻量级集包装器
Arrays类的静态方法asList将返回一个包装了普通Java数组的List包装器。这个方法可以将数组传递给一个期望得到列表或几个变元的方法。返回的对象不是ArrayList。
它是一个视图对象,带有访问底层数组的get和set方法。改变数组大小的所有方法(例如,与迭代器有关的add和remove方法)都会抛出一个Unsupported OperationException异常。
从Java SE 5.0开始,asList方法声明为一个具有可变数量参数的方法。除了可以传递一个数组之外,还可以将各个元素直接传递给这个方法。 - Collections类包含很多实用方法,这些方法的参数和返回值都是集合。不要将它与Collection接口混淆起来。
-
如果调用下列方法
Collections.singleton(anObject)则将返回一个视图对象。这个对象实现了Set接口(与产生List的ncopies方法不同)。返回的对象实现了一个不可修改的单元素集,而不需要付出建立数据结构的开销。singletonList方法与singletomMap方法类似。 -
子范围
可以为很多集合建立子范围(subrange)视图。可以使用subList方法来获得一个列表的子范围视图。
可以将任何操作应用于子范围,并且能够自动地反映整个列表的情况。
对于有序集和映射集,可以使用排序顺序而不是元素位置建立子范围。SortedSet接口声明了3个方法:SortedSet< E > subSet(E from,E to) SortedSet< E > headSet(E to) SortedSet< E > tailSet(E from)这些方法将返回大于等于from且小于to的所有元素子集。有序映射表也有类似的方法:
SortedMap< K,V > subMap(K from,K to) SortedMap< K,V > headMap(K to) SortedMap< K,V > tailMap(K from)返回映射表视图,该映射表包含键落在指定范围内的所有元素。
Java SE 6引入的NavigableSet接口赋予自返回操作更多的控制能力。可以指定是否包括边界:NavigableSet< E > subSet(E from, boolean fromInclusive,E to,boolean toInclusive) NavigableSet< E > headSet(E to,boolean toInclusive) Navigable< E > tailSet(E from,boolean fromInclusive) -
不可修改的视图
Collections还有几个方法,用于产生集合的不可修改视图(unmodifiable views)。这些视图对现有集合曾姐了一个运行时的检查。如果发现视图对集合进行修改,就抛出一个异常,同时这个集合将保持未修改的状态。
可以使用下面6中方法获得不可修改视图:Collections.unmodifiableCollection Collections.unmodifiableList Collections.unmodifianleSet Collections.unmodifiableSortedSet Collections.unmodifiableMap Collections.unmodifiableSortedMap每个方法都定义于一个接口。例如,Collections.unmodifiableList与ArrayList、LInkedList或者任何实现了List接口的其他类一起协同工作。
lookAt方法可以调用List接口中的所有方法,而不只是访问器。但是所有的更改器方法(例如,add)已经被重新定位为抛出一个UnsupportedOperationException异常,而不是将调用传递给底层集合。
不可修改视图并不是集合本身不可修改。仍然可以通过集合的原始引用对集合进行修改。并且仍然可以让集合的元素调用更改器方法。
由于视图只是包装了接口而不是实际的集合对象,所以只能访问接口中定义的方法。例如,LinkedList类有一些非常方便的方法,addFirst和addLast,它们都不是List接口的方法,不能通过不可修改视图进行访问。
unmodifiableCollection方法将返回一个集合,它的equals方法不调用底层集合的queals方法。相反,它继承了Object类的equals方法,这个方法只是检测两个对象是否是同一个对象。如果将集或列表转换成集合,就再也无法检测其内容是否相同了。视图就是以这种方式运行的,因为内容是否相等的检测在分层结构的这一层上没有定义妥当。然而,unmodifiableSet类和unmodifiableList类却使用底层集合的queals方法和hashCode方法。 -
同步视图
如果由多个线程访问集合,就必须确保集不会被意外地破坏。类库的设计者使用视图机制来确保常规集合的线程安全,而不是实现线程安全的集合类。例如,Collections类的静态synchronizedMap方法可以将任何一个隐射表转换成具有同步访问方法的Map。现在,就可以由多线程访问map对象了。像get和put这类方法都是串行操作的,即在另一个线程调用另一个方法之前,刚才的方法调用必须彻底完成。 - 检查视图
Java SE 5.0增加了一组“检查”视图,用来对泛型类型发生问题时提供调试支持。检查视图可以探测到将错误类型的元素私自带到泛型集合中的问题。下面定义了一个安全列表:List<String> safeStrings = Collections.checkedList(strings,String.class);视图的add方法将检测插入的对象是否属于给定的类,如果不属于给定的类,就立即抛出一个ClassCastException。这样做的好处是错误可以在正确的位置得以报告。
被检查视图受限于虚拟机可以运行的运行时检查。 -
关于可选操作的说明
通常,视图有一些局限性,即可能只可以读、无法改变大小、只支持删除而不支持插入,这些与映射表的键视图情况相同。如果试图进行不恰当的操作,受限制的视图就会抛出一个UnsupportedOperationException。
在集合和迭代器接口的API文档中,许多方法描述为“可选操作”。
是否应该将“可选”方法这一技术扩展到用户的设计中呢?不应该。集合类库的设计者必须解决一组特别严格且又相互冲突的需求。用户希望类库应该易于学习、使用方便,彻底泛型化,面向通用性,同时又与手写算法一样高效。要同时达到所有目标的要求,或者尽量兼顾所有目标完全是不可能的。但是,在自己的编程问题中,很少遇到这样极端的局限性。应该能够找到一种不必依靠极端衡量“可选的”接口操作来解决这类问题的方案。 -
java.util.Collections 1.2
- static < E > Collection unmodifiableCollection(Collection< E > c)
- static < E > List unmodifiableList(List< E > c)
- static < E > Set unmodifiableSet(Set< E > c)
- static < E > Set unmodifiableSet(Set< E > c)
- static < E > SortedSet unmodifiableSortedSet(SortedSet< E > c)
- static < K,V > Map unmodifiableMap(Map< K,V > c)
- static < K,V > SortedMap unmodifiableSortedMap(SortedMap< K,V > c)
构造一个集合视图,其更改器方法将抛出一个UnsupportedOperationException。 - static < E > Collection< E > synchronizedCollection(Collection< E > c)
- static < E > List synchronizedList(List< E > c)
- static < E > Set synchronizedSet(Set< E > c)
- static < E > SortedSet synchronizedSortedSet(SortedSet< E > c)
- static < K,V > Map< K,V > synchronizedMap(Map< E > c)
- static < K,V > SortedMap< K,V > synchronizedSortedMap(SortedMap< E > c)
构造一个集合视图,其方法都是同步的。- static < E > Collection checkedCollection(Collection< E > c,Class< E > elementType)
- static < E > List checkedList(List< E > c,Class< E > elementType)
- static < E > Set checkedSet(Set< E > c,Class< E > elementType)
- static < E > SortedSet checkedSortedSet(SortedSet< E > c,Class< E > elementType)
- static < K,V > Map checkedMap(Map< K,V > c,Class< K > keyType Type,Class< V > valueType)
- static < K,V > SortedMap checkedSortedMap(SortedMap< K,V > c,Class< K > keyType Type,Class< V > valueType)
构造一个集合视图。如果插入一个错误类型的元素,将抛出一个ClassCastException。 - static < E > List< E > nCopies(int n,E value)
- static < E > Set< E > singleton(E value)
构造一个对象视图,它既可以作为一个拥有n个相同元素的不可修改列表,又可以作为一个拥有单个元素的集。
- java.util.Arrays 1.2
- static < E > List< E > asList(E… array)
返回一个数组元素的列表视图,这个数组是可修改的,但其大小不可变。
- static < E > List< E > asList(E… array)
-
java.util.List< E > 1.2
- List< E > subList(int firstIncluded,int firstExcluded)
返回给定位置范围内的所有元素的列表视图。
- List< E > subList(int firstIncluded,int firstExcluded)
-
java.util.SortedSet< E > 1.2
- SortedSet< E > subSet(E firstInclued,E firstExcluded)
- SortedSet< E > headSet(E firstExcluded)
- SortedSet< E > tailSet(E firstInclued)
返回给定范围内的元素视图。
-
java.uril.NavigableSet< E > 6
- NavigableSet< E > subSet(E from, boolean fromIncluded, E to,boolean toIncluded)
- NavigableSet< E > headSet(E to,boolean toIncluded)
- NavigableSet< E > tailSet(E from, boolean fromIncluded)
返回给定返回内的元素视图。boolean 标志确定视图是否包含边界。
-
java.util.SortedMap< K,V > 1.2
- SortedMap< K,V > subMap(K firstIncluded,K firstExcluded)
- SortedMap< K,V > headMap(K firstExcluded)
- SortedMap< K,V > tailMap(K firstIncluded)
返回在给定范围内的键条目的映射表视图。
-
java.util.NavigableMap< K,V > 6
- NavigableMap< K,V > subMap(K from,boolean fromIncluded,K to,boolean toIncluded)
- NavigableMap< K,V > headMap(K from,boolean fromIncluded)
- NavigableMap< K,V > tailMap(K to,boolean toIncluded)
返回在给定范围内的键条目的映射表视图。boolean标志决定视图是否包含边界。
9.3.2 批操作
-
可以使用类库中的批操作(bulk operation)避免频繁地使用迭代器。
-
通过使用一个子范围视图,可以将批处理限制于子列表和子集的操作上。
9.3.3 集合与数组之间的转换
-
如果有一个数组需要转换为集合。Arrays.asList的包装器就可以实现这个目的。
-
由toArray方法返回的数组是一个Object[]数组,无法改变其类型。相反,必须使用另外一种toArray方法,并将其设计为所希望的元素类型且长度为0 的数组。随后返回的数组将与所创建的数组一样。
-
为什么不直接将一个Class对象传递给toArray方法。其原因是这个方法具有“双重职责”,不仅要填充已有的数组(如果足够长),还要创建一个新数组。
9.4 算法
9.4.1 排序与混排
-
Collections类中的sort方法可以对实现了List接口的集合进行排序。这个方法假定列表元素实现了Comparable接口。如果想采用其他方式对列表进行排序,可以将Compaator对象作为第二个参数传递给sort方法。
-
如果想按照降序对列表进行排序,可以使用一种非常方便的静态方法Collections.reverseOrder()。这个方法将返回一个比较器,比较器则返回b.compareTo(a)。这个方法将根据元素类型的compareTo方法给定排序顺序。
-
集合类库中使用的归并算法比快速排序要慢一些,快速排序是通用排序算法的传统选择。但是,归并排序有一个主要的优点:稳定,即不需要交换相同的元素。
-
列表必须是可修改的,但不必是可以改变大小的。下面是有关的术语定义:
- 如果列表支持set方法,则是可修改的。
- 如果列表支持add和remove方法,则是可改变大小的。
- Collections类有一个算法shuffle,其功能与排序刚好相反,即随机地混排列表中元素的顺序。如果提供的列表没有实现RandomAccess接口,shuffle方法将元素复制到数组中,然后打乱数组元素的顺序,最后再将打乱顺序后的元素复制回列表。
- java.util.Collections 1.2
- static < T extends Comparable<? super T> > void sort(List< T > elemets)
- static < T > void sort(List< T > elemets, Comparator<? super T> c)
使用稳定的排序算法,对列表中的元素进行排序。这个算法的时间复杂度是O(n logn),其中n为列表的长度。 - static void shuffle(List<?> elements)
- static void shuffle(List<?> elements,Random r)
随机地打乱列表中的元素。这个算法的时间复杂度是O(n a(n)),n是列表的长度,a(n)是访问元素的平均时间。 - static < T > Comparator< T > reverseOrder()
返回一个比较器,它用与Comparable接口的compareTo方法规定的顺序的逆序对元素进行排序。 - static < T > Comparator< T > reverseOrder(Comparator< T > comp)
返回一个比较器,它用与comp给定的顺序的逆序对元素进行排序。
9.4.2 二分查找
-
Collections类的binarySearch方法实现了二分查找算法。如果binarySearch方法返回的数值大于等于0,则表示匹配对象的索引。如果但会负值,则表示没有匹配的元素,但是,可以利用返回值计算应该将element插入到集合的哪个位置,以保证集合的有序性。插入的位置是(-i-1)。
-
binarySearch方法检查列表参数是否实现了RandomAccess接口。如果实现了这个接口,这个方法将采用二分查找;否则,将采用线性查找。
-
java.util.Collections 1.2
- static < T extends Comparable< ? super T >> int binarySearch(List< T > elements, T key)
- static < T > int binarySearch(List< T > elements, T key,Comparator< ? super T > c)
从有序列表中搜索一个键,如果元素扩展了AbstractSequentialList类,则采用线性查找,否则将采用二分查找。这个方法的时间负责度为O(a(n)logn),n是列表的长度,a(n)是访问一个元素的平均时间。这个方法将返回这个键在列表中的索引,如果在列表中不存在这个键将返回负值i。在这种情况下,应该将这个键插入到列表索引-i-1的位置,以保持列表的有序性。
9.4.3 简单算法
- java.util.Collections 1.2
- static < T extends Comparable<? super T>> T min(Collection< T > elements)
- static < T extends Comparable<? super T>> T max(Collection< T > elements)
- static < T > min(Collection< T > elements,Comparator<? super T> c)
- static < T > max(Collection< T > elements,Comparator<? super T> c)
返回集合中最小的活最大的元素(为清楚起见,参数的边界被简化了)。 - static < T > void copy(List< ? super T > to,List< T > from)
将原列表中的所有元素复制到目标列表的相应位置上。目标列表的长度至少与原列表一样。 - static < T > void fill(List<? super T> to,List< T > from)
将列表中所有位置设置为相同的值。 - static < T > boolean addAll(Collection<? super T> c,T… values) 5.0
将所有的值添加到集合中。如果集合改变了,则返回true。 - static < T > boolean replaceAll(List< T > l,T oldValue,T newValue) 1.4
用newValue取代所有值为oldValue的元素。 - static int indexOfSubList(List<?> l,List<?> s) 1.4
- static int lastIndexOfSubList(List<?> l,List<?> s) 1.4
返回l中第一个或最后一个等于s子列表的索引。如果l中不存在等于s的子列表,则返回-1。例如,l为[s,t,a,r],s为[t,a,r],另个方法都将返回索引1。 - static void swap(List<?> l,int i,int j) 1.4
交换给定偏移量的两个元素。 - static void reverse(List<?> l)
逆置列表中元素的顺序。例如,逆置列表[t,a,r]后将得到列表[r,a,t]。这个方法的时间复杂度为O(n),n为列表的长度。 - static void rotate(List<?> l,int d) 1.4
旋转列表中的元素,将索引i的条目移动到位置(i+d)%l.size()。例如,将列表[t,a,r]旋转移2个位置后得到[a,r,t]。这个方法的时间复杂度为O(n),n为列表的长度。 - static int frequency(Collection<?> c,Object o) 5.0
返回c中与对象o相同的元素个数。 - boolean disjoint(Collection<?> cl,Collection<?> c2) 5.0
如果两个几个没有相同的元素,则返回true。
9.4.4 编写自己的算法
- 如果编写自己的算法(实际上,是以集合作为参数的任何方法),应该尽可能地使用接口,而不要使用具体的实现。
9.5 遗留的集合
9.5.1 Hashtable类
- Hashtable类与HashMap类的作用一样,实际上,它们拥有相同的接口。与Vector类的方法一样。Hashtable的方法也是同步的。如果对同步性或与遗留代码的兼容性没有任何要求,就应该使用HashMap。
9.5.2 枚举
-
遗留集合使用Enumeration接口对元素序列进行遍历。Enumeration接口有两个方法,即hasMoreElements和nextEments。这两个方法与Iterator接口的hasNext方法next方法十分类似。
-
静态方法Collections.enumeration将产生一个枚举对象,枚举集合中的元素。
-
java.util.Enumeration< E > 1.0
- boolean hasMoreElements()
如果还有更多的元素可以查看,则返回true。 - E nextElement()
返回被检测的下一个元素。如果hasMoreElements()返回false,则不要调用这个方法。
- boolean hasMoreElements()
-
java.util.Hashtable< K,V > 1.0
- Enumeration< K > keys()
返回一个遍历散列表中键的枚举对象。 - Enumeration< V > elements()
返回一个遍历散列表中元素的枚举对象。
- Enumeration< K > keys()
-
java.util.Vector< E > 1.0
- Enumeration< E > elements()
返回遍历向量中元素的枚举对象。
- Enumeration< E > elements()
9.5.3 属性映射表
-
属性映射表(property map)是一个类型非常特殊的映射表结构。它有下面3个特性:
- 键与值都是字符串。
- 表可以保存到一个文件中,也可以从文件中加载。
- 使用一个默认的辅助表。
实现属性映射表的Java平台类称为Properties。
属性映射表通常用于程序的特殊配置选项。
-
java.util.Properties 1.0
- Properties()
创建一个空的属性映射表。 - Properties(Properties defaults)
创建一个带有一组默认值的空的属性映射表。 - String getProperty(String key)
获得属性的对应关系;返回与键对应的字符串。如果在映射表中不存在,返回默认表中与这个键对应的字符串。 - String getProperty(String key, String defaultValue)
获得在键没有找到时具有的默认值属性;它将返回与键对应的字符串,如果在映射表中不存在,就返回默认的字符串。 - void load(InputStream in)
从InputStream加载属性映射表。 - void store(OutputStream out,String commentString)
把属性映射表存储到OutputStream。
- Properties()
9.5.4 栈
-
从1.0版开始,标准库中就包含了Stack类,其中有push方法和pop方法。但是,Stack类扩展了Vector类,从理论角度看,Vector类并不太令人满意,它可以让栈使用不属于栈操作的insert和remove方法,即可以在任何方法进行插入或删除操作,而不仅仅是在栈顶。
-
java.util.Stack< E > 1.0
- E push(E item)
将item压入栈并返回item。 - E pop()
弹出并返回栈顶的item。如果栈为空,请不要调用这个方法。 - E peek()
返回栈顶元素,但不弹出。如果栈为空,请不要调用这个方法。
- E push(E item)
9.5.5 位集
-
Java平台的BieSet类用于存放一个位序列(它不是数学上的集,称为位向量或位数组更为合适)。如果需要高效地存放位序列(例如,标志)就可以使用位集。由于位集将位包装在字节里,所以,使用位集要比使用Boolean对象的ArrayList更加高效。
-
BitSet类提供了一个便于读取、设置或清除各个位的接口。使用这个接口可以避免屏蔽和其他麻烦的位操作。如果将这些位存储在int或long变量中就必须进行这些繁琐的操作。
-
java.util.BitSet 1.0
- BitSet(int initialCapacity)
创建一个位集。 - int length()
返回位集的“逻辑长度”,即1加上位集的最高设置位的索引。 - boolean get(int bit)
获得一个位。 - void set(int bit)
设置一个位。 - void clear(int bit)
清除一个位。 - void add(BitSet set)
这个位集与另一个位集进行逻辑“AND”。 - void or(BitSet set)
这个位集与另一个位集进行逻辑“OR”。 - void xor(BitSet set)
这个位集与灵羽阁位集进行逻辑“XOR”。 - void andNot(BitSet set)
清除这个位集中对应另一个位集中设置的所有位。
- BitSet(int initialCapacity)
第十章总结:
10.1 Swing概述
- 在Java 1.0刚刚出现的时候,包含了一个用于基本GUI程序设计的类库,Sun将它称为抽象窗口工具箱(Abstract Window Toolkit,AWT)。基本AWT库采用将处理用户界面元素的任务委派给每个目标平台(Window、Solaris、Macintosh等)的本地GUI工具箱的方式,由本地GUI工具箱负责用户界面元素的创建和动作。在不同的平台上,操作行为存在着一些微妙的差别。有的图形环境(如X11/Motif)并没有像Window或Macintosh这样丰富的用户界面组件集合。在不同平台上的AWT用户界面库中存在着不用的bug。研发人员必须在每一个平台上测试应用程序。
- 在1996年,Netscape创建了一种称为IFC(Internet Foundation Class)的GUI库,它采用了与AWT完全不同的工作方式。它将按钮、菜单这样的用户界面元素绘制在空白窗口上,面对等体只需要创建和绘制窗口。因此,Netscape的IFC逐渐在程序运行的所有平台上的外观和动作都一样。Sun与Netscape合作完善了这种方式,创建了一个名为Swing的用户界面库。Swing可作为Java 1.1的扩展部分使用,现已成为Java SE 1.2标准库的一部分。
- Swing没有完全替代SWT,而是基于AWT架构之上。Swing仅仅提供了能力更加强大的用户界面组件。尤其在采用Swing编写的程序中,还需要使用基本的AWT处理事件。从现在开始,Swing是指“被绘制的”用户界面类;AWT是指像事件处理这样的窗口工具箱的底层机制。
- 在用户屏幕上显示基于Swing用户界面的元素要比显示AWT的基于对等体组件的速度慢一些。鉴于以往的经验,对于任何一台现代的计算机来说,微小的速度差别无房大碍。另外,由于下列几点无法抗拒的原因,人们选择Swing:
- Swing拥有一个丰富、便捷的用户界面元素集合。
- Swing对底层平台依赖的很少,因此与平台相关的bug很少。
- Swing给予不用平台的用户一致的感觉。
10.2 创建框架
- 在Java中,顶层窗口(就是没有包含在其他窗口中的窗口)被称为框架(frame)。在AWT库中有一个称为Frame的类,用于描述顶层窗口。这个类的Swing版本名为JFrame,它扩展于Frame类。JFrame是极少数几个不绘制在画布上的Swing组件之一。因此,它的修饰部件(按钮、标题栏、图标等)由用户的窗口系统绘制,而不是由Swing绘制。
- 所有的Swing组件必须由时间分派线程(event dispatch thread)进行配置,线程将鼠标点击和按键控制转移到用户接口组件。
- 许多Swing程序并没有在事件分配线程中初始化用户界面。在主线程中完成初始化时通常采用的方式。
10.3 框架定位
- JFrame类本身包含若干个改变框架外观的方法。当然,通过继承,从JFrame的各个超类中继承了许多用于处理框架大小和位置的方法。其中最重要的有下面几个:
- setLocation和setBounds方法用于设置框架的位置。
- setIconImages用于告诉窗口系统在标题栏、任务切换窗口等位置显示哪个图标。
- setTitle用于该表标题栏的文字。
- setResizable利用一个boolean值确定框架的大小是否允许用户改变。
- Component类找你哥的setLocation方法是重定位组件的一个方法。Complement中的setBounds方法可以实现一步重定位组件大小和位置的操作。
- 对于框架来说,setLocation和setBounds中的坐标均相对于整个屏幕。
10.3.1 框架属性
- 从概念上讲,title是框架的一个属性。当设置这个属性时,希望这个标题能够改变用户屏幕上的显示。当获取这个属性时,希望能够返回已经设置的属性值。
- 针对get/set约定有一个例外:对于类型为boolean的属性,获取方法由is开头。
10.3.2 确保合适的框架大小
- 要记住:如果没有明确地指定框架的大小,所有框架的默认值为0x0像素。
- 为了得到屏幕的大小,需要按照下列步骤操作。调用Toolkit类的静态方法getDefaultToolkit得到一个Toolkit对象(Toolkit类包含很多与本地窗口系统打交道的方法)。然后,调用getScreenSize方法,这个方法以Dimension对象的形式返回屏幕的大小。Dimension对象同时用公有实例变量width和height保存着屏幕的宽度和高度。
- 下面是为了处理框架给予的一些提示:
- 如果框架中只包含标准的组件,如按钮和文本框,那么可以通过调用pack方法设置框架大小。框架将被设置为刚好能够防止所有组件的大小。在通常情况下,将程序的主框架尺寸设置为最大。正如Java SE 1.4,可以通过调用下列方法将框架设置为最大。
frame.setExtendedState(Frame.MAXINIZED_BOTH); - 牢记用户定位应用程序的框架位置、重置框架大小,并且在应用程序再次启动时恢复这些内容是一个不错的想法。
- 如果缩写一个使用多个显示屏幕的应用程序,应该利用GraphicsEnvironment和Graphics Device类获得显示屏幕的大小。
- GraphicsDevice类允许在全屏模式下执行应用程序。
- java.awt.Component 1.0
- boolean isVisible()
- void setVisible(boolean b)
获取或设置visible属性。组件最初是可见的,但JFrame这样的顶层组件例外。 - void setSize(int width,int height) 1.1
使用给定的宽度和高度,重新设置组件的大小。 - void setLocation(int x,int y) 1.1
将组件移到一个新的位置上。如果这个组件不是顶层组件,x和y坐标(或者p.x和p.y)是容器坐标;否则是屏幕坐标(例如:aJFram)。 - void setBounds(int x,int y,int width,int height) 1.1
移动并重新设置组件的大小。 - Dimension getSize() 1.1
- void setSize(Dimension d) 1.1
获取或设置当前组件的size属性。
- java.awt.Window 1.0
- void toFront()
将这个窗口显示在其他窗口前面。 - void toBack()
将这个窗口移到桌面窗口栈的后面,并重新排列所有的可见窗口。 - boolean isLocationByPlatform() 5.0
- void setLocationByPlatform(boolean b) 5.0
获取或设置locationByPlatform属性。这个属性在窗口显示之前被设置,由平台选择一个合适的位置。
- void toFront()
- java.awt.Frame 1.0
- boolean isResizable()
- void setResizable(boolean b)
获取或设置resizable属性。这个属性设置后,用户可以重新设置框架的大小。 - String getTitle()
- void setTitle(String s)
获取或设置title属性,这个属性确定框架标题栏中的文字。 - Image getIconImage()
- void setIconImage(Image image)
获取或设置iconImage属性,这个属性确定框架的图标。窗口系统可能会将图标作为框架装饰或其他部位的一部分显示。 - boolean isUndecorated() 1.4
- void setUndecorated(boolean b) 1.4
获取或设置undecorated属性。这个属性设置后,框架显示中将没有标题栏或关闭按钮这样的装饰。早框架显示之前,必须调用这个方法。 - int getExtendedState() 1.4
- void setExtendedState(int state) 1.4
获取或设置窗口状态。状态是下列值之一。Frame.NORNAL、Frame.ICONIFIED、Frame.MAXIMIZED_HORIZ、Frame.MAXIMIZED_VERT、Frame.MAXIMIZED_BOTH。
- java.awt.Toolkit 1.0
- static Toolkit getDefaultToolkit()
返回默认的工具箱。 - Dimension getDcreenSize()
返回用户屏幕的尺寸。
- static Toolkit getDefaultToolkit()
- javax.swing.ImageIcon 1.2
- ImageIcon(String filename)
构造一个图标,其图像存储在一个文件中。 - Image getImage()
获取该图标的图像。
- ImageIcon(String filename)
10.4 在组件中显示信息
- 在JFrame中有四层面板。其中的根面板、层级面板和玻璃面板人们并不太关心;它们是用来组织菜单栏和内容窗格以及实现观感的。Swing程序员最关心的是内容窗格(content pane)。在设计框架的时候,将所有的组件添加到内容窗格中。
- 绘制一个组件,需要定义一个扩展JComponent的类,并覆盖其中的paintComponent方法。paintComponent方法有一个Graphics类型的参数,这个参数保存着用于绘制图像和文本的设置。在Java中,所有的绘制都必须使用Graphics对象,其中包含了绘制图案、图像和文本的方法。
- 无论何种原因,只要窗口需要重新绘图,事件处理器就会通告组件,从而引发执行所有组件的paintComponent方法。
- 一定不要自己调用paintComponent方法。在应用程序需要重新绘图的时候,这个方法将被在佛那个地调用,不要人为的干预这个自动的处理过程。
- 如果需要强制刷新屏幕,就需要调用repaint方法,而不是paintComponent方法。它将引发采用相应配置的Graphics对象调用所有组件的paintComponent方法。
- 在框架中添加一个或多个组件时,如果只想使用它们的首选大小,可以调用pack方法而不是setSize方法。
- 有些程序员更喜欢扩展JPanel,而不是JComponent。JPanel是一个可以包含其他组件的容器(container),但同样也可以在其上面进行绘制。有一点不同之处是,面板不透明,这意味着需要在面板的边界内绘制所有的像素。最容易实现的方法是,在每个面板子类的paintComponent方法中调用super.paintComponent来用背景色绘制面板。
- javax.swing.JFrame 1.2
- Container getContentPane()
返回这个JFrame的内容窗格对象。 - Component add(Component c)
将一个给定的组件添加到改框架的内容窗格中(在Java SE 5.0以前的版本中,这个方法将抛出一个异常)。
- Container getContentPane()
- java.awt.Component 1.0
- void repaint()
“尽可能快地”重新绘制组件。 - Dimension getPreferredSize()
要覆盖这个方法,发挥这个组件的首选大小。
- void repaint()
- javax.swing.JComponent 1.2
- void paintComponent(Grphics g)
覆盖这个方法来描述应该如何绘制自己的组件。
- void paintComponent(Grphics g)
- java.awt.Window 1.0
- void pack()
调整窗口大小,要考虑到其组件的首选大小。
- void pack()
10.5 处理2D图形
- Graohics类包含绘制直线、矩形和椭圆等方法。但是,这些绘制图形的操作能力非常有限。例如,不能改变先的粗细,不能旋转这个图形。
- Java SE 1.2引入了Java 2D库,这个库实现了一组功能强大的图形操作。
- 要想使用Java 2D库绘制图形,需要获得一个Graphics2D类对象。这个类是Graphics类的子类。自从Java SE 2版本依赖,paintComponent方法就会自动地获取一个Graphics2D类对象,只需要进行一次类型转换就可以了。
- Java 2D库采用面向对象的方式将几何图形组织起来。包括描述直线、矩形的椭圆的类:LINE2D、Rectangle2D、Ellipse2D这些类都实现了Shape接口。
- 要想绘制图形,首先要创建一个实现了Shape接口的类的对象,然后调用Graphics2D类中的draw方法。
- 使用Java 2D图形或许会增加一些复杂度。在1.0的绘制方法中,采用的是整型像素坐标,而Java 2D图形采用的是浮点坐标。在很多情况下,用户可以使用更有意义的形式(例如,微米或英寸)指定图形的坐标,然后再将其转换成像素,这样做很方便。在Java 2D库中,内部的很多浮点极端都采用单精度float。毕竟,几何计算的最终目的是要设置屏幕或打印机的像素,所以单精度完全可以满足要求了。只要舍入误差限制在一个像素的范围内,视觉效果就不会受到任何影响。另外,在某些平台上,float计算的速度比较快,并且只占据double值的一般存储量。
- 由于后缀和类型转换都有点麻烦,所以2D库的设计者决定为每个图形类提供两个版本:一个是为那些节省空间的程序员提供的float类型的坐标;另一个是为那些懒惰的程序员提供的double类型的坐标。
- Rectangle2D方法的参数和返回值均为double类型。
- 直接使用Double图形类可以避免处理float类型的值,然后如果需要创建上千个图形对象,还是应该考虑使用Float类,这样可以节省存储空间。
- Rectangle2D和Ellipse2D类都是由公共超类RectangularShape继承来的。
- RectangularShape类定义了20多个有关图形操作的通用方法,其中比较常用的方法有getWidth、getHeight、getCenterX、getCenterY等。
- 从Java 1.0遗留下来的两个类也被放置在图形类的继承层次中。它们是Rectangle和Point类,分别扩展于Rectangle2D和Point2D类,并用整型坐标存储矩形和点。
- Rectangle2D和Ellipse2D对象很容易构造,需要给出
- 左上角的x和y坐标。
- 宽和高。
- java.awt.geom.RectangularShape 1.2
- double getCenterX()
- double getCenterY()
- double getMinX()
- double getMinY()
- double getMaxX()
- double getMaxY()
返回闭合矩形的中心,以及最小、最大x和y坐标值。 - double getWidth()
- double getHeight()
返回闭合矩形的宽和高。 - double getX()
- double getY()
返回闭合矩形左上角的x和y坐标。
- java.awt.geon.Rectengle2D.Double 1.2
- Rectangle2D.Double(double x,double y,double w,double h)
利用给定的左上角、宽和高,构造一个矩形。
- Rectangle2D.Double(double x,double y,double w,double h)
- java.awt.geom.Rectangle2D.Float 1.2
- Rectangle2D.Float(float x,float y,float w,float h)
利用给定的左上角、宽和高,构造一个矩形。
- Rectangle2D.Float(float x,float y,float w,float h)
- java.awt.geom.Ellipse2D.Double 1.2
- Ellopse2D.Double(double x,double y,double w,double h)
利用给定的左上角、宽和高的外接矩形,构造一个椭圆。
- Ellopse2D.Double(double x,double y,double w,double h)
- java.awt.geom.Point2D.Double 1.2
- Point2D.Double(double x,double y)
利用给定坐标构造一个点。
- Point2D.Double(double x,double y)
- java.awt.geom.Line2D.Double 1.2
- Line2D.Double(Point2D start,Point2D end)
- Line2D.Double(double startX,double startY,double endX,double endY)
使用给定的起点和终点,构造一条直线。
10.6 使用颜色
- 使用Graphics2D类的setPaint方法可以为图形环境上的所有后续的绘制操作选择颜色。
- 只需要将调用dra替换为调用fill就可以用一种颜色填充一个封闭图形的内部。
- 要想绘制多种颜色,就需要按照选择颜色、绘制图形、再选择另外一种颜色、再绘制图形的过程实施。
- fill方法会在右侧和下方少绘制一个像素。
- Color类用于定义颜色。在java.awt.Color类中提供了13个预定义的常量,它们分别表示13种标准颜色。BLANK、BLUE、CYAN、DARK_GRAY、GRAY、LIGHT_GRAY、MAGENTA、ORANGE、PINK、RED、WHITE、WELLOW。
- 可以通过提供红、绿和蓝三色成分来创建一个Color对象,以达到定制颜色的目的。
- 要想设置背景颜色,就需要使用Component类中的setBackground方法。Component类是JComponent类的祖先。
- setForeground方法是用来设定在组件上进行绘制时使用的默认颜色。
- Color类中的brighter()方法和darker()方法的功能,它们分别加亮或变暗当前的颜色。使用brighter方法也是加亮条目的好办法。实际上,brighter()只微微地加亮一点。要达到耀眼的效果,需要调用三次这个方法:
c.brighter().brighter().brighter()。 - java在SystemColor类中与定义了很多颜色的名字。在这个类中的常量,封装了用户系统的各个元素的颜色。
- java.awt.Color 1.0
- Color(int r,int g,int b)
创建一个颜色对象。
参数: r 红色值(0-255)、g 绿色值(0-255)、b 蓝色值(0-255)。
- Color(int r,int g,int b)
- java.awt.Graphics 1.0
- Color getColor()
- void setColor(Color c)
获取或改变当前的颜色。所有后续的绘图操作都是用这个新颜色。
参数:c 新颜色
- java.awt.Graphics2D 1.2
- Paint getPaint()
- void setPaint(Paint p)
获取或设置这个图形环境的绘制属性。Color类实现了Paint接口。因此,可以使用这个方法将绘制属性设置为纯色。 - void fill(Shape s)
用当前的颜料填充该图形。
- java.awt.Component 1.0
- Color getBackground()
- void setBackground(Color c)
获取或设置背景颜色。
参数:c 新背景颜色 - Color getForeground()
- void setForeground(Color c)
获取或设置前景颜色。
参数:c 新前景颜色。
10.7 文本使用特殊字体
- 可以通过字体名(font dace name)指定一个字体。字体名由”Helvetica”这样的字体家族名(font family name)和一个可选的”Bold”后缀组成。
- 要想知道某台特定计算机上允许使用的字体,就需要调用GraphicsEnvironment类中的getAvailableFontFamilyNames方法。这个方法将返回一个字符型数组,其中包了所有可用的字体名。GraphicsEnvironment类描述了用户系统的图形环境,为了得到这个类的对象,需要调用静态的getLocalGraphicsEnvironment方法。
- 点数目是排版中普遍使用的表示字体大小的单位,每英寸包含72个点。
- 字体风格值:Font.PLAIN、Font.BOLD、Font.ITALIC、Font.BOLD+Font.ITALIC。
- 要想得到屏幕设备字体属性的描述对象,需要调用Graphics2D类中的getFontRenderContext方法。它将返回一个FontRenderContext类对象。
- 基线(baseline)是一条虚构的线。上坡度(ascent)是从基线到坡顶(ascenter)的距离。下坡度(descent)是从基线到坡顶(descenter)的距离。
- 行间距(leading)是某一行的坡底与其下一行的坡顶之间的空隙。字体的高度是连续两个基线之间的距离,它等于下坡度+行间距+上坡度。
- getStringBounds方法返回的矩形宽度是字符串水平方向的宽度。矩形的高度是上坡度、下坡度、行间距的总和,如果需要知道下坡度或行间距,可以使用Font类的getLineMetrics方法,这个方法将返回一个LineMetrics类对象。
- 为了能够获得中央的位置,可以使用getWidth()得到组件的宽度。使用bounds.getWidth()得到字符串的宽度。前者减去后者就是两侧应该剩余的空间,因此,每侧剩余的空间应该是这个差值的一般。高度也一样。
- java.awt.Font 1.0
- Font(String name,int style,int size)
创建一个字体对象。
参数: name 字体名。不是字体名(例如,“Helvetica Bold”),就是逻辑字体名(例如,“Serif”、“SansSerif”)。style 字体风格(Font.PLAIN、Font.BOLD、Font.ITALIC或Font.BOLD+Font.ITALIC)。size 字体大小(例如,12)。 - String getFontName()
返回字体名,例如,“Helvetica Bold”。 - String getFamily()
返回字体家族名,例如,“Helvetica”。 - String getName()
如果采用逻辑字体名创建字体,将返回逻辑字体,例如,“SansSerif”;否则,返回字体名。 - Rectangle2D getStringBounds(String s,FontRenderContext context) 1.2
返回包围这个字符串的矩形。矩形的起点为基线。矩形顶端的y坐标等于上坡度的负值。矩形的高度等于上坡度、下坡地和行间距之和。宽度等于字符串的宽度。 - LineMetrics getLineMetrics(String s,FontRenderContext context) 1.2
返回测定字符串宽度的一个线性metrics对象。 - Font deriveFont(int style) 1.2
- Font deriveFont(float size) 1.2
- Font deriveFont(int style,float size) 1.2
返回一个新字体,除给定大小和字体风格外,其余与原字体一样。
- Font(String name,int style,int size)
- java.awt.font.LineMetrics 1.2
- float getAscent()
返回字体的上坡度—从基线到大写字母顶端的距离。 - float getDescent()
返回字体的下坡度—从基线到坡底的距离。 - float getLeading()
返回字体的行间距—从一行文本底端到下一行文本顶端之间的空隙。 - float getHeight()
返回字体的总高度—两条文本基线之间的距离(下坡度+行间距+上坡度)。
- float getAscent()
- java.awt.Graphics 1.0
- Font getFont()
- void setFont(Font font)
获取或设置当前的字体。这种字体将被应用于后续的文本绘制操作中。
参数:font 一种字体。- void drawString(String str,int x,int y)
参数:str 将要绘制的字符串。x 字符串开始的x坐标。y 字符串基线的y坐标。
- void drawString(String str,int x,int y)
- java.awt.Graphics 1.2
- FontRenderContext getFontRenderContext()
返回这个图形文本中,指定字体特征的字体绘制环境。 - void drawString(String str,float x,float y)
采用当前的字体和颜色绘制一个字符串。
参数:str 将要绘制的字符串。 x 字符串开始的x坐标。y 字符串基线的y坐标。
- FontRenderContext getFontRenderContext()
- javax.swing.JComponent 1.2
- FontMetrics getFontMetrics(Font f) 5.0
获取给定字体的度量。FontMetrics类是LineMetrics类的早先版。
- FontMetrics getFontMetrics(Font f) 5.0
- java.awt.FontMetrics 1.0
- FontRenderContext getFontRenderContext() 1.2
返回字体的字体绘制环境。
- FontRenderContext getFontRenderContext() 1.2
10.8 显示图像
- 使用Graphics类的drawImage方法将图像显示出来。
- java.awt.Graphics 1.0
- boolean drawImage(Image img,int x,int y,ImageObserver observer)
绘制一副非比例图像。注意:这个调用可能会在图像还没有绘制完毕就返回。
参数:img 将要绘制的图像。x 左上角的x坐标。y 左上角的y坐标。observer 绘制进程中以通告为目的的对象(可能为null)。 - boolean drawImage(Image img,int x,int y,int width,int height,ImageObserver observer)
绘制一副比例图像。系统按照比例将图像放入给定宽和高的区域。注意:这个调用可能会在图像还没有绘制完毕就返回。
参数:img 将要绘制的图像。x 左上角的x坐标。y 左上角的y坐标。width 描述图像的宽度。height 描述图像的高度。observer 绘制进程中以通告为目的的对象(可能为null)。 - void copyArea(int x,int y,int width,int height,int dx,int dy)
拷贝屏幕的一块区域。
参数:x 原始区域左上角的x坐标。y 原始区域左上角的y坐标。width 原始区域的宽度。 height 原始区域的高度。dx 原始区域到目的区域的水平距离。dy 原始区域到目的区域的数值距离。
- boolean drawImage(Image img,int x,int y,ImageObserver observer)
二:实验部分。
1、实验目的与要求
(1) 掌握Vetor、Stack、Hashtable三个类的用途及常用API;
(2) 了解java集合框架体系组成;
(3) 掌握ArrayList、LinkList两个类的用途及常用API。
(4) 了解HashSet类、TreeSet类的用途及常用API。
(5)了解HashMap、TreeMap两个类的用途及常用API;
(6) 结对编程(Pair programming)练习,体验程序开发中的两人合作。
2、实验内容和步骤
实验1: 导入第9章示例程序,测试程序并进行代码注释。
测试程序1:
l 使用JDK命令运行编辑、运行以下三个示例程序,结合运行结果理解程序;
l 掌握Vetor、Stack、Hashtable三个类的用途及常用API。
示例程序1:
//示例程序1
import java.util.Vector;//实现自动增长的对象数组
class Cat {
private int catNumber;
Cat(int i) {
catNumber = i;
}
void print() {
System.out.println("Cat #" + catNumber);
}
}
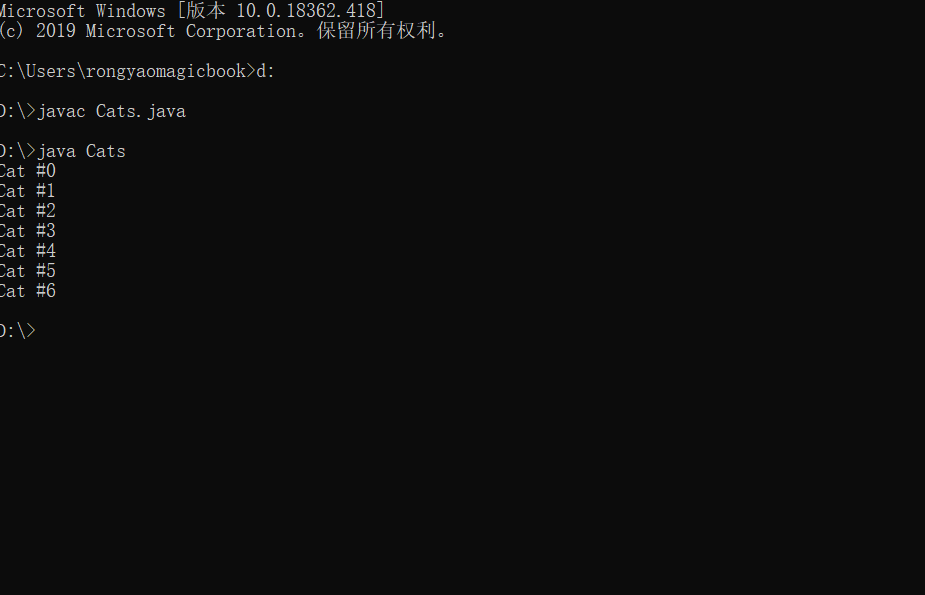
public class Cats{
public static void main(String[] args){
Vector<Cat> cats= new Vector<Cat>();
for(int i=0; i<7; i++)
cats.addElement(new Cat(i));
for(int i=0; i<cats.size(); i++)
(cats.elementAt(i)).print();
}
}
程序运行结果如下:
package JavaTest;
import java.util.*;
public class S //栈(先进后出)
{
static String[] months = {"金","银","铜","铁"};
public static void main(String[] args) {
Stack<String> stk = new Stack<String>();
for (int i = 0; i < months.length; i++)
stk.push(months[i]);//进栈
System.out.println(stk);
System.out.println("element 2=" + stk.elementAt(2));
while (!stk.empty())
System.out.println(stk.pop());//输出出栈元素
}
}
程序运行结果如下:
示例程序3:
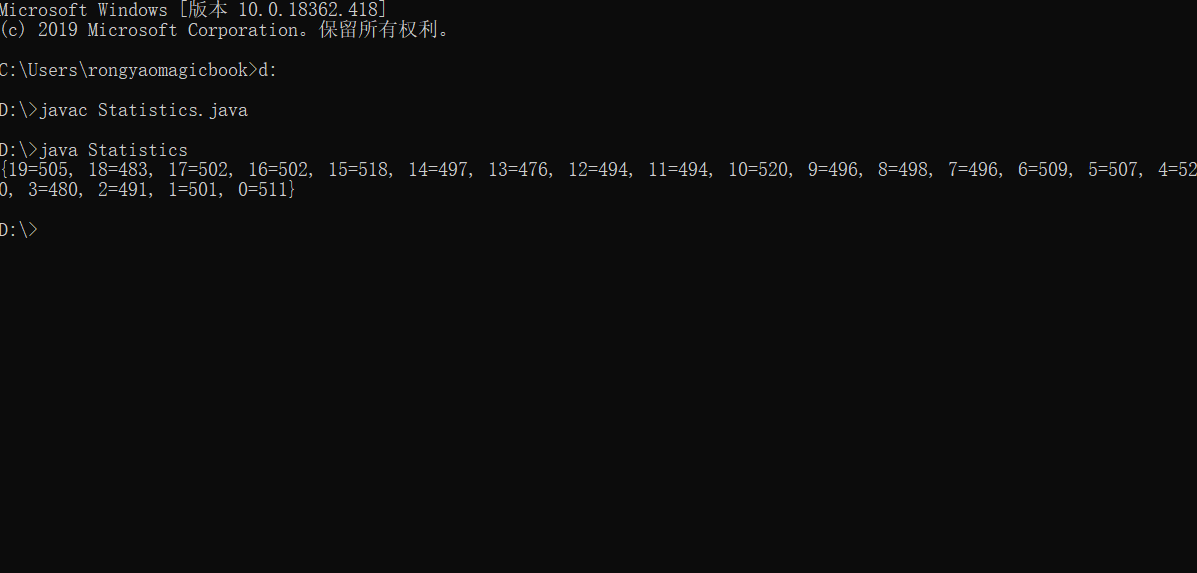
import java.util.*; class Counter { int i = 1;//不加权限修饰符:friendly型 public String toString() //把其他类型的数据转为字符串类型的数据 { return Integer.toString(i); } } public class Statistics { public static void main(String[] args) { Hashtable ht = new Hashtable(); for (int i = 0; i < 10000; i++) { Integer r = new Integer((int) (Math.random() * 20));//生成0到20(不包括20)的整型随机数 if (ht.containsKey(r))//判断r是否是哈希表中一个元素的键值 ((Counter) ht.get(r)).i++;//通过get方法获得其值 else ht.put(r, new Counter());//ht不存在 } System.out.println(ht); } }
程序运行结果如下:

测试程序2:
使用JDK命令编辑运行ArrayListDemo和LinkedListDemo两个程序,结合程序运行结果理解程序;
ArrayListDemo:
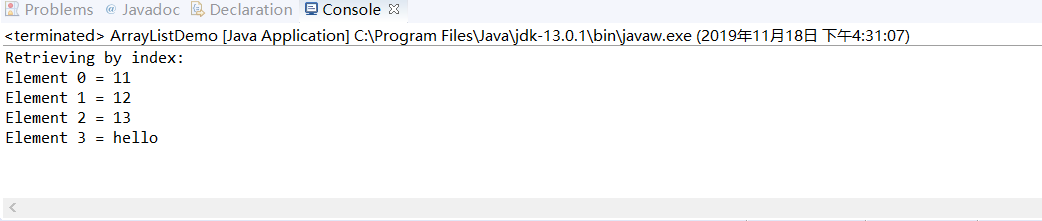
import java.util.*; public class ArrayListDemo//ArrayList使用了数组的实现 { public static void main(String[] argv) { ArrayList al = new ArrayList(); //在ArrayList中添加大量元素 al.add(new Integer(11)); al.add(new Integer(12)); al.add(new Integer(13)); al.add(new String("hello"));//下标从0开始,添加4个元素 // First print them out using a for loop. System.out.println("Retrieving by index:"); for (int i = 0; i < al.size(); i++) { System.out.println("Element " + i + " = " + al.get(i)); } } }
程序运行结果如下:
LinkedListDemo
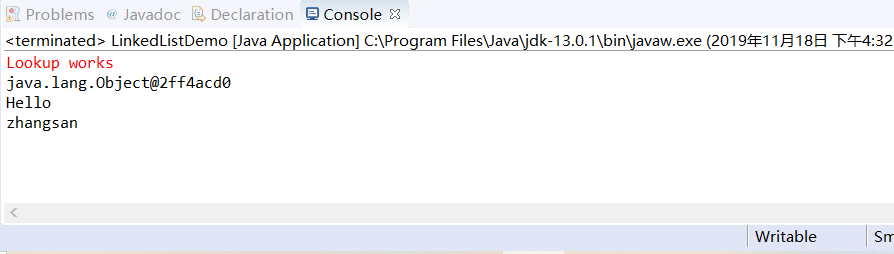
import java.util.*; public class LinkedListDemo { public static void main(String[] argv) { LinkedList l = new LinkedList(); l.add(new Object()); l.add("Hello"); l.add("zhangsan"); ListIterator li = l.listIterator(0); while (li.hasNext()) System.out.println(li.next()); if (l.indexOf("Hello") < 0) System.err.println("Lookup does not work"); else System.err.println("Lookup works"); } }
程序运行结果如下:
程序运行结果如下:
l 在Elipse环境下编辑运行调试教材360页程序9-1,结合程序运行结果理解程序;
l 掌握ArrayList、LinkList两个类的用途及常用API。
程序如下:
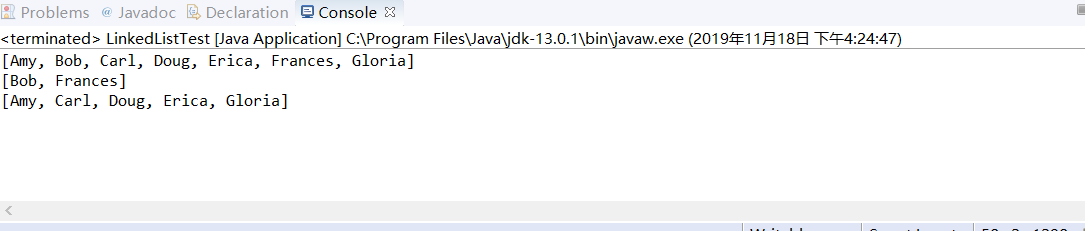
import java.util.*; /** * This program demonstrates operations on linked lists. * @version 1.11 2012-01-26 * @author Cay Horstmann */ public class LinkedListTest { public static void main(String[] args) { //创建a和b两个链表 List<String> a = new LinkedList<>();//泛型 a.add("Amy"); a.add("Carl"); a.add("Erica"); List<String> b = new LinkedList<>();//泛型 b.add("Bob"); b.add("Doug"); b.add("Frances"); b.add("Gloria"); //合并a和b中的词 ListIterator<String> aIter = a.listIterator(); Iterator<String> bIter = b.iterator(); while (bIter.hasNext()) { if (aIter.hasNext()) aIter.next(); aIter.add(bIter.next()); } System.out.println(a); //从第二个链表中每隔一个元素删除一个元素 bIter = b.iterator(); while (bIter.hasNext()) { bIter.next(); // skip one element if (bIter.hasNext()) { bIter.next(); // skip next element bIter.remove(); // remove that element } } System.out.println(b); // bulk operation: remove all words in b from a a.removeAll(b); System.out.println(a);//通过AbstractCollection类中的toString方法打印出链表a中的所有元素 } }
程序运行结果如下:
实验2:导入第10章示例程序,测试程序并进行代码注释。
测试程序1:
l 运行下列程序,观察程序运行结果。
import javax.swing.*; public class SimpleFrameTest { public static void main(String[] args) { JFrame frame = new JFrame(); //创建一个frame类对象 frame.setBounds(0, 0,300, 200);//定义坐标以及宽度和高度 frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);//窗口关闭操作 frame.setVisible(true);//窗口是否可见 } }
程序运行结果如下:
l 在elipse IDE中调试运行教材407页程序10-1,结合程序运行结果理解程序;与上面程序对比,思考异同;
l 掌握空框架创建方法;
l 了解主线程与事件分派线程概念;
l 掌握GUI顶层窗口创建技术。
package simpleFrame; import java.awt.*; import javax.swing.*; /** * @version 1.33 2015-05-12 * @author Cay Horstmann */ public class SimpleFrameTest { public static void main(String[] args) { EventQueue.invokeLater(() ->//lambda表达式:通过线程开启一个队列 { SimpleFrame frame = new SimpleFrame();//创建一个类对象 frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);//设置对象点击关闭操作 frame.setVisible(true);//页面是否可见 }); } } class SimpleFrame extends JFrame { private static final int DEFAULT_WIDTH = 300; private static final int DEFAULT_HEIGHT = 200; public SimpleFrame()//构造器 { setSize(DEFAULT_WIDTH, DEFAULT_HEIGHT);//设置大小 } }
程序运行结果如下:
测试程序2:
l 在elipse IDE中调试运行教材412页程序10-2,结合程序运行结果理解程序;
掌握确定框架常用属性的设置方法。
package simpleFrame; import java.awt.*; import javax.swing.*; /** * @version 1.34 2015-06-16 * @author Cay Horstmann */ public class SizedFrameTest { public static void main(String[] args) { EventQueue.invokeLater(() ->//lambda表达式:通过线程开启一个队列 { JFrame frame = new SizedFrame();//创建一个frame类对象 frame.setTitle("SizedFrame");//设置标题 frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);//关闭操作 frame.setVisible(true);//设置可见性 }); } } class SizedFrame extends JFrame//继承 { public SizedFrame()//构造器 { //得到屏幕维度 Toolkit kit = Toolkit.getDefaultToolkit();//生成Toolkit对象 Dimension screenSize = kit.getScreenSize(); int screenHeight = screenSize.height; int screenWidth = screenSize.width; // set frame width, height and let platform pick screen location setSize(screenWidth / 2, screenHeight / 2);//尺寸大小 setLocationByPlatform(true); // set frame icon Image img = new ImageIcon("icon.gif").getImage(); setIconImage(img); } }
程序运行结果如下:
测试程序3:
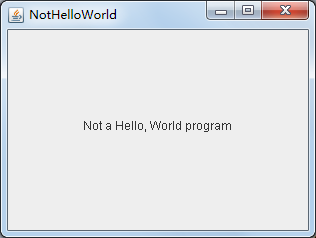
l 在elipse IDE中调试运行教材418页程序10-3,结合运行结果理解程序;
l 掌握在框架中添加组件;
掌握自定义组件的用法。
package simpleFrame; import javax.swing.*; import java.awt.*; /** * @version 1.33 2015-05-12 * @author Cay Horstmann */ public class NotHelloWorld { public static void main(String[] args) { EventQueue.invokeLater(() ->//lambda表达式:通过线程开启一个队列 { JFrame frame = new NotHelloWorldFrame(); frame.setTitle("NotHelloWorld");//标题 frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE); frame.setVisible(true); }); } } /** * A frame that contains a message panel */ class NotHelloWorldFrame extends JFrame//继承 { public NotHelloWorldFrame()//构造器 { add(new NotHelloWorldComponent());//添加窗口 pack(); } } /** * A component that displays a message. */ class NotHelloWorldComponent extends JComponent { public static final int MESSAGE_X = 75; public static final int MESSAGE_Y = 100; private static final int DEFAULT_WIDTH = 300; private static final int DEFAULT_HEIGHT = 200; public void paintComponent(Graphics g)//绘图 { g.drawString("Not a Hello, World program", MESSAGE_X, MESSAGE_Y); } public Dimension getPreferredSize() { return new Dimension(DEFAULT_WIDTH, DEFAULT_HEIGHT); } }
三:实验总结:
通过本周学习,我进一步复习了一些有关数据结构的知识,另外初步了解了java集合类,也了解了Vector类,Stack类以及Hashtable类。除此以外,此次实验第一次采用结对编程的方法,通过和合作伙伴互相运行程序,相互讨论交流,从中学到了很多东西。希望以后多采取这种方法,在合作中互相学习进步。另外,本周还学习了 图形用户界面,即以图形的方式呈现的用户界面。在学习理论知识时初步了解了绘制图形的常用API以及如何设置字体和颜色,实验课上通过运行课本上的程序,进一步了解了图形用户界面。在老师和助教的讲解下,对此有了更深的掌握。在PTA平台上做Java练习题时,因为只是选择和判断,都是一些概念性的知识,觉得也不是很难。可能就是有细微的地方,因为听课时的粗心没有掌握。在后面的学习中,除了多练习代码,我还会多翻书去记下一些细节和概念。