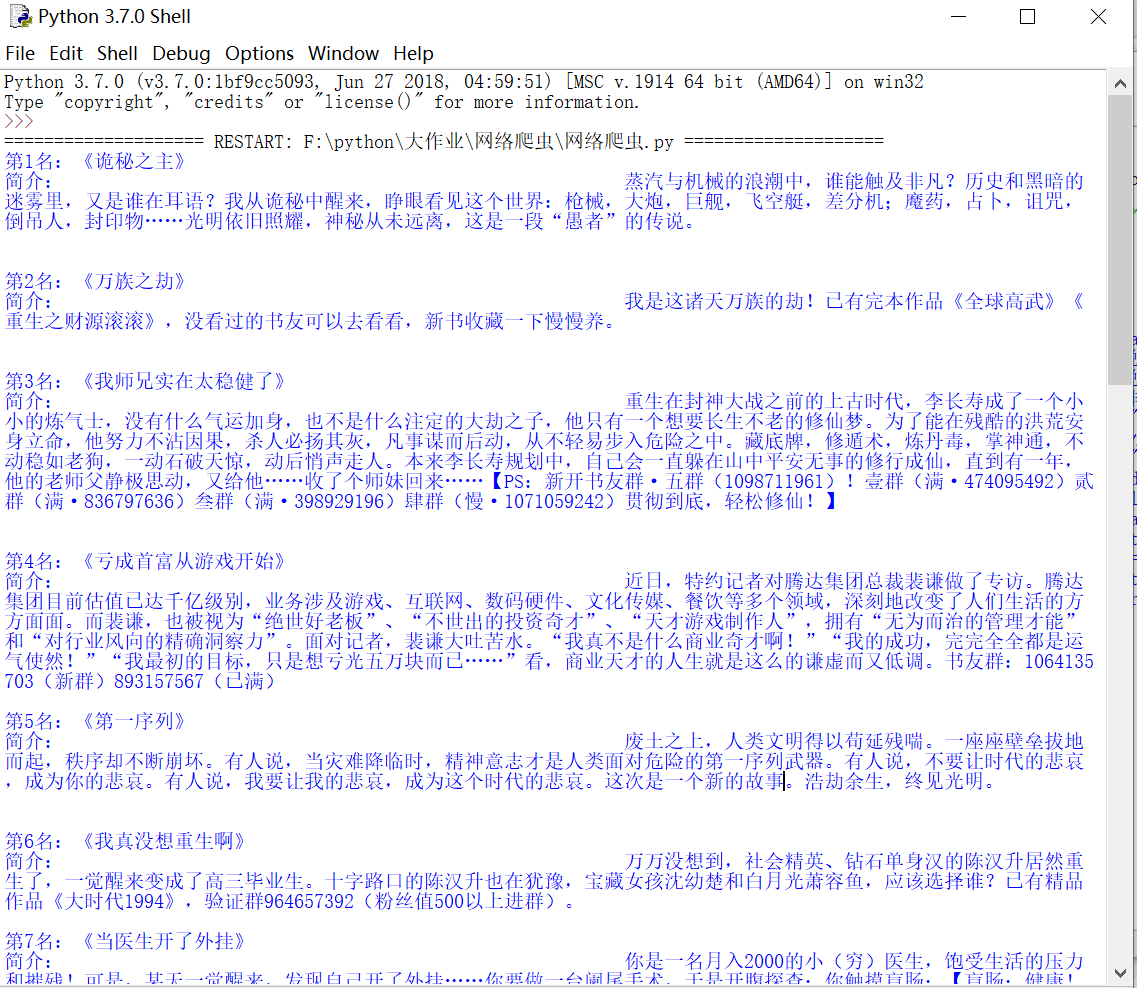
爬取起点月票榜
一、实现过程:
1、找到一个感兴趣的网页——起点中文网的月票排行榜(https://www.qidian.com/rank/yuepiao),并尝试爬取:

2、分析网页源代码,思考提取数据方法

书名在h4标签,简介在p标签
利用soup.find_all(name, attrs, recursive, string, **kwargs)提取书名及简介
3、整理思路,写代码
二、源代码
import requests from bs4 import BeautifulSoup import bs4 url="https://www.qidian.com/rank/yuepiao" def getHtml(url): r=requests.get(url) r.raise_for_status() r.encoding=r.apparent_encoding return r.text[26000:100000] def fillList(html): l1,l2 = [],[] soup = BeautifulSoup(html,"html.parser") for i in soup.find_all('h4'): l1.append(str(i.string)) for tag in soup.find_all('p',"intro"): s=str(tag.string) s.replace(" "," ") l2.append(s) return l1,l2 def printList(l1,l2): n1,n2 = len(l1),len(l2) n=max(n1,n2) for i in range(n): print("第{}名:《{}》".format(i+1,l1[i])) print("简介:{}".format(l2[i])) print("") def main(): html=getHtml(url) l1,l2=fillList(html) printList(l1,l2) main()
三、结果